







敏感词过滤是随着互联网社区一起发展起来的一种阻止网络犯罪和网络暴力的技术手段,通过对可能存在犯罪或网络暴力的关键词进行有针对性的筛查和屏蔽,能够防患于未然,将后果严重的犯罪行为扼杀于萌芽之中。
随着各种社交论坛的日益火爆,敏感词过滤逐渐成为了非常重要的功能。那么在 Serverless 架构下,利用 Python 语言,敏感词过滤又有那些新的实现呢?我们能否用最简单的方法实现一个敏感词过滤的 API 呢?
了解敏感过滤的几种方法
Replace方法
如果说敏感词过滤,其实不如说是文本的替换,以Python为例,说到词汇替换,不得不想到replace,我们可以准备一个敏感词库,然后通过replace进行敏感词替换:
def worldFilter(keywords, text):
for eve in keywords:
text = text.replace(eve, "***")
return text
keywords = ("关键词1", "关键词2", "关键词3")
content = "这是一个关键词替换的例子,这里涉及到了关键词1还有关键词2,最后还会有关键词3。"
print(worldFilter(keywords, content))
但是动动脑大家就会发现,这种做法在文本和敏感词库非常庞大的前提下,会有很严重的性能问题。例如我将代码进行修改,进行基本的性能测试:
import time
def worldFilter(keywords, text):
for eve in keywords:
text = text.replace(eve, "***")
return text
keywords =[ "关键词" + str(i) for i in range(0,10000)]
content = "这是一个关键词替换的例子,这里涉及到了关键词1还有关键词2,最后还会有关键词3。" * 1000
startTime = time.time()
worldFilter(keywords, content)
print(time.time()-startTime)
此时的输出结果是:0.12426114082336426,可以看到性能非常差。
正则表达方法
与其用replace,还不如通过正则表达re.sub来的更加快速。
import time
import re
def worldFilter(keywords, text):
return re.sub("|".join(keywords), "***", text)
keywords =[ "关键词" + str(i) for i in range(0,10000)]
content = "这是一个关键词替换的例子,这里涉及到了关键词1还有关键词2,最后还会有关键词3。" * 1000
startTime = time.time()
worldFilter(keywords, content)
print(time.time()-startTime)
我们同样增加性能测试,按照上面的方法进行改造测试,输出结果是0.24773502349853516。通过这样的例子,我们可以发现,其性能磣韩剧并不大,但是实际上随着文本量增加,正则表达这种做法在性能层面会变高很多。
DFA过滤敏感词
这种方法相对来说效率会更高一些。例如,我们认为坏人,坏孩子,坏蛋是敏感词,则他们的树关系可以表达:
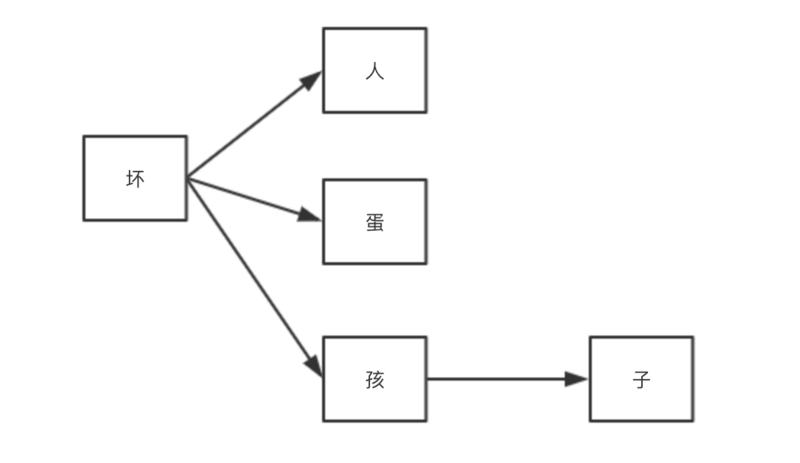
用DFA字典来表示:
{
'坏': {
'蛋': {
'\x00': 0
},
'人': {
'\x00': 0
},
'孩': {
'子': {
'\x00': 0
}
}
}
}
使用这种树表示问题最大的好处就是可以降低检索次数,提高检索效率,基本代码实现:
import time
class DFAFilter(object):
def __init__(self
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1280
1280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









