







简介:《Hadoop权威指南》是大数据领域的经典之作,系统性地讲解了Apache Hadoop开源框架的原理与应用。Hadoop的核心由HDFS和MapReduce组成,分别提供分布式数据存储和并行处理能力。书中详细介绍Hadoop架构及其生态系统,包括YARN、HBase、Pig、Hive和Spark等组件的使用和最佳实践,同时涉及安装、配置、优化和故障排除等内容,为读者提供全面的学习路径,助力深入理解和掌握大数据处理技术。 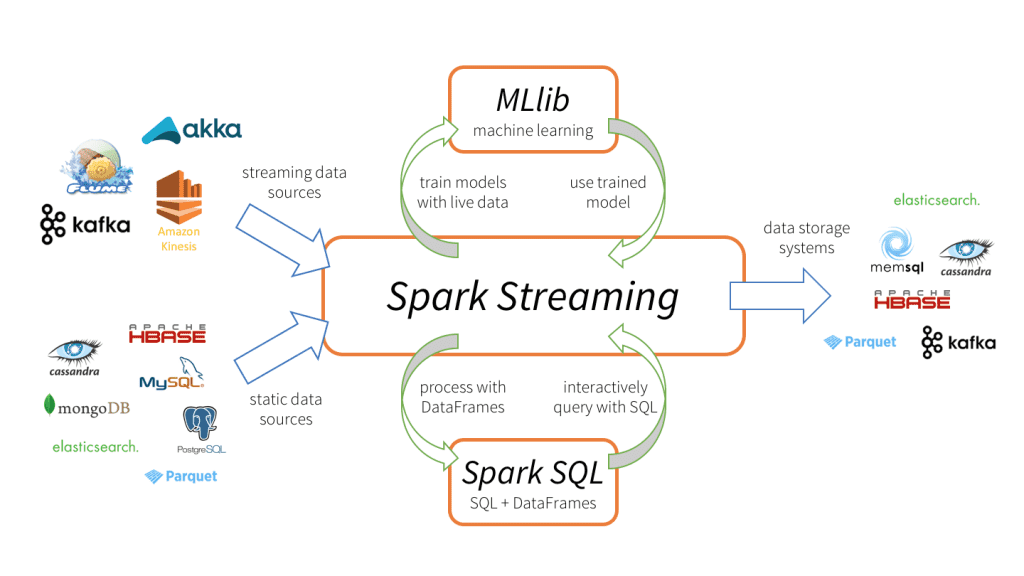
1. Hadoop开源框架的介绍
在数据处理领域,Hadoop已成为一个同义词,代表着大数据的存储与分析。作为一个开源框架,Hadoop以其强大的可扩展性和灵活性在业界迅速普及。它是由Apache软件基金会开发的,允许使用简单的编程模型跨计算机集群分布式处理大规模数据集。Hadoop的设计灵感来源于Google的MapReduce论文,以及Google的文件系统(GFS)概念。
Hadoop不仅包括了存储(Hadoop Distributed File System,HDFS)和计算(MapReduce)组件,还构成了整个Hadoop生态系统的核心,支持各种数据密集型任务,包括但不限于批量处理、数据仓库、数据流处理以及机器学习。它具有容错性和高可靠性,能够应对硬件故障,同时支持多种数据模型,如批处理、流式处理、以及交互式查询。
本章将概述Hadoop框架的基本组成和工作原理,并对它在大数据领域中扮演的角色进行初步探讨,为后续章节中深入理解HDFS和MapReduce打下基础。通过后续章节的深入分析,我们将探索Hadoop的各个组件如何协同工作,以及如何优化和管理Hadoop集群以满足企业级应用的需求。
2. HDFS分布式文件系统的架构与功能
2.1 HDFS的基本概念和设计目标
HDFS的核心组成
Hadoop分布式文件系统(HDFS)是Hadoop项目的核心组件之一,它的设计初衷是为了在廉价的硬件上存储大量的数据。HDFS是高容错的,并且为分布式存储提供了出色的扩展能力。HDFS的两个主要组件是NameNode和DataNode。
NameNode负责管理文件系统的命名空间,维护整个文件系统树以及整个文件系统的元数据。在HDFS中,文件被分割成块(默认大小为128MB),这些块存储在DataNode上。DataNode管理存储在节点上的数据块。NameNode执行文件系统的所有元数据操作,例如打开、关闭和重命名文件和目录。
数据存储和备份机制
在HDFS中,为了实现数据的高可用性和容错性,每个数据块默认会保存三个副本,这包括一个主副本和两个从副本。副本策略在Hadoop的配置文件中定义,通常可以调整副本的数量和放置策略。副本不仅分布在多个DataNode上,而且尽可能分布在不同的机架上以防止机架故障造成数据丢失。
HDFS提供了一个高效的文件传输机制,允许对数据进行流式访问。MapReduce框架利用这种特性,将计算任务移动到数据所在的位置,而不是将数据传输到计算节点。这种方式大大提高了数据处理的效率,特别是在处理大规模数据集时。
2.2 HDFS的架构深入解析
NameNode和DataNode的角色与功能
NameNode是HDFS的主节点,维护了文件系统树及其所有的目录和文件元数据。它负责处理客户端的读写请求,并将文件系统状态的变化记录到磁盘上的文件系统镜像中。为了确保高可用性,可以使用两个活动的NameNode,一个是主NameNode,另一个是备用NameNode。当主NameNode发生故障时,备用NameNode能够迅速接管。
DataNode是HDFS的从节点,负责存储和检索块数据,以及执行数据块的创建、删除和复制任务。DataNode响应来自NameNode的指令,处理来自客户端的读写请求,并在文件系统空间允许的情况下定期发送心跳包和块报告。
HDFS的读写流程与数据一致性
当客户端想要读取一个文件时,首先会与NameNode通信,获取文件数据块的位置信息。然后,客户端直接从对应的DataNode读取数据块。写入过程则更为复杂,客户端首先会将数据发送给一个DataNode(称为管道的第一个DataNode),然后这个DataNode将数据以流水线的方式传输给下一个DataNode,依此类推,直到数据完全写入所有需要的DataNode。
HDFS通过上述机制保证了数据的高可用性和容错性。但是,它也需要一种机制来确保数据的一致性。HDFS使用版本控制来处理并发写入,并且利用校验和来检测数据损坏。当数据块在写入过程中被复制到多个DataNode时,HDFS确保每个副本的校验和与原始数据块一致。如果某个副本损坏,系统会自动从其他副本复制新的数据块,以确保数据的完整性。
2.3 HDFS的高可用性与扩展性
集群的故障转移机制
HDFS集群的一个关键特性是其高可用性(HA)。高可用性是指当一个组件失败时,系统可以继续运行而不影响服务。HDFS通过维护多个活动和备用NameNode来实现故障转移。当活动NameNode发生故障时,备用NameNode可以迅速接管其职责。这需要共享存储,如NFS或Quorum Journal Manager,来同步NameNode之间的心跳信息和状态。
此外,为了保持高可用性,HDFS使用了ZooKeeper来管理NameNode状态,并确保在故障转移期间只有一个NameNode处于活动状态。集群中所有的DataNode都是活跃的,并且它们定期向NameNode报告自身状态,这样就能在发生故障时及时检测并进行响应。
HDFS的扩展策略和实践
随着数据量的不断增长,HDFS必须能够进行水平扩展以满足不断增长的存储需求。扩展HDFS非常简单,只需增加更多的DataNode到集群中即可。HDFS的扩展还涉及到了集群中资源的重新均衡。当一个DataNode加入或离开集群时,HDFS会自动迁移数据以均衡数据分布和提高读写效率。
在实践中,数据扩展往往伴随着硬件升级,以提高系统的性能和可靠性。例如,可以通过增加更多、更大或更快的硬盘来提高存储容量和I/O性能。集群管理员还需要监控集群的使用情况,并根据需要调整副本的数量和布局策略,以优化性能和存储效率。
graph LR
A[开始] --> B[安装DataNode]
B --> C[启动DataNode]
C --> D[注册DataNode到NameNode]
D --> E[DataNode定期发送心跳]
E --> F{检查DataNode状态}
F --> |正常| G[继续心跳]
F --> |异常| H[移除DataNode]
G --> I[维持数据副本一致性]
H --> I
上面的mermaid流程图展示了DataNode加入HDFS集群后的初始化和运行流程。HDFS通过这种机制确保了数据存储的稳定性和高可用性。在实际操作中,管理员会配置相应的脚本来定期检查集群状态并进行优化。
graph LR
A[集群扩展开始] --> B[增加DataNode]
B --> C[数据自动迁移]
C --> D[监控数据分布]
D --> E[优化存储和性能]
E --> F[结束扩展过程]
这个流程图展示了HDFS扩展策略的执行步骤。需要注意的是,集群扩展并不需要停机,这是一个无缝的、在线的过程,保证了服务的连续性。扩展之后,需要监控集群的性能,确保集群的健康状态。
通过上述章节的详细解析,我们可以看到HDFS作为一个分布式的文件系统,其设计充分考虑了高容错、可扩展和高效存取等需求。HDFS的架构和机制为大数据存储提供了一个可靠的解决方案,并为大数据处理应用如MapReduce提供了良好的基础。
3. MapReduce编程模型及其工作流程
在Hadoop生态系统中,MapReduce是一个关键的编程模型,用于处理和生成大数据集。MapReduce模型的设计允许开发者编写程序,这些程序可以在分布式环境中自动并行处理大量数据,提高了计算的效率和速度。MapReduce不仅仅是技术,它还代表了一种处理大规模数据集的计算模式,这种模式已经成为大数据处理的一个标准。
3.1 MapReduce的核心概念和计算模型
3.1.1 Map和Reduce任务的定义
MapReduce模型将任务分解为两个主要阶段:Map阶段和Reduce阶段。Map阶段处理输入数据,生成键值对,而Reduce阶段则对这些键值对进行合并操作。每个阶段都是由一系列并行任务组成,可以分布在多个节点上。
- Map阶段: Map阶段通常用于过滤和排序。它读取输入数据,然后对数据进行处理,生成键值对。这个过程被分解成许多小任务,每个任务处理输入数据的一部分。
- Reduce阶段: Reduce阶段则接收Map阶段输出的所有键值对,并将它们归并成更小的键值对集合。Reduce函数通常用于执行合并和汇总操作。
Map和Reduce函数都是由用户定义的,允许开发者根据特定需求进行编程。
// 一个简单的MapReduce Java代码示例
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
3.1.2 MapReduce的工作流程简述
MapReduce的工作流程可以分为以下几个步骤:
- 输入分割: 首先,Hadoop将输入文件分割为固定大小的片段,称为“块”,每个块被分配给一个Map任务。
- Map阶段: 每个Map任务读取它负责的块,并运行用户定义的Map函数,生成键值对。
- Shuffle: 所有Map任务完成后,其输出的键值对会进行排序和分组,确保所有相同键的值都被发送到同一个Reduce任务。
- Reduce阶段: Reduce任务接收来自Map任务的键值对,并执行Reduce函数,汇总具有相同键的值。
- 输出: 最终结果被写入到输出文件中。
3.2 MapReduce编程实践
3.2.1 编写第一个MapReduce程序
编写MapReduce程序需要对Java和Hadoop的API有一定了解。以下是实现单词计数的MapReduce程序的步骤:
// 定义Map函数
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
// 定义Reduce函数
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
// 设置作业的驱动程序
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
3.2.2 MapReduce的优化技巧
MapReduce编程模型虽然强大,但对性能有很高的要求。以下是一些优化技巧:
- 合理划分Map和Reduce任务的数量: 任务过多会增加调度开销,过少会导致资源利用率不足。
- 减少中间数据传输: 尽可能减少Map输出的数据量,可以提高整个作业的运行效率。
- 数据本地化: 优先在数据存储的节点上执行Map任务,减少网络传输。
- 优化MapReduce的配置参数: 根据实际需要调整内存、CPU等资源的配置。
3.3 MapReduce工作流程的深入理解
3.3.1 作业调度和任务分配机制
MapReduce作业调度和任务分配是Hadoop集群管理资源和负载平衡的关键部分。作业调度器会根据集群的当前状态和资源需求,将任务分配给可用节点。
- 作业调度器: Hadoop提供了多个调度器,包括FIFO调度器、容量调度器和公平调度器等,用户可以根据实际需求选择合适的调度器。
- 任务分配: 一旦作业被调度器选中,它会根据节点的资源状况和数据的位置,将任务分配给特定的节点。
3.3.2 MapReduce的容错机制
容错机制是MapReduce模型中非常重要的一个方面,它确保了即使在有节点失败的情况下,作业也能够成功完成。
- 任务重试: 如果一个任务失败,Hadoop会自动将其调度到另一个节点上重新执行。
- 数据副本: HDFS会为数据创建多个副本,如果某个副本所在的节点失败,还有其他副本可用。
graph LR
A[开始] --> B{Map阶段}
B -->|读取数据| C[Map任务执行]
C -->|键值对输出| D[Shuffle]
D -->|按键排序| E[Reduce阶段]
E -->|归并值| F[输出结果]
F --> G[结束]
MapReduce模型的介绍到此结束,但是Hadoop的探索之旅还远没有结束。在下一章中,我们将深入探讨Hadoop生态系统中的关键组件,如YARN、HBase、Pig、Hive以及Spark。这些组件扩展了Hadoop的功能,使其成为处理大数据的强大工具。
4. Hadoop生态系统组件概述(YARN、HBase、Pig、Hive、Spark)
Hadoop生态系统包含了多种组件,它们针对大数据的不同处理需求提供了多样化的解决方案。本章节将详细介绍核心组件,从资源管理框架YARN,到NoSQL数据库HBase,再到提供高层次抽象的Pig和Hive,以及面向实时处理的Spark。
4.1 YARN资源管理框架
4.1.1 YARN架构和组件解析
YARN(Yet Another Resource Negotiator),即另一种资源协调者,是Hadoop 2.0引入的新资源管理器。它将资源管理和任务调度/监控分离开,使Hadoop能够支持更多种类的处理任务,包括批处理、流处理、迭代计算等。
YARN的核心组件包括:
- 资源管理器(ResourceManager, RM) :负责整个系统的资源管理和任务调度。它包含两个主要的子组件:调度器(Scheduler)和应用管理器(ApplicationManager)。
- 节点管理器(NodeManager, NM) :管理各个节点上的资源使用情况,监控资源(CPU、内存、磁盘、网络)和处理来自ResourceManager的任务指令。
- 应用程序历史服务器(ApplicationHistoryServer, AHS) :收集和存储运行完成的应用程序的历史信息,用于故障恢复和作业监控。
4.1.2 YARN的资源调度和任务管理
YARN的资源调度器是一个可插拔组件,可以选择不同的调度策略。常用的调度器包括先进先出(FIFO)、容量调度器(Capacity Scheduler)和公平调度器(Fair Scheduler)。
- 先进先出(FIFO)调度器 :按照作业提交的顺序依次执行。
- 容量调度器(Capacity Scheduler) :允许资源按照容量进行预分配,可以为不同的用户组或应用设置资源配额,实现多租户环境下的资源管理。
- 公平调度器(Fair Scheduler) :保证所有活跃的用户或应用都能公平地共享集群资源。
YARN通过使用Container作为资源抽象,使得应用可以在任何可用的资源上运行。每个应用需要的资源在提交时指定,并由ResourceManager进行分配。
4.2 NoSQL数据库HBase
4.2.1 HBase的数据模型和存储原理
HBase是一个开源的、分布式的、可扩展的非关系型数据库,用于存储大规模稀疏数据集。它基于Google的Bigtable模型构建,并且运行在HDFS之上。
HBase的数据模型包括以下几个核心概念:
- 表(Table) :HBase中的主要数据集合,由多个行组成。
- 行(Row) :表中的每一行由行键(Row Key)标识,并且每行包含一系列的列族(Column Family)和列限定符(Column Qualifier)。
- 列族(Column Family) :列的集合,所有列族下的数据存储在一起。
- 列限定符(Column Qualifier) :标识具体列的名称,它与列族结合使用来唯一标识表中的数据。
HBase存储原理:
- 行键设计 :为了性能优化,行键的设计非常重要,通常需要实现排序和散列,以便高效的行插入和查询。
- 列族存储 :每个列族的列数据存储在同一个HFile文件中,HFile是HBase底层存储数据的文件格式。
- Region分片 :HBase会自动将大表水平切分成多个小块,称为Regions,这些Regions由RegionServer管理。
4.2.2 HBase的使用场景和性能优化
HBase适用于以下使用场景:
- 日志分析 :存储日志数据,用于实时查询和分析。
- 大数据集存储 :支持存储和处理PB级别的数据。
- 随机读写密集型应用 :支持快速的随机访问,适合于需要快速读写的应用场景。
性能优化:
- 合理设计行键 :使用散列或时间戳来设计行键,以促进数据的均匀分布和高效的查询。
- 预分区 :在创建表时进行预分区,可以控制数据的分布。
- 压缩 :启用压缩可以减少存储空间并提高IO效率。
- 配置合理的缓存 :合理配置BlockCache和Write-Ahead Log(WAL)来提高读写性能。
4.3 基于Hadoop的Pig和Hive
4.3.1 Pig的编程模型和特点
Pig是一个高层次的数据流语言和执行框架,用于处理大规模数据集。它提供了一个名为Pig Latin的脚本语言,让数据分析师能够使用类似SQL的方式进行数据转换和处理。
Pig Latin的特点:
- 高抽象级别 :隐藏了底层的MapReduce细节,让编程变得简单。
- 可扩展性 :支持自定义函数(UDF),可以使用Java、Python等语言编写。
- 优化器 :Pig内置优化器,可以自动优化查询计划。
4.3.2 Hive的数据仓库功能和SQL兼容性
Hive是一个建立在Hadoop之上的数据仓库工具,它提供了一种类SQL语言——HiveQL。HiveQL允许用户执行数据摘要、查询和分析。
Hive的数据仓库功能:
- 元数据管理 :存储表结构信息,提供了对数据的结构化管理。
- 数据分区 :支持数据分区,提高查询效率。
- 索引 :提供索引机制,支持更快的数据检索。
Hive SQL兼容性:
- 支持子查询、连接、聚合、条件表达式 :使得复杂的查询成为可能。
- 支持视图、表分区和桶 :更接近传统数据库的功能。
4.4 实时大数据处理的Spark
4.4.1 Spark的核心概念和架构优势
Apache Spark是一个快速、通用的计算引擎,提供了一个高度抽象的API来简化分布式应用的开发。
Spark的核心概念:
- 弹性分布式数据集(RDD) :不可变的分布式对象集合,是Spark的核心抽象。
- DAG调度 :通过将作业转换成DAG(有向无环图)来执行,有效地进行任务调度和依赖管理。
架构优势:
- 内存计算 :Spark设计来优化内存计算,可以显著提高处理速度。
- 支持批处理、流处理、机器学习和图计算 :一个统一的执行引擎。
- 容错性 :通过RDD的不变性和分区依赖关系,实现了高效的数据恢复。
4.4.2 Spark的应用场景和编程实践
Spark应用场景:
- 批处理 :处理静态数据集,如日志分析、ETL等。
- 流处理 :通过Spark Streaming进行实时数据处理。
- 机器学习 :使用MLlib库来实现各种机器学习算法。
- 图计算 :通过GraphX库来进行大规模图处理。
编程实践:
- RDD转换和行动操作 :使用map、filter、reduce等转换操作处理数据,然后通过count、collect等行动操作触发计算。
- Spark SQL :使用Spark SQL来处理结构化数据。
- RDD持久化 :将RDD持久化到内存中,加快迭代算法和快速查询的速度。
- 使用Spark UI监控作业执行 :监控作业的性能和资源使用情况。
在下一章节中,我们将深入探讨大数据处理实践技巧,包括数据处理的最佳实践、数据分析与挖掘、以及大数据可视化技术。
5. 大数据处理实践技巧
5.1 数据处理的最佳实践
数据清洗和预处理技巧
数据清洗是大数据分析前的重要步骤,可以提高数据质量,为后续的数据分析和挖掘奠定坚实基础。有效的数据清洗应该遵循以下技巧:
数据缺失值处理
数据集中往往存在缺失值,这些缺失值可能是由于数据收集、传输或存储过程中的问题导致。常见的处理方法包括删除含有缺失值的记录、填充缺失值(使用均值、中位数或众数等)或者使用算法预测缺失值。
import pandas as pd
# 创建一个包含缺失值的DataFrame
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [5, None, 7, 8]
})
# 删除含有缺失值的记录
df_cleaned = df.dropna()
# 填充缺失值为列的均值
df_filled = df.fillna(df.mean())
异常值检测和处理
异常值可能是错误数据或真正的离群点。检测异常值可以使用标准差、IQR(四分位距)或基于统计模型的方法。处理异常值可采用删除、修正或保留等策略。
from scipy import stats
# 使用Z分数检测异常值
z_scores = stats.zscore(df[['A']])
abs_z_scores = abs(z_scores)
filtered_entries = (abs_z_scores < 3) # 保留z分数小于3的记录
df_no_outliers = df[filtered_entries]
数据转换和编码
某些机器学习算法需要数值型输入,因此,非数值型数据需要转换。常见的转换方法包括标签编码、独热编码和标准化。
from sklearn.preprocessing import OneHotEncoder, StandardScaler
# 标签编码
encoder = LabelEncoder()
df['Category'] = encoder.fit_transform(df['Category'])
# 独热编码
encoder = OneHotEncoder()
encoded_feature = encoder.fit_transform(df[['Category']]).toarray()
# 标准化
scaler = StandardScaler()
df[['Feature1', 'Feature2']] = scaler.fit_transform(df[['Feature1', 'Feature2']])
数据归一化和规范化
归一化(Normalization)和规范化(Standardization)都是使数据符合特定范围或分布的技术。归一化通常将数据缩放到[0,1]区间,而规范化通常将数据转换为具有单位方差和零均值的分布。
# 归一化
df['Feature1'] = (df['Feature1'] - df['Feature1'].min()) / (df['Feature1'].max() - df['Feature1'].min())
# 规范化
scaler = StandardScaler()
df[['Feature1']] = scaler.fit_transform(df[['Feature1']])
大数据的ETL流程优化
ETL(抽取、转换、加载)是数据仓库中重要的数据处理过程,优化ETL流程能够提高数据处理效率和数据质量。
高效的数据抽取
优化数据抽取可以从源头减少数据冗余和错误。例如,通过选择性地抽取需要的列而不是整个表,或者使用增量抽取代替全量抽取。
-- 假设数据库中有一张销售记录表,我们只需要最近一个月的数据
SELECT * FROM sales_records
WHERE date >= NOW() - INTERVAL 1 MONTH
数据转换的并行处理
大数据环境支持分布式处理,利用并行处理可以显著提升数据转换的效率。例如,使用Hadoop或Spark来并行处理数据转换任务。
from pyspark.sql import SparkSession
# 初始化Spark会话
spark = SparkSession.builder.appName("ETL Process").getOrCreate()
# 读取数据
dataframe = spark.read.format("csv").option("header", "true").load("path/to/data.csv")
# 数据转换操作
transformed_df = dataframe.select('col1', 'col2').where(dataframe['col1'] > 10)
# 保存转换后的数据到新的CSV文件
transformed_df.write.format("csv").option("header", "true").save("path/to/transformed_data.csv")
负载的优化
优化数据加载过程可以减轻目标系统(如数据仓库或数据库)的负担。通过调整加载时间窗口、批量加载等方式可以有效减少对目标系统的冲击。
# 分批插入数据到数据库中
for i in range(0, dataframe.count(), 1000):
dataframe.iloc[i:i+1000].to_sql('target_table', conn, if_exists='append', chunksize=1000)
5.2 大数据的分析与挖掘
分布式计算在数据分析中的应用
分布式计算架构可以处理PB级别的数据,通过将计算任务分散到多个计算节点上,可以实现对大数据集的高效处理。
分布式数据处理的优势
分布式系统相对于单机系统有明显的性能优势,尤其在处理大规模数据时。它可以通过增加更多的节点来线性提高计算能力。
flowchart LR
A[数据节点1] -->|计算任务| B[数据节点2]
A -->|计算任务| C[数据节点3]
B -->|结果| D[汇总]
C -->|结果| D
A -->|数据传输| E[NameNode]
B -->|数据传输| E
C -->|数据传输| E
D -->|汇总结果| E
MapReduce编程模型的应用
MapReduce是Hadoop的核心组件,它允许开发者编写可以分布在集群上运行的程序。通过Map和Reduce两个阶段的计算,可以有效地处理大规模数据集。
from pyspark import SparkContext
def map_function(line):
# 解析输入数据,生成键值对
key, value = line.split()
return key, value
def reduce_function(key, values):
# 对每个键对应的值进行聚合操作
return sum(values)
sc = SparkContext("local", "First MapReduce Program")
text_file = sc.textFile("hdfs://path/to/input")
map_result = text_file.map(map_function)
reduce_result = map_result.reduceByKey(reduce_function)
reduce_result.collect()
大数据挖掘的算法和案例
大数据挖掘是指从大量的、不完全的、有噪声的、模糊的实际数据中,提取出对决策有潜在价值的知识和模型。
聚类算法应用
聚类是一种无监督学习方法,用于将相似的数据项分组。在大数据环境下,K-means聚类算法因其高效率和可扩展性被广泛应用。
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 标准化特征数据
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
# 应用K-means算法
kmeans = KMeans(n_clusters=3)
clusters = kmeans.fit_predict(scaled_data)
分类算法应用
分类是另一种监督学习方法,用于预测新样本的类别。决策树、随机森林和SVM(支持向量机)是常见的分类算法。
from sklearn.ensemble import RandomForestClassifier
# 训练随机森林分类器
clf = RandomForestClassifier(n_estimators=100, max_depth=5)
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
大数据挖掘案例
在零售行业,通过数据挖掘可以帮助企业了解消费者行为,优化库存管理,并提供个性化推荐。
消费者行为分析
通过分析消费者的购物数据,可以发现消费者的购买习惯、喜好和消费能力等特征。
SELECT customer_id, SUM(amount_spent) as total_spent, COUNT(*) as purchase_count
FROM purchase_history
GROUP BY customer_id
HAVING total_spent > 1000 AND purchase_count > 5
ORDER BY total_spent DESC
库存管理优化
通过预测未来的产品需求,企业可以更合理地管理库存,降低库存成本。
from statsmodels.tsa.arima.model import ARIMA
# 使用ARIMA模型进行时间序列预测
model = ARIMA(p=1, d=1, q=1)
model_fit = model.fit()
forecast = model_fit.forecast(steps=n)
个性化推荐
利用用户的历史行为数据和物品的属性,可以构建推荐系统,向用户推荐可能感兴趣的商品或服务。
# 基于用户-物品评分矩阵的推荐算法伪代码
def recommend(user_id, user_item_matrix, num_recommendations):
# 找到用户评分最高的物品
user_ratings = user_item_matrix[user_id]
best_items = user_ratings.sort_values(ascending=False).index[1:num_recommendations+1]
return best_items
5.3 大数据可视化技术
可视化工具的对比和选择
选择合适的可视化工具对于实现高效的数据可视化至关重要。不同的工具具有不同的特性和优势。
常见的大数据可视化工具
工具如Tableau、Power BI、Qlik Sense等提供了丰富的图表类型和用户友好的界面,适合商业智能分析。而D3.js和Matplotlib等则适合开发定制化和交互式的可视化应用。
graph LR
A[商业智能工具] -->|适合| B[Tableau]
A -->|适合| C[Power BI]
A -->|适合| D[Qlik Sense]
E[编程库] -->|适合| F[D3.js]
E -->|适合| G[Matplotlib]
工具选择的考虑因素
在选择可视化工具时,应考虑数据的大小、可视化需求的复杂性、用户的技能水平、成本和部署等因素。
实现高效大数据可视化的方法
高效的可视化可以将复杂的数据以直观的方式展现,帮助用户快速理解和分析数据。
使用交互式可视化
交互式可视化允许用户与数据进行交互,如通过筛选、缩放、点击等方式探索数据。
import matplotlib.pyplot as plt
import numpy as np
# 使用matplotlib创建简单的交互式图表
x = np.random.rand(10)
y = np.random.rand(10)
plt.scatter(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show()
利用数据可视化传达故事
数据可视化不只是展示图表,更是讲述数据背后的故事。一个好的数据可视化作品可以揭示数据之间的关系、趋势和模式。
graph LR
A[数据收集] -->|处理| B[数据清洗]
B -->|分析| C[关键洞察]
C -->|可视化| D[讲述故事]
优化图表设计
图表的设计应该遵循简洁、清晰、准确的原则,避免过度装饰和不必要的元素,确保信息的有效传递。
graph TD
A[确定可视化目标] --> B[选择适当的图表类型]
B --> C[确保图表的可读性]
C --> D[使用恰当的配色和字体]
D --> E[进行用户测试和反馈]
通过上述章节内容,我们深入探讨了大数据处理的实践技巧,包括数据处理的最佳实践、大数据分析与挖掘的算法和案例,以及大数据可视化技术。希望这些内容能够帮助读者在实际工作中有效运用大数据技术,解决复杂的数据问题,为业务决策提供有力支持。
6. Hadoop环境的安装、配置、优化和故障处理
6.1 Hadoop环境的安装和配置
6.1.1 单节点和多节点Hadoop集群搭建
搭建一个Hadoop集群可以从单节点开始,逐步扩展到多节点,以适应不同的数据处理需求。以下是单节点Hadoop集群的搭建步骤:
- 安装Java开发环境:Hadoop是用Java编写的,因此需要先安装Java。
- 下载并安装Hadoop:从Apache Hadoop的官方网站下载对应版本的Hadoop。
- 配置Hadoop环境变量:在
~/.bashrc或~/.bash_profile文件中设置HADOOP_HOME环境变量,并确保$HADOOP_HOME/bin在PATH中。 - 修改配置文件:编辑
$HADOOP_HOME/etc/hadoop/core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml文件,配置文件系统的默认设置、HDFS副本数量、MapReduce作业调度器和YARN资源管理器。 - 格式化HDFS文件系统:使用
hdfs namenode -format命令格式化NameNode。 - 启动集群:执行
start-dfs.sh和start-yarn.sh脚本来启动HDFS和YARN。
对于多节点集群搭建,步骤类似,但需要在所有节点上重复上述步骤,并确保所有节点间的SSH免密登录设置正确。此外,在 core-site.xml 中设置集群的NameNode主机和端口,以及在 masters 和 slaves 文件中明确指定主节点和从节点。
6.1.2 Hadoop配置参数详解
Hadoop的配置非常灵活,其性能与配置参数息息相关。下面是一些关键的配置参数:
-
fs.defaultFS: 定义Hadoop文件系统的默认名称和通信协议。 -
dfs.replication: 设置HDFS中的文件块复制的因子,默认为3。 -
mapreduce.framework.name: 指定MapReduce作业运行的模式,默认为yarn。 -
yarn.nodemanager.aux-services: 定义YARN节点管理器的附加服务。 -
yarn.resourcemanager.address: 指定资源管理器的地址和端口。
每项配置都有其默认值,但根据实际硬件资源和业务需求,合理的参数调整可以显著提升集群性能和稳定性。
6.2 Hadoop性能优化
6.2.1 系统和网络优化策略
Hadoop集群的性能优化可以从多个层面进行,首先是系统级别的优化:
- JVM调优 :合理配置Java虚拟机堆内存大小,减少Full GC的发生。
- CPU资源 :通过cgroups或Kubernetes等工具限制不必要的服务使用CPU资源,保证数据处理任务有足够的CPU核心。
- 磁盘I/O :使用SSD替换HDD作为NameNode的存储介质,以降低读写延迟。
在系统层面之外,网络优化也至关重要:
- 高速网络 :使用高速网络,如10Gb以太网,以减少数据传输时间。
- 网络隔离 :对于关键的生产环境,考虑使用网络隔离措施,减少数据传输和作业调度之间的干扰。
6.2.2 Hadoop作业的性能调优
作业级别的优化需要根据具体的应用场景和数据特性来进行:
- 并行度设置 :通过调整
mapreduce.job.maps和mapreduce.job.reduces参数来设置Map和Reduce任务的数量。 - 数据序列化 :选择高效的数据序列化框架如Kryo,减少数据在网络中的传输量。
- 内存管理 :合理配置每个任务的内存需求,如
mapreduce.map.memory.mb和mapreduce.reduce.memory.mb,以避免内存溢出或资源浪费。
优化策略的执行需要结合监控工具不断调整,以实现最佳性能。
6.3 Hadoop故障处理和监控
6.3.1 常见故障的排查与解决
Hadoop集群故障排查通常包括以下步骤:
- 日志分析 :检查Hadoop组件的日志文件,获取错误信息。
- 集群状态检查 :使用
hdfs fsck和yarn node -list等命令检查文件系统和节点状态。 - 资源监控 :通过监控工具如Ganglia、Nagios或Ambari实时监控集群资源使用情况,及时发现异常。
- 组件重启 :根据错误信息对故障组件进行重启,如NameNode或DataNode。
6.3.2 Hadoop集群的监控和报警机制
监控是保障Hadoop集群稳定运行的关键,需要从以下方面构建监控体系:
- 服务监控 :监控Hadoop核心服务状态,如HDFS NameNode、DataNode,以及YARN的ResourceManager和NodeManager。
- 硬件监控 :监控服务器硬件信息,包括CPU、内存、磁盘I/O、网络接口状态等。
- 性能指标 :收集性能指标数据,如MapReduce作业执行时间、数据读写速度等,通过图表展示历史趋势。
- 报警机制 :当监控指标达到预定的阈值时,通过邮件、短信或即时通讯工具发送报警信息给运维人员。
通过全面的监控和快速的故障响应机制,可以最小化系统停机时间,提高Hadoop集群的稳定性和可靠性。
7. Hadoop安全性分析与强化措施
7.1 Hadoop安全模型基础
在大数据处理领域,Hadoop的开源框架因其强大的数据处理能力而受到青睐。然而,随着其应用范围的扩大,数据安全和集群安全成为不可忽视的重要课题。Hadoop安全模型主要包含了认证(Authentication)、授权(Authorization)、数据加密(Encryption)以及审计(Auditing)等关键组成部分。Hadoop的安全性分析需要从这些关键组件入手,进而深入探讨相应的强化措施。
7.2 用户认证与授权机制
Hadoop通过Kerberos协议实现用户认证。每个使用Hadoop集群资源的用户都需要通过Kerberos认证才能被授权访问。授权则是通过访问控制列表(ACLs)和基于角色的访问控制(RBAC)来实现。用户或应用程序在执行操作时,Hadoop会检查其权限,只有在权限允许的情况下才能继续执行操作。
用户认证流程
- 用户从Kerberos服务器获取初始票据(TGT, Ticket Granting Ticket)。
- 用户使用TGT请求票据授予服务器(TGS, Ticket Granting Server)的票据以访问Hadoop集群。
- TGS为用户生成服务票据(ST, Service Ticket),用户使用ST访问Hadoop集群。
授权流程
- 用户提交访问请求到Hadoop集群。
- Hadoop集群的权限检查器查询用户权限信息。
- 如果用户权限符合请求操作的要求,则请求被授权。
7.3 数据加密方法
数据在存储和传输过程中也可能面临安全风险,因此Hadoop采用了多种加密手段来保障数据安全。主要分为传输加密和静态数据加密两种。
传输加密
传输加密主要用于保障数据在集群节点间传输过程中的安全,Hadoop利用SSL/TLS协议对数据进行加密传输。启用传输加密,需在Hadoop的配置文件中设置相应的参数,例如:
# hdfs-site.xml
<property>
<name>dfs.namenode.https-address</name>
<value>namenode-host:50470</value>
</property>
<property>
<name>dfs.data-transfer.https.enabled</name>
<value>true</value>
</property>
静态数据加密
静态数据加密主要通过使用Hadoop的机密管理器来实现。用户可以指定一个密钥,并通过机密管理器对存储在HDFS上的数据进行加密。启用静态数据加密的配置示例如下:
# core-site.xml
<property>
<name>hadoop.security.crypt阔器境</name>
<value>org.apache.hadoop.security.KeyStoreKms</value>
</property>
<property>
<name>hadoop.kms.key.provider.path</name>
<value>jceks://hdfs/user/hadoop/kms_keys</value>
</property>
7.4 审计与监控
审计是Hadoop安全模型中不可或缺的一部分,通过记录和审查系统活动来检测和防止未授权操作。Hadoop集群的操作日志可用于审计目的,但默认情况下可能不包含足够的安全信息。可以通过启用审计日志功能来增强审计能力。监控方面,Hadoop提供了一套工具,例如Ambari和Ganglia,用于集群的健康检查和性能监控。配置监控工具有助于及时发现问题,并采取相应的预防或解决措施。
Hadoop安全性是一个复杂的主题,本章只是简单介绍了其基础和一些强化措施。在实际部署Hadoop集群时,还需要根据具体的安全需求来采取更详细和深入的策略,如网络隔离、定期安全审核、安全更新和补丁管理等。
(注:由于技术环境的快速变化,针对Hadoop的具体配置可能会有所调整,请以最新的官方文档为准。)
简介:《Hadoop权威指南》是大数据领域的经典之作,系统性地讲解了Apache Hadoop开源框架的原理与应用。Hadoop的核心由HDFS和MapReduce组成,分别提供分布式数据存储和并行处理能力。书中详细介绍Hadoop架构及其生态系统,包括YARN、HBase、Pig、Hive和Spark等组件的使用和最佳实践,同时涉及安装、配置、优化和故障排除等内容,为读者提供全面的学习路径,助力深入理解和掌握大数据处理技术。

















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









