







Mention-Ranking Model :
训练目标:
采用 1 个全连接层,将 mention-pair encoder 的输出作为输入,用于预先进行和表述 m 的共指可能性 sm(a,m) :

设: 训练数据包含 N 个 mention :
第 i 个 mention 的候选先行语集合为: ![]()
第 i 个 mention 的共指先行语集合为:![]()
定义 ![]() 为与 mi 共指可能性最高的共指先行语。
为与 mi 共指可能性最高的共指先行语。
启发式损失(heuristic loss)函数定义:
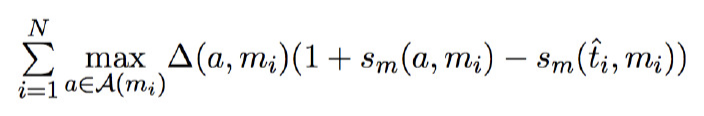
其中:
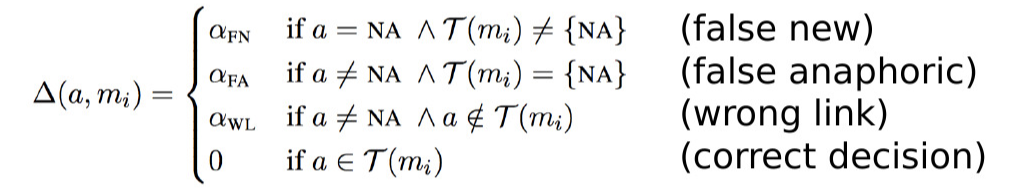
" I vote for Nader because he was most aligned with my values," she said.
几种错误类型:

其中第三种错误是最坏的,根据不同的错误类型,在训练时乘上不同的惩罚系数。
寻找合适的错误惩罚参数 :
采用 grid search ,对 {0.1,0.2,...,1.5}取值范围进行搜索,最终找到最优方案:
best for English : ![]()
best for Chinese : ![]()
网络训练细节 :
优化算法: RMS-Prop
采用 L2 正则化,0.5 概率的 dropout















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









