







简介:Apache Commons IO库为Java I/O操作提供支持,包括文件操作、流优化及文件系统监控等。而commons-fileupload组件则专门用于处理HTTP文件上传。文章将详细介绍这两个库的核心功能,以及它们在Web应用开发中的协同工作和最佳实践。掌握这些库能有效简化Java文件处理和提升Web应用的安全性与效率。 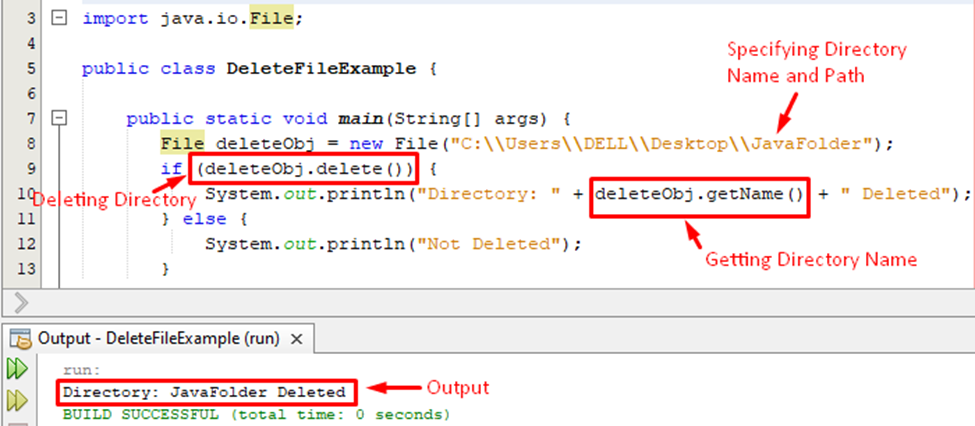
1. commons-io库概述及核心功能介绍
Apache Commons IO 是一个开源的 Java 库,它提供了一系列用于文件处理和输入输出操作的工具类和方法。这个库是由 Apache Software Foundation 提供支持,它大大简化了文件操作的复杂性,并提高了代码的可重用性。
1.1 commons-io库的发展与版本更新
自 Apache Commons IO 库推出以来,已经经历了多个版本的更新,每个新版本都会带来新的功能和性能的优化。对于开发者来说,了解这些更新是掌握库最新特性的重要途径。
1.2 commons-io库中的核心类和方法
库中的核心类如 IOUtils 和 FileUtils 提供了对文件及流操作的基本支持。比如 IOUtils 提供了处理输入输出流的便捷方法,而 FileUtils 则是对文件系统进行操作的高级封装,包括文件的读取、创建、复制和删除等。
在下一章中,我们将深入探讨 FileUtils 类的文件操作功能,揭示其如何简化文件系统操作的复杂性。
2. 深入FileUtils与文件系统操作
2.1 FileUtils类的文件操作功能
2.1.1 文件拷贝与移动
FileUtils 类在 commons-io 库中是一个非常实用的工具类,提供了丰富的方法来进行文件的拷贝与移动操作。对于大多数文件操作来说, FileUtils.copyFile(File srcFile, File destFile) 方法足够使用,它会将源文件拷贝到目标路径。如果目标文件已存在,会先删除已存在的文件再进行拷贝。
对于需要覆盖拷贝的情况,可以使用 FileUtils.copyFileToDirectory(File srcFile, File destDir) 方法,将文件拷贝到指定的目录下。此外,还有 copyFileToDirectory(File srcFile, File destDir, boolean preserveFileDate) 和 copyFile(File srcFile, File destFile, boolean preserveFileDate) 两个方法,可以根据需要选择是否保留文件的修改时间。
实现示例代码
``` mons.io.FileUtils;
public class FileUtilsExample { public static void main(String[] args) { File srcFile = new File("source.txt"); File destFile = new File("destination.txt"); try { // 拷贝文件,不保留原始文件时间 FileUtils.copyFile(srcFile, destFile); // 将文件拷贝到指定目录,保留文件时间 File destDir = new File("target_directory"); FileUtils.copyFileToDirectory(srcFile, destDir, true); } catch (IOException e) { e.printStackTrace(); } } }
在实际应用中,对于大型文件的拷贝,我们需要考虑性能与内存消耗的问题。如果直接使用`FileUtils.copyFile`,它会将文件内容一次性读入内存,这对于大文件来说是不现实的。为了解决这个问题,可以使用`FileUtils.copyFile(File srcFile, OutputStream output)`或`FileUtils.copyFile(InputStream input, File destFile)`,这两个方法允许我们通过流的方式控制数据的读写,有效避免内存溢出的风险。
### 2.1.2 文件创建与删除
`FileUtils`类提供了便捷的API来处理文件的创建与删除。
- 创建文件:`FileUtils.touch(File file)`方法可以创建一个空文件,如果文件已存在,此方法会将文件的最后修改时间更新为当前时间。如果需要创建一组文件,则可以使用`FileUtils.touch(File... files)`方法。
- 删除文件:`FileUtils.deleteQuietly(File file)`方法可以删除指定的文件或目录。与标准的`File.delete()`方法相比,`deleteQuietly()`在删除文件时不会抛出异常,这对于批量删除操作特别有用,当遇到无法删除的文件时,也不会阻止整个操作的继续执行。
#### 实现示例代码
```***
***mons.io.FileUtils;
public class FileUtilsExample {
public static void main(String[] args) {
File file = new File("example.txt");
try {
// 创建文件
FileUtils.touch(file);
// 删除文件
FileUtils.deleteQuietly(file);
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.1.3 文件夹的创建和遍历
文件夹的创建可以使用 FileUtils.forceMkdir(File directory) 方法,此方法会确保指定的目录被创建,如果父目录不存在,会一并创建。 forceMkdir 方法还能够解决权限不足的问题,即使在无法创建目录的情况下,也不会抛出异常。
遍历文件夹时,可以使用 FileUtils.iterateFiles(File directory, String[] extensions, boolean recursive) 方法,这个方法会遍历指定目录下的所有文件,返回一个文件列表。可以指定文件扩展名过滤,以及是否递归遍历子目录。
实现示例代码
``` mons.io.FileUtils; ***mons.io.filefilter.WildcardFileFilter;
import java.io.File; import java.io.IOException; import java.util.List;
public class FileUtilsExample { public static void main(String[] args) { File dir = new File("my_directory"); try { // 创建目录 FileUtils.forceMkdir(dir); // 遍历目录 List files = FileUtils.iterateFiles(dir, new String[]{"txt", "doc"}, true) .collect(Collectors.toList()); files.forEach(System.out::println); } catch (IOException e) { e.printStackTrace(); } } }
### 2.1.4 代码逻辑解读分析
在使用`FileUtils`进行文件操作时,需注意以下几点:
1. `FileUtils.copyFile`等方法在操作文件时可能抛出`IOException`异常,因此要适当处理。
2. 对于大文件操作,应当使用基于流的方法来避免内存溢出。
3. 使用`FileUtils.deleteQuietly`时,应确认它没有隐藏掉一些需要处理的异常,如权限问题导致的删除失败。
4. 在进行文件遍历时,要小心处理`WildCardFileFilter`中定义的过滤规则,确保不会出现意料之外的文件被错误处理。
理解了这些操作逻辑后,开发者可以更安全高效地利用`FileUtils`类进行文件系统的操作。
# 3. 高效流操作与文件系统监控
## 3.1 InputStream与OutputStream工具类使用
### 3.1.1 高效读写数据流的技巧
在处理文件和网络通信时,高效的数据流操作至关重要。`InputStream` 和 `OutputStream` 是 Java I/O 中用于处理字节流的两个核心类。要实现高效的数据读写,首先需要理解数据流的基本概念以及如何正确使用缓存。
使用 `BufferedInputStream` 和 `BufferedOutputStream` 可以大大提高数据读写的效率。这两个类通过内部缓冲区来减少对底层流的调用次数,从而减少系统调用开销。在处理大文件时,这种优化尤其重要。
```java
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class BufferingExample {
public static void main(String[] args) {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("sourcefile.bin"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("destfile.bin"))) {
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = bis.read(buffer)) != -1) {
bos.write(buffer, 0, bytesRead);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
在上述代码中,通过使用缓冲流,我们提高了读写操作的性能。 BufferedInputStream 和 BufferedOutputStream 实例化后,它们会在内部使用固定大小的缓冲区。 read 方法会从底层流中读取数据填充到缓冲区中,然后返回缓冲区中的数据,这样就可以减少实际的磁盘 I/O 操作次数。同样的, write 方法会先将数据写入到缓冲区,然后当缓冲区满时,一次性将数据写入到底层流中。
3.1.2 缓冲机制与性能提升
除了使用缓冲流外,还可以通过调整缓冲区大小来进一步优化性能。默认情况下,缓冲区的大小对于 BufferedInputStream 和 BufferedOutputStream 是 8192 字节,但这个值可以根据实际情况调整。如果读写操作的块大小不是很大,可以适当减小缓冲区大小以减少内存使用;如果使用大块数据,则增大缓冲区大小可能会带来更好的性能。
// 修改缓冲区大小为 4096 字节
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("sourcefile.bin"), 4096);
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("destfile.bin"), 4096);
3.1.3 实际性能测试
为了衡量性能提升,我们可以进行简单的基准测试。基准测试应当在相似的条件下重复执行多次,并取平均值。测试可以涉及数据的读取次数、写入次数、总字节处理量等关键指标。
// 这里省略实际的性能测试代码,仅展示逻辑框架
public class PerformanceTest {
public static void main(String[] args) {
// 初始化文件大小、测试次数等参数
int fileSize = ...;
int testRepetitions = ...;
for (int i = 0; i < testRepetitions; i++) {
// 记录开始时间
long startTime = System.currentTimeMillis();
// 执行数据读写操作
// ...
// 记录结束时间
long endTime = System.currentTimeMillis();
// 计算并记录性能指标,如总耗时
long duration = endTime - startTime;
// 输出结果或记录到日志
// ...
}
}
}
性能测试的结果将帮助我们了解缓冲机制的优化效果,并为实际应用提供参考数据。
3.2 FileWatcher监控机制详解
3.2.1 实时监控文件变化的实现方式
文件监控是程序中一个非常实用的功能,允许应用程序响应文件或目录的变化。 commons-io 提供了 FileAlterationObserver 和 FileAlterationMonitor 来实现这一功能。
``` mons.io监视.FileAlterationObserver; mons.io监视.FileAlterationMonitor; mons.io监视.FileAlterationListener; ***mons.io监视.FileChangedEvent; import java.io.File;
public class FileWatcherExample { public static void main(String[] args) { File directory = new File("/path/to/directory"); FileAlterationObserver observer = new FileAlterationObserver(directory); observer.addListener(new FileAlterationListener() { @Override public void onFileChange(FileChangedEvent fce) { // 处理文件变化事件 System.out.println("文件 " + fce.getFile() + " 已被修改。"); } @Override public void onDirectoryChange(FileChangedEvent fce) { // 处理目录变化事件 System.out.println("目录 " + fce.getFile() + " 已被修改。"); }
@Override
public void onFileCreate(FileChangedEvent fce) {
// 处理文件创建事件
System.out.println("文件 " + fce.getFile() + " 已被创建。");
}
@Override
public void onDirectoryCreate(FileChangedEvent fce) {
// 处理目录创建事件
System.out.println("目录 " + fce.getFile() + " 已被创建。");
}
@Override
public void onFileDelete(FileChangedEvent fce) {
// 处理文件删除事件
System.out.println("文件 " + fce.getFile() + " 已被删除。");
}
@Override
public void onDirectoryDelete(FileChangedEvent fce) {
// 处理目录删除事件
System.out.println("目录 " + fce.getFile() + " 已被删除。");
}
});
FileAlterationMonitor monitor = new FileAlterationMonitor(1000, observer); // 检查间隔为 1 秒
monitor.start();
// ... 运行一段时间后,停止监控器
monitor.stop();
}
}
在上述代码中,通过创建 `FileAlterationObserver` 来监视一个特定目录,并在该目录下发生任何文件或子目录的变化时调用相应的回调函数。而 `FileAlterationMonitor` 则负责周期性的检查指定的 `FileAlterationObserver` 是否有变化发生。
### 3.2.2 监控事件处理与应用案例
在实际应用中,文件监控可用于多种场景,例如:
- **日志文件监控**:系统在运行时,自动检测日志文件的变化,实时读取新内容并进行处理。
- **文件上传/下载服务**:监控上传/下载目录,自动处理新上传或下载完成的文件。
- **数据库数据备份**:当数据库的文件发生变化时,触发备份操作。
下面是一个日志文件监控的示例:
```java
public class LogFileMonitor {
public static void main(String[] args) {
File logDirectory = new File("/path/to/log/files");
FileAlterationObserver observer = new FileAlterationObserver(logDirectory);
observer.addListener(new FileAlterationListener() {
@Override
public void onFileChange(FileChangedEvent fce) {
// 处理日志文件变化事件
processLogFile(fce.getFile());
}
// 其他事件处理略...
});
FileAlterationMonitor monitor = new FileAlterationMonitor(5000, observer); // 检查间隔为 5 秒
monitor.start();
// ... 运行一段时间后,停止监控器
monitor.stop();
}
private static void processLogFile(File logFile) {
// 实现读取日志文件并进行处理的逻辑
// ...
}
}
这个例子中,我们定义了一个 LogFileMonitor 类用于监视日志目录。一旦日志文件发生变化, onFileChange 方法会被调用,并触发 processLogFile 方法来处理文件内容。
在实际应用中,监控机制还可以结合多线程或异步处理技术,进一步优化性能,确保监控机制对主应用的影响降到最低。
graph TD;
A[启动监控器] --> B{监控间隔}
B --> |1秒|C[检查文件变化]
B --> |5秒|D[检查文件变化]
C --> |文件变化|E[处理文件变化]
D --> |文件变化|E
E --> F[回调方法]
F --> |日志变化|G[处理日志]
F --> |其他变化|H[根据变化处理]
G --> I[通知或日志记录]
H --> I
通过这种方式,我们可以灵活地实现多种文件监控场景,以适应不同的业务需求。
4. 高级功能探索与实践应用
4.1 EndianUtils与字节序处理
字节序是计算机存储和网络传输中非常关键的概念,它决定了多字节数据的存储和传输顺序。常见的字节序包括大端序(Big Endian)和小端序(Little Endian)。
4.1.1 字节序的基础知识
字节序描述了多字节数据的排列顺序,尤其是在内存中的组织方式。例如,一个16位的整数0x1234在不同的字节序中会以不同的方式存储:
- 在大端序中,0x12会存储在最低的内存地址。
- 在小端序中,0x34会存储在最低的内存地址。
这种差异对于开发者来说很重要,尤其是在编写网络协议或二进制文件处理代码时,必须保证发送方和接收方在字节序上达成一致。
4.1.2 EndianUtils的使用场景与优势
Apache Commons IO库中的EndianUtils类提供了方便的方法来处理字节序转换,它可以帮助开发者在大端和小端之间轻松转换数据。
该类通常用于以下场景:
- 网络编程:在网络协议中,统一的字节序是必要的,否则数据将被错误解读。
- 文件格式处理:在处理特定的文件格式时,比如某些音频或图像文件格式,需要按照特定的字节序来解析数据。
- 硬件接口:与硬件设备交互时,硬件可能期望特定的字节序格式的数据。
使用EndianUtils的优势包括:
- 简单易用 :提供了一套简洁的API来处理字节序转换,使开发者可以轻松处理跨平台的字节序问题。
- 效率高 :在内部通过位操作来实现转换,相比手动循环可以提供更好的性能。
- 安全性 :减少了因手动处理字节序不当导致的bug和数据损坏问题。
下面是一个使用EndianUtils进行字节序转换的代码示例:
``` mons.io.EndianUtils; import java.io.IOException;
public class EndianExample { public static void main(String[] args) throws IOException { short number = (short) 0x1234; byte[] bytes = new byte[2]; EndianUtils.putShortBigEndian(bytes, 0, number); // 此时bytes[0] == 0x12, bytes[1] == 0x34
short retrievedNumber = EndianUtils.getShortBigEndian(bytes, 0);
// retrievedNumber 现在是0x1234
}
}
## 4.2 HexDump在数据调试中的应用
### 4.2.1 字节数据与十六进制转换原理
在数据调试过程中,将字节数据转换为十六进制表示是一种常见且有用的手段。十六进制表示允许开发者以更易于理解的方式来查看和分析二进制数据。
一个字节可以表示为两个十六进制数字,因为它可以涵盖从00到FF的值(0到255十进制)。例如,十进制数 10 在二进制中为 1010,在十六进制中则表示为 A。
### 4.2.2 HexDump在故障排查中的实操
HexDump工具通常用于将字节数据以十六进制形式输出,这在调试过程中非常有用,尤其是当需要查看二进制文件或数据流内容时。Apache Commons IO库提供了一个名为HexDump的类,能够方便地实现这一功能。
HexDump类的一些应用场景包括:
- **二进制文件分析**:检查二进制文件的内容,查看是否有损坏或异常的部分。
- **网络数据包检查**:在开发网络应用时,可以通过HexDump来分析网络数据包的内容。
- **日志记录**:将数据转换为十六进制形式记录到日志中,有助于后续的分析和问题定位。
接下来的示例展示了如何使用HexDump类将字节数组内容以十六进制形式打印到控制台:
```***
***mons.io.HexDump;
import java.io.IOException;
public class HexDumpExample {
public static void main(String[] args) throws IOException {
byte[] data = new byte[] {0x01, 0x02, 0x03, 0x04};
// 打印十六进制dump到控制台
HexDump.dump(data, 0, System.out, 0);
}
}
在实际的应用中,HexDump还可以结合异常处理逻辑、文件I/O操作以及与其他数据处理工具的交互来完成更复杂的调试任务。例如,可以在捕获到特定异常时自动将相关数据流的内容转储为十六进制形式,便于开发人员快速定位问题源头。
以上实例展示了字节序处理和数据调试的高级用法,通过工具类简化了常见的编程任务,并提供了清晰的展示与分析手段,进而提升开发效率和问题解决能力。
5. 文件上传组件与最佳实践
在现代的Web应用开发中,文件上传是一个非常常见的需求。无论是用户头像上传、资料上传还是其它多媒体内容上传,都需要后端提供一个稳定的文件上传解决方案。Apache Commons IO库为我们提供了方便使用的文件上传组件,如 DiskFileItemFactory 和 ServletFileUpload ,本文将深入探讨如何配置和使用这些组件来实现一个高效、安全的文件上传功能。
5.1 DiskFileItemFactory与临时存储管理
在进行文件上传操作时,上传的文件首先需要被存储在服务器的临时位置。 DiskFileItemFactory 是处理文件上传时创建临时存储和文件项的工具类。使用这个类可以有效管理临时文件存储。
5.1.1 临时文件管理的必要性
临时文件的存储通常用于在文件上传完成之前暂存数据。由于上传的文件可能很大,临时文件管理就显得尤为重要。合理管理临时文件可以防止磁盘空间耗尽或服务器内存溢出,从而保证服务器的稳定运行。
5.1.2 配置DiskFileItemFactory的最佳实践
配置 DiskFileItemFactory 涉及几个关键参数,如下所示:
DiskFileItemFactory factory = new DiskFileItemFactory();
// 设置临时文件目录
factory.setRepository(new File("path/to/temporary/directory"));
// 设置单个文件大小的阈值,超过这个阈值的文件将会被存储到磁盘上
factory.setSizeThreshold(1024 * 1024);
在配置 DiskFileItemFactory 时,应注意以下几点:
- 临时目录路径 :应选择服务器有足够空间的目录,且应设置适当的读写权限。
- 大小阈值 :默认情况下,所有文件都会被存储在内存中,这可能会导致内存溢出。通过设置大小阈值,超过该值的文件将被存储到磁盘上,从而减少内存的压力。
5.2 ServletFileUpload与FileItem解析器
ServletFileUpload 是一个解析器类,用于解析 multipart/form-data 类型的HTTP请求,即将上传的文件和其它表单数据分离,并封装为 FileItem 对象,供后续处理。
5.2.1 解析HTTP请求中的文件
使用 ServletFileUpload 解析HTTP请求中的文件非常简单,下面是一个基本的示例:
// 创建ServletFileUpload对象
ServletFileUpload upload = new ServletFileUpload(factory);
// 解析请求
List<FileItem> formItems = upload.parseRequest(request);
5.2.2 FileItem的高级用法
每个 FileItem 对象代表了一个表单字段或文件。 FileItem 提供了多种方法来获取数据:
-
getName():获取上传文件的名称 -
getInputStream():获取文件内容的输入流 -
delete():删除临时文件 -
getFieldName():获取表单字段的名称 -
isFormField():判断是否为表单字段而非文件
在处理文件上传时,应注意以下几点:
- 检查上传的文件大小和类型,确保它们符合应用的要求。
- 对上传的文件进行重命名,以避免潜在的安全风险,如文件名冲突和路径遍历攻击。
5.3 文件上传的完整工作流程
实现文件上传功能时,要确保整个上传流程的安全性和高效性。从接收到上传请求到文件存储,需要考虑的环节很多。
5.3.1 从上传到保存的协同工作
完整的文件上传流程大致如下:
- 初始化
DiskFileItemFactory和ServletFileUpload。 - 解析HTTP请求,获取
FileItem列表。 - 遍历
FileItem列表,根据是文件还是表单字段进行相应处理。 - 对于文件类型的
FileItem,进行安全性检查,然后保存到服务器的指定位置。 - 清理临时文件,避免产生垃圾文件。
5.3.2 文件上传安全性与稳定性的最佳实践
在文件上传的过程中,安全性尤为重要,以下是一些最佳实践:
- 对上传的文件进行严格的检查,如文件类型、大小、是否含有病毒等。
- 设置文件上传的大小限制,防止恶意的大文件上传导致服务器资源耗尽。
- 确保文件保存的目录安全,避免用户通过上传的文件访问到敏感目录。
- 在处理文件上传失败的情况时,提供清晰的错误信息,并保证临时文件的清理工作。
通过以上步骤,我们可以构建一个既安全又高效的文件上传组件,满足Web应用中的文件上传需求。
简介:Apache Commons IO库为Java I/O操作提供支持,包括文件操作、流优化及文件系统监控等。而commons-fileupload组件则专门用于处理HTTP文件上传。文章将详细介绍这两个库的核心功能,以及它们在Web应用开发中的协同工作和最佳实践。掌握这些库能有效简化Java文件处理和提升Web应用的安全性与效率。

















 1294
1294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









