







最近读了两篇文章(见文末),核心是如何不使用DL的方法来得到效果不差的文本和句子embedding。第一篇文章核心是提出了简单但有效的句子和文本级的embedding策略,无需使用DL技术,只需要词向量结果和一些线性运算即可。第二篇文章在第一篇的基础上增加了对词序的支持。
句子和文本embedding
Word2vec和GloVe,再加上对PMI矩阵的直接分解等方法基本奠定了词向量表示的工业事实标准,但是如何得到更长文本,如句子和文章的向量表示,还是一个处于活跃研究的问题。现在行业中的一些方法多数是基于DL模型的,例如一些RNN的方法。但这些方法不仅计算复杂,消耗资源,同时可解释性也非常差。
SIF embedding
这是作者在ICLR‘17中提出的一种简单的线性embedding方法,SIF=Smoothed Inverse Frequency。核心是对组成句子的词进行线性加权,其中每个词的权重为a/(a+p_w),其中p_w是这个词的词频,a是超参数。这种思想显然是借鉴TF-IDF来的。同时作者还声称,word2vec的代码实现中,通过对词的抽样也实现了类似的加权策略。
除了根据词频来加权以外,SIF embedding还引入一个思想,就是去除文本中与语义无关的向量。具体做法是从数据集中抽样一些句子,然后计算这些句子向量对应的最大的奇异值向量,这样的向量被认为代表了文本中的语法或停用词这些和语义无关的内容。将这些向量去除可以增强文本对语义本身的表达能力(这里可以感叹下向量空间神奇的表达能力)。
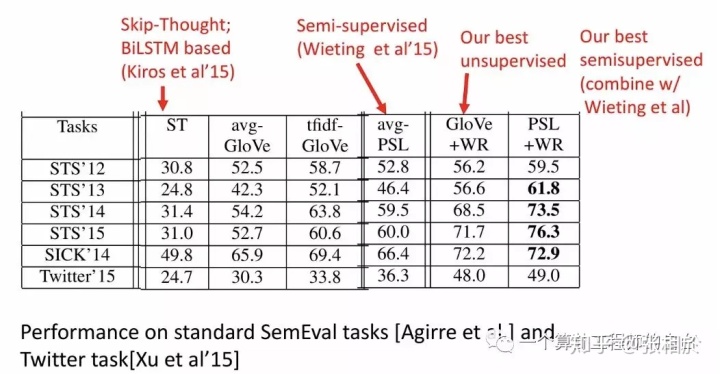
所以说SIF embedding的本质就是“词频加权+语义无关向量去除”。文中在多个任务上将SIF方法与GloVe普通平均、TF-IDF GloVe、LSTM等方法进行了对比,均取得了较好的效果,同时带来了很大的性能提升,因为SIF完全是基于预训练的词向量和线性计算的。下面是实验对比效果:
n-gram embedding
上面提到的SIF方法通过对词向量的线性计算得到了有效的句子和文本向量,但存在的问题在于没有考虑文本中词的顺序。换句话说,更像是一种BoW(Bag of Words)的方法。所以一个很自然的想法就是如何在保持SIF方法简洁性的同时能够很好地考虑词的顺序。
最直观的方式,就是借鉴n-gram的思想。n-gram通过将n个词连在一起,实现了对局部顺序信息的保留。要得到n-gram的向量表示,一种最直观的方法,就是把n-gram看做单个词,然后将SIF的流程应用上去。但这样带来的一个显然的问题就是语料中不同的n-gram量会非常的大,和词的数量是指数级关系,这在实践中是不可接受的。所以作者们提出了一种基于组合(compositional)的方法:

简单说来,就是将组成n-gram的词的词向量进行按位乘法计算,得到n-gram的词向量。这样就不需要为每个n-gram去训练了,可以直接基于词向量就可以得到。仔细的同学能看出来这种方法是无法保留n-gram内部的顺序的,因为乘法是没有顺序的,但作者提到保留顺序的方法在效果上并无明显提升。
在这个基础上,作者提出了DisC embedding:

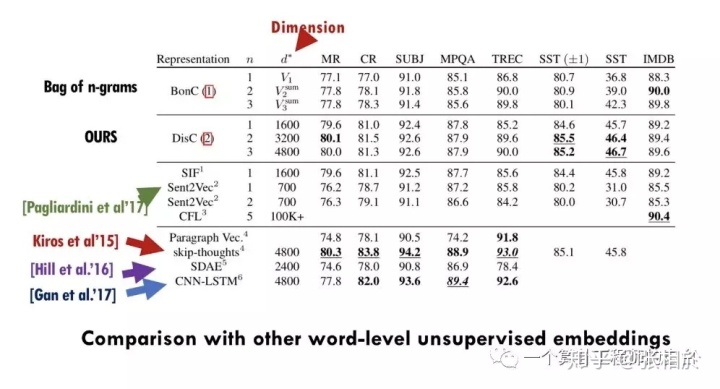
简单说来,DisC embedding就是把不同n对应的n-gram embedding拼接起来,以此来体现文本中的词序,可以看出n取得越大保持的序越长,但也有相应的计算和存储代价。下图是与其他方法的比较:
总结
作者通过两篇文章(以及对应的论文)提出了两种DL-free的本文向量表示方法,可通过对词向量的线性运算得到可与更复杂的DL效果上相媲美的结果。其核心思想包括以下几部分:
- 对词向量根据词频进行加权融合
- 去除语义无关的向量
- 通过组合方式计算n-gram的向量表示
- 通过拼接不同n-gram向量得到文本的向量表示
有兴趣的同学可在自己的数据集上进行尝试,欢迎交流效果。
文章一链接:http://www.offconvex.org/2018/06/17/textembeddings/
文章二链接:http://www.offconvex.org/2018/06/25/textembeddings/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









