






先给大家提出一个新的存储需求:存储大量的数据,在查询方面提供更高的效率 。来请出我们今天要说的主角set。
可能大家会有个疑问,难道list不能满足吗?
list也可以存大量数据而且还有顺序,还能使用索引访问,但是list 的存储结构是链表的存储结构。而链表的存储效率是很低的,当你存大量数据,但是读取的效率慢。这样就违背了redis提高效率的初衷。所以我们就需要一个新的存储结构。能够保存大量的数据,高效的内部存储机制,便于高效查询 。
以下我们就开始介绍这种新的数据结构Set。
与hash存储结构完全相同,仅存储键,不存储值(nil),并且值是不允许重复的。将hash值的field字段变成我需要存的值,将value字段不存储,这样就可以存储大量的数据,而且底层采用的是hash表的数据,使查询也就更加快速。(如下图)
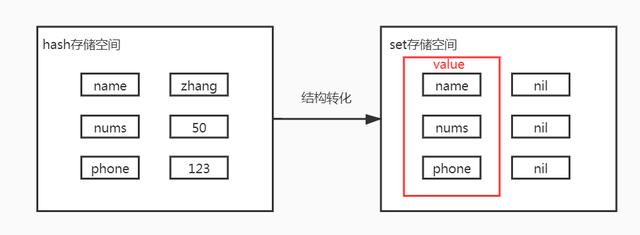
set 类型数据的基本操作
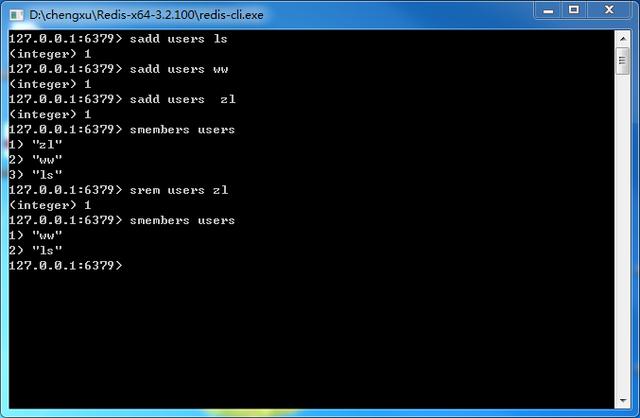
添加数据
sadd key member1 [member2]
获取全部数据
smembers key
删除数据
srem key member1 [member2]
获取集合数据总量
scard key
判断集合中是否包含指定数据
sismember key member

set 类型数据的扩展操作
1、用于数据的随机推荐,例如一些热点新闻,随机取出一些数据看你是否喜欢。如果你看了它下次还会给你进行这样的推荐。用以下命令可以实现随机获取一些数据的问题。
随机获取集合中指定数量的数据
srandmember key [count]
随机获取集合中的某个数据并将该数据移出集合
spop key [count]
2、 扩大业务圈或交际圈,比如你们有多少个公共的好友,你的好友还关注了谁等等。这就涉及到合集,并集,差集。
求两个集合的交、并、差集
sinter key1 [key2]
sunion key1 [key2]
sdiff key1 [key2]
求两个集合的交、并、差集并存储到指定集合中
sinterstore destination key1 [key2]
sunionstore destination key1 [key2]
sdiffstore destination key1 [key2]
将指定数据从原始集合中移动到目标集合中
smove source destination member
set 类型数据操作的注意事项
set 类型不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份
set 虽然与hash的存储结构相同,但是无法启用hash中存储值的空间。















 5342
5342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









