






在这里我选用4台机器进行示范,各台机器的职责如下表格所示
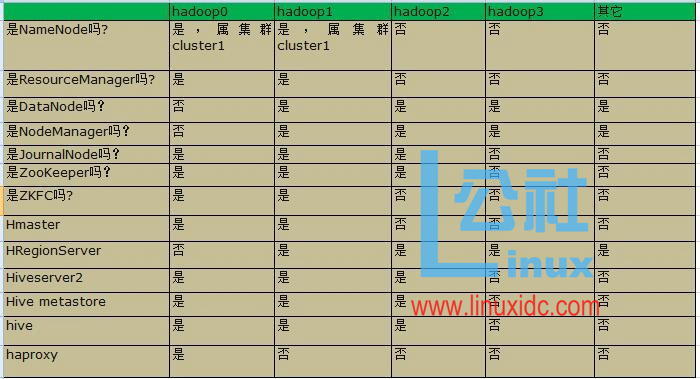
(说明: 1. ZooKeepe使用其它节点的 2. Hadoop0节点安装所有的master, ha的matster全部是worker, 以达到较高的资源利用率,又对master的负载不会过高)
Hadoop0 -> dchadoop206
Hadoop1 -> dchadoop207
Hadoop2 -> dchadoop208
Hadoop3 -> dchadoop209
1. 搭建自动HA
1.1. 复制编译后的hadoop项目到/usr/local目录下
1.2. 修改位于etc/hadoop目录下的配置文件
1.1.1. hadoop-env.sh
export Java_HOME=/usr/local/jdk
1.1.1. core-site.xml
fs.defaultFS
hdfs://cluster1
【这里的值指的是默认的HDFS路径。当有多个HDFS集群同时工作时,用户如果不写集群名称,那么默认使用哪个哪?在这里指定!该值来自于hdfs-site.xml中的配置。在节点hadoop0和hadoop1中使用cluster1,在节点hadoop2和hadoop3中使用cluster2】
hadoop.tmp.dir
/data0/hadoop/tmp
【这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录。】
ha.zookeeper.quorum
hadoop0:2181,hadoop1:2181,hadoop2:2181
【这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点】
1.1.1. hdfs-site.xml
该文件只配置在hadoop0和hadoop1上。
dfs.replication
2
【指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可。】
dfs.namenode.name.dir
file:///data0/hadoop2/hdfs/name
【指定namenode元数据信息存储位置】
dfs.datanode.data.dir file:///data0/hadoop2/hdfs/data,file:///data1/hadoop2/hdfs/data,file:///data2/hadoop2/hdfs/data,file:///data3/hadoop2/hdfs/data,file:///data4/hadoop2/hdfs/data,file:///data5/hadoop2/hdfs/data,file:///data6/hadoop2/hdfs/data,file:///data7/hadoop2/hdfs/data,file:///data8/hadoop2/hdfs/data,file:///data9/hadoop2/hdfs/data,file:///data10/hadoop2/hdfs/data
【指定datanode元数据信息存储位置, 设置成所有的磁盘】
dfs.nameservices
cluster1
【设置cluster1的namenode id。】
dfs.ha.namenodes.cluster1
hadoop0,hadoop1
【指定NameService是cluster1时的namenode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可】
dfs.namenode.rpc-address.cluster1.hadoop0
hadoop0:9000
【指定hadoop0的RPC地址】
1234
dfs.namenode.http-address.cluster1.hadoop0
hadoop0:50070
【指定hadoop0的http地址】
1234
dfs.namenode.rpc-address.cluster1.hadoop1
hadoop1:9000
【指定hadoop1的RPC地址】
dfs.namenode.http-address.cluster1.hadoop1
hadoop1:50070
【指定hadoop1的http地址】
dfs.namenode.shared.edits.dir
qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster1
【指定cluster1的两个NameNode共享edits文件目录时,使用的JournalNode集群信息】
dfs.ha.automatic-failover.enabled.cluster1
true
【指定cluster1是否启动自动故障恢复,即当NameNode出故障时,是否自动切换到另一台NameNode】
dfs.client.failover.proxy.provider.cluster1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
【指定cluster1出故障时,哪个实现类负责执行故障切换】
dfs.journalnode.edits.dir
/data0/hadoop2/hdfs/journal
【指定JournalNode集群在对NameNode的目录进行共享时,自己存储数据的磁盘路径】
dfs.ha.fencing.methods
sshfence
【一旦需要NameNode切换,使用ssh方式进行操作】
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
【如果使用ssh进行故障切换,使用ssh通信时用的密钥存储的位置】
1.2.4. slaves
hadoop1
hadoop2
hadoop2
1.3. 把以上配置的内容复制到hadoop1、hadoop2、hadoop3节点上
1.4. 修改hadoop1、hadoop2、hadoop3上的配置文件内容
1.4.1. 修改hadoop2上的core-site.xml内容
fs.defaultFS的值改为hdfs://cluster2
1.4.1. 修改hadoop2上的hdfs-site.xml内容
把cluster1中关于journalnode的配置项删除,增加如下内容
dfs.namenode.shared.edits.dir
qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster2
1.4.3. 开始启动
1.4.3.1. 启动journalnode
在hadoop0、hadoop1、hadoop2上执行
sbin/hadoop-daemon.sh startjournalnode
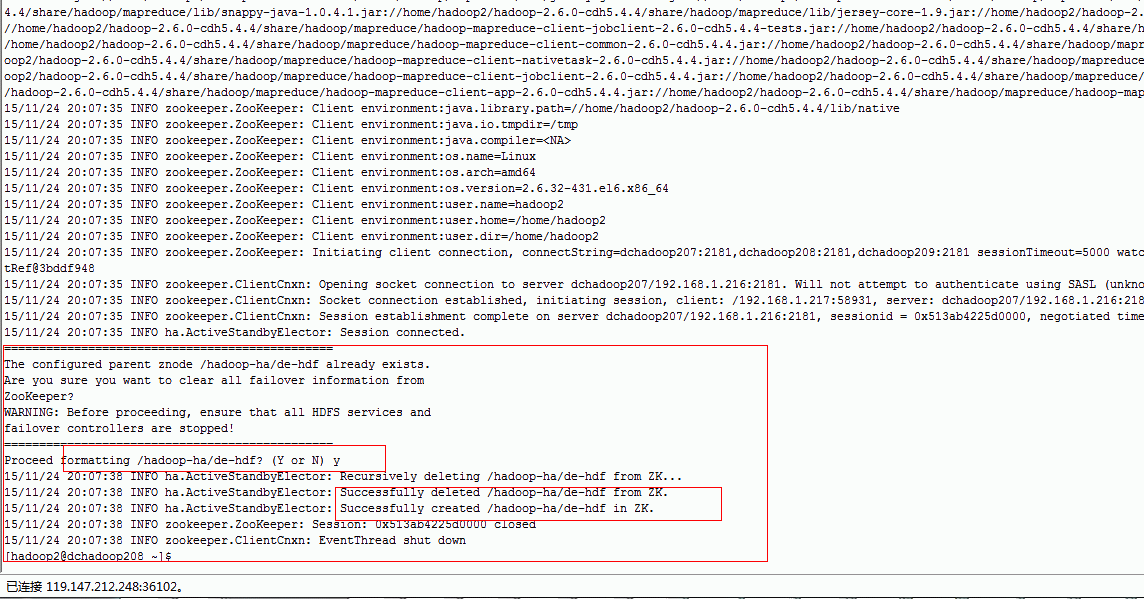
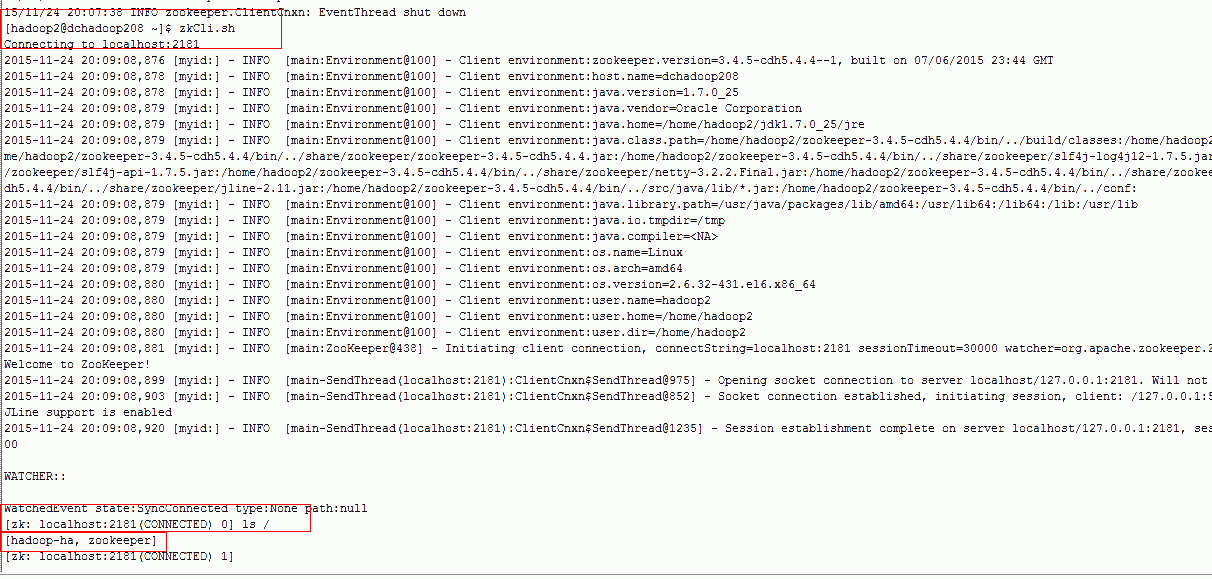
1.4.3.1. 格式化ZooKeeper
在hadoop0、hadoop2上执行
bin/hdfs zkfc -formatZK
zkCli.sh-->ls->/Hadoop-ha/cluster1
1.4.3.3. 对hadoop0节点进行格式化和启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
1.4.3.4. 对hadoop1节点进行格式化和启动
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
1.4.3.5. 在hadoop0、hadoop1上启动zkfc
1 sbin/hadoop-daemon.sh start zkfc
我们的hadoop0、hadoop1有一个节点就会变为active状态。
1.4.3.6. 对于cluster2执行类似操作
1.4.4. 启动datanode
在hadoop0上执行命令
sbin/hadoop-daemons.sh start datanode
1.5. 配置Yarn
1.5.1. 修改文件mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop0:10020
mapreduce.jobhistory.webapp.address
hadoop0:19888
mapreduce.task.io.sort.factor
20
The number of streams to merge at once while sorting
files. This determines the numberof open file handles.
mapreduce.reduce.shuffle.parallelcopies
40
The default number of parallel transfers run byreduce
during the copy(shuffle) phase.
mapreduce.job.reduce.slowstart.completedmaps
0.80
Fraction of the number of maps in the job whichshould be
complete before reduces are scheduled for the job.
mapreduce.task.io.sort.mb
300
The total amount of buffer memory to use whilesorting
files, in megabytes. By default,gives each merge stream 1MB, which
should minimize seeks.
mapreduce.map.output.compress
true
Should the outputs of the maps be compressed beforebeing
sent across the network. UsesSequenceFile compression.
mapreduce.client.submit.file.replication
5
默认10,The replication level for submitted job files. This
should be around thesquare root of the number of nodes.
1.5.2. 修改文件yarn-site.xml
yarn.resourcemanager.ha.enabled
true
【打开resourcemanager ha模式】
yarn.resourcemanager.cluster-id
yarn-ha-cluster
【打开resourcemanager ha的集群名称,这个名称可以在zookeeper中查看】
yarn.resourcemanager.ha.rm-ids
rm1,rm2
【设置resourcemanager的id,可以与主机同名】
yarn.resourcemanager.hostname.rm1
hadoop0
【指定rm1对应哪一台主机】
yarn.resourcemanager.hostname.rm2
hadoop1
【指定rm1对应哪一台主机】
yarn.resourcemanager.zk-address
zk1:2181,zk2:2181,zk3:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.scheduler.classorg.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
yarn.nodemanager.resource.memory-mb
28672
【设置nodemanager节点内存大小 28G】
yarn.nodemanager.resource.cpu-vcores
14
【设置nodemanager节点内存大小 14个core】
yarn.timeline-service.enabled
true
【打开timeline服务】
1.5.3 修改环境变量(可以不改,使用默认配置)
1.5.3.1 修改 yarn-env.sh
YARN_LOG_DIR=/data0/hadoop2/logs
【修改yarn的日志目录,默认在$HADOOP_HOME/logs下】
1.5.3.2 修改hadoop-env.sh
1 export JAVA_HOME=/usr/java/jdk1.7.0_25
【修改jdk】
export HADOOP_LOG_DIR=/data0/hadoop2/logs
【修改hadoop的日志目录,默认在$HADOOP_HOME/logs下】
export HADOOP_PID_DIR=/data0/hadoop2/pid
【修改hadoop pid目录】
1.5.5 修改capacity-scheduler.xml这个文件 (可选 ,设置调度器为CapacityScheduler时,可以通过这个配置文件修改作业队列)
yarn.scheduler.capacity.resource-calculator
org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
yarn.scheduler.capacity.maximum-am-resource-percent
0.9
【appMaster可以使用集群多少资源】
yarn.scheduler.capacity.schedule-asynchronously.enable
true
yarn.scheduler.capacity.root.queues
default,dev
yarn.scheduler.capacity.root.dev.capacity
50
【设置队列dev的能力大小占集群的50%】
yarn.scheduler.capacity.root.default.capacity
50
【设置队列default的能力大小占集群的50%】
1.5.4 启动yarn
在hadoop0上执行
sbin/start-yarn.sh
下面关于Hadoop的文章您也可能喜欢,不妨看看:
















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









