






主要功能及其优缺点
Collection(所有集合类的接口)
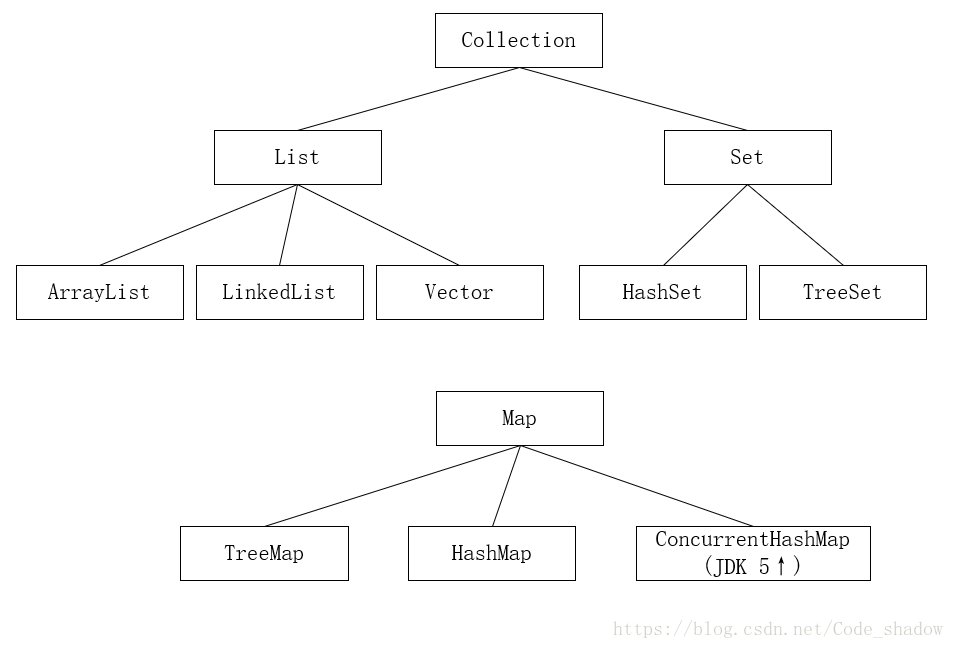
List、Set都继承自Collection接口,查看JDK API,操作集合常用的方法大部分在该接口中定义了。
一、列表List
列表List中所有的结构下标都从0开始,如al.add(3,10)表示将10插入到第四个元素。
1.ArrayList1ArrayList al = new ArrayList();
主要功能:1
2
3
4
5
6
7list.add(E e);//将指定元素添加到集合尾部,E指某一数据类型,如String。
list.remove(int index);//删除并返回该位置上的元素 0~n-1
list.remove(E e);//删除并返回该元素
list.size();//返回该数组的大小 n,可用作遍历 list.fori
ArrayList 不能直接存放基本数据类型,必须使用基本类型对应的包装类。
基本类型 包装类(引用类型,都在java.lang包下)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15byte Byte
short Short
int Integer//Integer
longLong
floatFloat
doubleDouble
charCharacter//Character
booleanBoolean
❤ 类似顺序表,对数据的索引速度比较快。
✖ 添加删除操作删除需要移动部分元素,增删性能不高。
✖ 不支持同步,线程不安全。
适用于变化不大,主要用于查询的数据。
2.LinkList
LinkedList是双向链表,即同时保有前驱节点和后驱节点,支持正向遍历和反向遍历。
item为节点中的元素值,prev和next分别是前向节点和后向节点的引用。1
2
3
4
5
6
7LinkedList list = new LinkedList();
//迭代器遍历
Iterator iter1 = list.iterator();
while(iter1.hasNext()){
iter1.next();
}
这是java的迭代器的用法。
(1)使用方法 iterator()要求容器返回一个 Iterator。第一次调用Iterator 的next()方法时,它返回序列的第一个元素。
(2)使用next()获得序列中的下一个元素。
(3)使用hasNext()检查序列中是否还有元素。
(4)使用remove()将上一次返回的元素从迭代器中移除。
❤ 链表随机位置插入、删除数据时比线性表快。
✖ 遍历比线性表慢,遍历时尽量用顺序遍历。
✖ 不支持同步,线程不安全。
3.vector
与ArrayList类似,可变数组实现的列表。
但Vector同步,适合在多线程下使用,非多线程的情况下优先用ArrayList。
二、集合set
三个特性:
1.确定性:对任意对象都能判定其是否属于某一个集合。
2.互异性:集合内每个元素都是不相同的(元素不重复)。
HashSet根据hashCode、equals这两个方法 (继承自Object类,所有类都有) 判定元素是否同。
TreeSet根据CompareTo方法 (需要元素继承自Comparable接口) 判定是否相同。
3.无序性:集合内没有先后顺序。
1.HashSet
基于散列函数的集合。
❤ 可容纳null元素。
✖ 无序,不支持同步。1
2
3
4
5
6
7
8HashSet hs = new HashSet();
set.add();//添加多次重复的元素相当于只添加一次
set.size();//返回大小
set.clear();//清楚整个HashSet
set.contains();//判断是否包含一个元素
set.remove();//删除一个元素
set.retainAll();//计算两个集合交集
2.LinkedHashSet
继承HashSet,方法和HashSet基本一致。基于散列函数和双向链表的集合。
❤ 可容纳null,有序(插入次序)。
✖ 不支持同步。
3.TreeSet
基于树结构的集合。
❤ 有序(按储存对象大小升序输出)。
✖ 不可容纳null元素,不支持同步,
三、映射Map
数学定义:两个集合之间的元素对应关系。一个输入对应到一个输出。
{Key ,Value} ,键值对,K-V对。
1.Hashtable
❤ 同步,多线程安全
✖ 慢,适用数据量小,K-V对 K V都不能为null,无序1
2
3
4
5
6
7
8
9
10
11
12
13Hashtable ht = new Hashtable();
ht.clear();
ht.put();//增加新的K-V对
ht.get();//根据Key获取相应的值
ht.containsKey();//是否包含某一个Key
ht.contains();//等于containsValue;
ht.containsValue();//是否包含某一个值
ht.remove();
ht.size();
ht.put(3000,"aaa");
ht.put(3000,"bbb");//如果对同一Key值put两次,会对之前的进行覆盖,3000->bbb
2.HashMap
❤ 快,数据量大,K V允许为null
✖ 不支持同步,多线程不安全
3.LinkedHashMap
基于双向链表的 维持插入顺序 的HashMap。
4.TreeMap
基于红黑树的Map,可以根据key的 自然排序(从小到大) 或者 compareTo方法 进行排序输出。
5.Properties
继承自HashTable,也继承了其方法1
2
3
4
5
6
7
8
9Properties pps = new Properties();
InputStream in = new FileInputStream(filePath);
//从输入流中读取属性列表(键和元素对)
pps.load(in);//加载原文件中的所有K-V对。
OutputStream out = new FileOutputStream(filePath);
pps.setProperty(pKey,pValue);//写入一个K-V对
pps.store(out,"Update" + pKey + "name");//将所有K-V对写入到文件
getProperty();//获取某一个Key对应的Value
❤ 同步,K-V对保存在文件中
✖ 数据量小
适用于数据量小的配置文件
四、工具类
这段笔记借鉴(ctrl + cv)的 Gene Xu 博主的内容,介绍详细且简单易懂,以下是原链接
1.填充方法fill
Arrays.fill(Object[] array, Object obj)用指定元素填充整个数组 (会替换掉数组中原来的元素)1
2
3Integer[] data = {1, 2, 3, 4};
Arrays.fill(data, 9);
System.out.println(Arrays.toString(data));
Arrays.fill(Object[] array, int fromIndex, int toIndex, Object obj)用指定元素填充数组,从起始位置到结束位置,取头不取尾 (会替换掉数组中原来的元素)1
2
3Integer[] data = {1, 2, 3, 4};
Arrays.fill(data, 0, 2, 9);
System.out.println(Arrays.toString(data)); *// [9, 9, 3, 4]*
2.排序方法sort
Arrays.sort(Object[] array)对数组元素进行排序 (串行排序)1
2
3
4String[] data = {"1", "4", "3", "2"};
System.out.println(Arrays.toString(data)); // [1, 4, 3, 2]
Arrays.sort(data);
System.out.println(Arrays.toString(data)); // [1, 2, 3, 4]
Arrays.sort(T[] array, Comparator super T> comparator)使用自定义比较器,对数组元素进行排序 (串行排序)
Arrays.sort(Object[] array, int fromIndex, int toIndex)对指定范围内的数组元素进行排序 (串行排序)1
2
3
4
5String[] data = {"1", "4", "3", "2"};
System.out.println(Arrays.toString(data)); // [1, 4, 3, 2]
// 对下标[0, 3)的元素进行排序,即对1,4,3进行排序,2保持不变
Arrays.sort(data, 0, 3);
System.out.println(Arrays.toString(data)); // [1, 3, 4, 2]
Arrays.parallelSort(T[] array)
注意:其余重载方法与 Arrays.sort() 相同对数组元素进行排序 (并行排序),当数据规模较大时,会有更好的性能1
2
3String[] data = {"1", "4", "3", "2"};
Arrays.parallelSort(data);
System.out.println(Arrays.toString(data)); // [1, 2, 3, 4]
3.二分查找法binarySearch
注意:在调用该方法之前,必须先调用 Arrays.sort() 方法进行排序,如果数组没有排序,那么结果是不确定的,此外如果数组中包含多个指定元素,则无法保证将找到哪个元素使用二分法查找数组内指定元素的索引值
从源码中可以看到当搜索元素是数组元素时,返回该元素的索引值
当搜索元素不是数组元素时,返回 - (索引值 + 1)
具体的用法可以看下面的例子搜索元素是数组元素,返回该元素索引值1
2
3Integer[] data = {1, 3, 5, 7};
Arrays.sort(data);
System.out.println(Arrays.binarySearch(data, 1)); // 0搜索元素不是数组元素,且小于数组中的最小值1
2
3
4Integer[] data = {1, 3, 5, 7};
Arrays.sort(data);
// 此时程序会把数组看作 {0, 1, 3, 5, 7},此时0的索引值为0,则搜索0时返回 -(0 + 1) = -1
System.out.println(Arrays.binarySearch(data, 0)); // -1搜索元素不是数组元素,且大于数组中的最大值1
2
3
4Integer[] data = {1, 3, 5, 7};
Arrays.sort(data);
// 此时程序会把数组看作 {1, 3, 5, 7, 9},此时9的索引值为4,则搜索8时返回 -(4 + 1) = -5
System.out.println(Arrays.binarySearch(data, 9)); // -5搜索元素不是数组元素,但在数组范围内1
2
3
4Integer[] data = {1, 3, 5, 7};
Arrays.sort(data);
// 此时程序会把数组看作 {1, 2, 3, 5, 7},此时2的索引值为1,则搜索2时返回 -(1 + 1) = -2
System.out.println(Arrays.binarySearch(data, 2)); // -2















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









