









 本文介绍了如何爬取小米应用商店的一级分类标签及其对应的应用名称。通过分析网页源代码,确定了数据位置,并使用Python实现了数据抓取,最后将数据保存到Excel文件。爬虫功能包括获取指定页面文本、标签ID和一级标签与App名称的对应关系。
本文介绍了如何爬取小米应用商店的一级分类标签及其对应的应用名称。通过分析网页源代码,确定了数据位置,并使用Python实现了数据抓取,最后将数据保存到Excel文件。爬虫功能包括获取指定页面文本、标签ID和一级标签与App名称的对应关系。

一、需求
针对小米应用商店的app信息,获取一级分类下对应的app名称。本博文暂时只获取一级分类及对应的app名称。网站信息如下图所示。
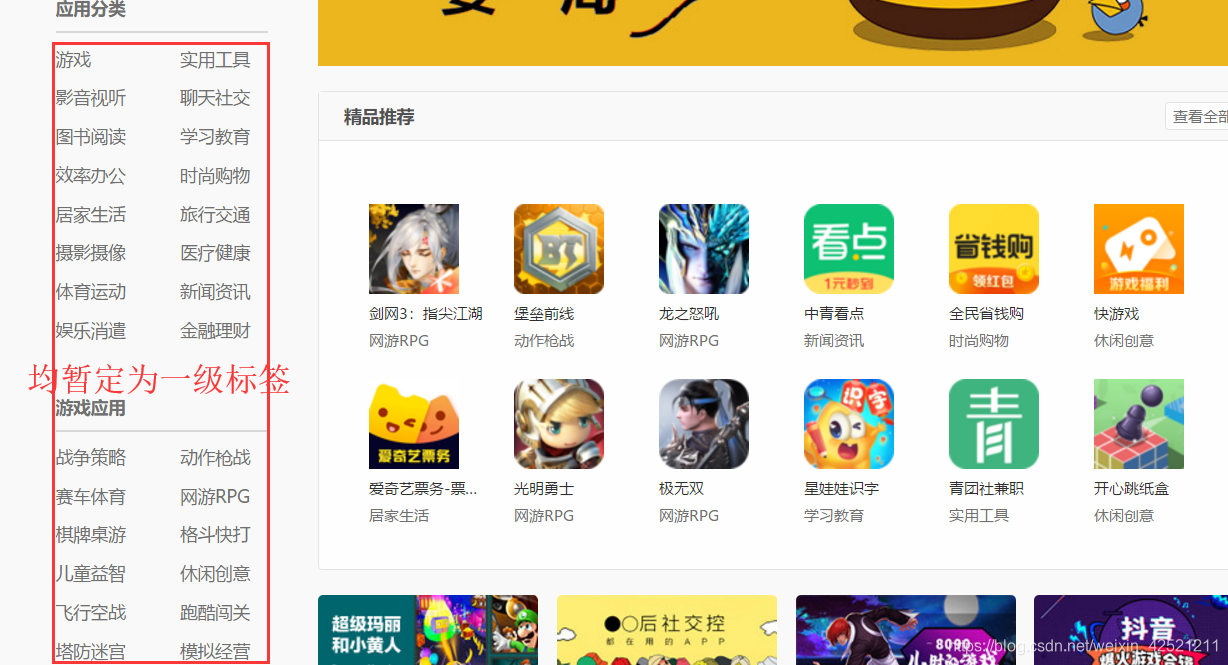
二、分析
针对页面的分类信息,通过查看页面源代码可知,分类的一级标签信息就嵌入在网页中,如下图所示:
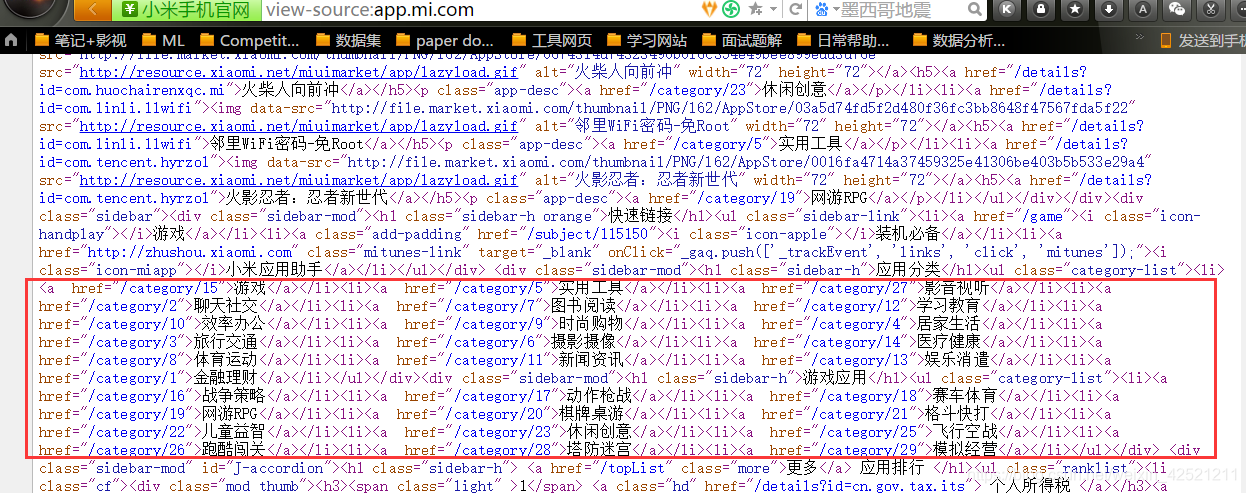
对于各一级标签下的app名称等信息,则单独在数据文件中,以下图数据为例:
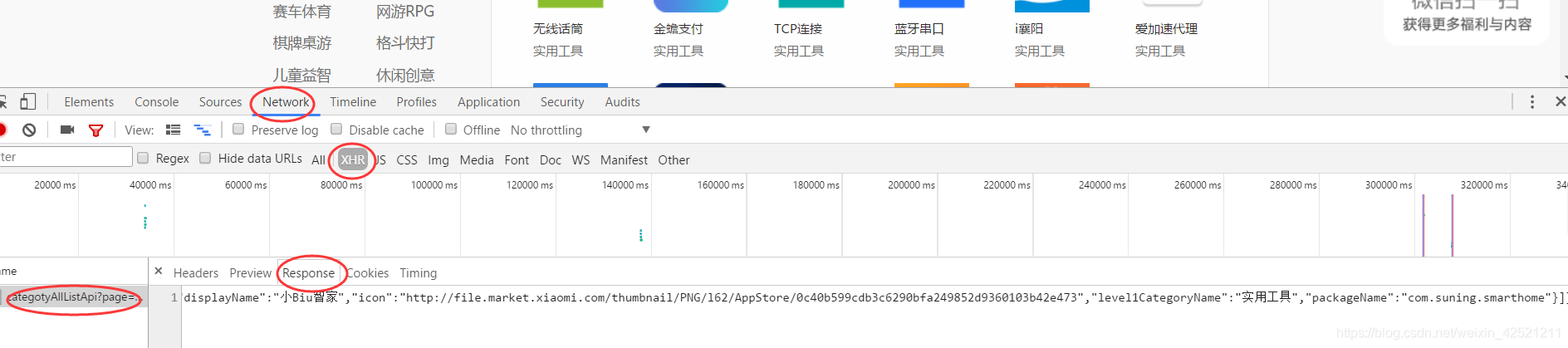
将response部分的数据,可以通过在线的json格式化工具处理,转换为比较容易分辨的格式,如下图所示:

可以很快的定位想要的数据的相关信息,另外,通过查看对比各个页面的【Request URL】,容易发现,URL变动部分的信息主要有下图标注的两处:

一个控制页面数,一个是一级标签分类对应的id。
分析清楚我们想要的数据的位置等信息,下面就开始我们的实战之旅!

三、python实现:获取应用app信息
我们对实现的各个功能,进行函数化打包。
获取指定页面的文本数据
import json
import pandas as pd
import requests
from bs4 import BeautifulSoup
def getUrlText(url):
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
'''
爬取网页的通用代码框架
'''
try:
r = requests.get(url,headers=headers,timeout=30)
r.raise_for_status() # 如果status_code不等于200,就抛出异常
r.encoding = r.apparent_encoding
return r.text
except:
print("产生异常")
'''
切换为手机模式爬的结果,有点问题
'''
# def getPageApp(pageConfigVersion):
# '''
# 获取指定pageConfigVersion的app信息
# '''
# result = [] # 存放结果
# url_left = r"https://app.market.xiaomi.com/apm/featured?stamp=0&os=1.1.1&model=unknown&ro=unknown&marketVersion=1914102&imei=cfcd208495d565ef66e7dff9f98764da&miuiBigVersionName=unknown&resolution=1080*1920&webResVersion=0&clientId=cfcd208495d565ef66e7dff9f98764da&densityScaleFactor=3&co=CN&pageConfigVersion=0&session=cfcd208495d565ef66e7dff9f98764da&deviceType=0&la=zh&sdk=19&mobileWeb=1&newUser=true&page="
# url_right = r"&combine=1&h5=1&supportSlide=4&refs=index"
# url = url_left+str(pageConfigVersion)+url_right
# first_text = getUrlText(url)
# first_data = json.loads(first_text)
# for i in range(1,len(first_data['list'])):
# detail_first = first_data['list'][i]
# try:
# listApps = detail_first['data']['listApp']
# except:
# continue
# for j in range(len(listApps)):
# detail_data =listApps[j]
# app_name = detail_data['displayName']
# app_first_level = detail_data['level1CategoryName']
# app_second_level = detail_data['level2CategoryName']
# result.append([app_first_level,app_second_level,app_name])
# return result
# results = []
# for p in range(5):
# r = getPageApp(p)
# print(len(r))
# results.extend(r)
# results = pd.DataFrame(results)
# results.drop_duplicates()
获取应用一级标签ID信息
def getCategoryID():
'''
返回值,列表:去除【游戏】的分类id列表
'''
origin_url = "http://app.mi.com/category/0"
origin_url_text = getUrlText(origin_url)
origin_soup = BeautifulSoup(origin_url_text,'lxml')
category_list = origin_soup.find_all('ul',class_="category-list")[0]
categorys = category_list.find_all('a')
category_id = [] # 存放id结果
for cate in categorys:
category_id.append(cate.attrs['href'].split('/')[-1])
return category_id
获取一级标签和对应的app名称
def getPageAppMessage():
'''
获取指定app信息
'''
url_left = r"http://app.mi.com/categotyAllListApi?page="
url_center = r"&categoryId="
url_right = r"&pageSize=30"
count = 0 # app计数
result = [] # 存储结果
categoryId = getCategoryID()
for cid in categoryId:
pageNum = 0 # 初值
flag = True # 页面循环标记,当无数据时标记为 False
while flag:
url = url_left+str(pageNum)+url_center + cid +url_right
url_text = getUrlText(url)
url_data = json.loads(url_text)
data = url_data['data']
if data:
for i in range(len(data)):
app_name = data[i]["displayName"]
app_first_level = data[i]['level1CategoryName']
result.append([app_first_level,app_name])
count +=1
print([app_first_level,app_name],count)
pageNum += 1 # 页面加1
else:
flag = False
print('一级标签:',app_first_level)
print('页面个数有:',pageNum)
print(cid)
return result
主程序
主程序,获取数据并将获取的数据保存在excel文件中。
if __name__=="__main__":
result = getPageAppMessage()
result = pd.DataFrame(result)
result = result.drop_duplicates()
result.columns = ['一级标签','app名称']
result.to_excel('xiaomiApp.xls',index=False,encoding='utf-8')
结果部分示例如下:
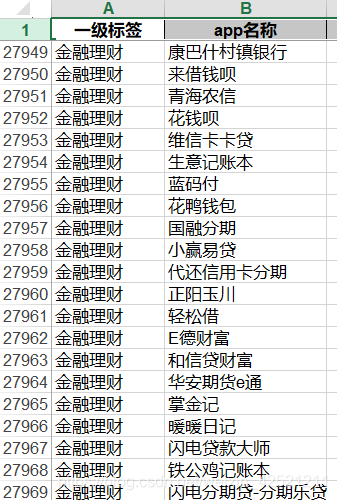

四、小结
可以参看我的另一篇博文: 《python爬取华为应用商城app的标签信息》 , 可以发现,这次定位数据位置的时候,没有将页面转换为手机模式,主要是因为自己在尝试的过程中,发现爬取的数据不全,具体原因还未明确。其实小米应用商店的app的分类,也是有二级的,另外,【游戏】同样与华为应用商城的游戏一样,多一个层级。
巩固下,再接再厉!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











