







如图所示,nexus 正常运行,但产生了大量的状态不明的 pod,原因也无从所知
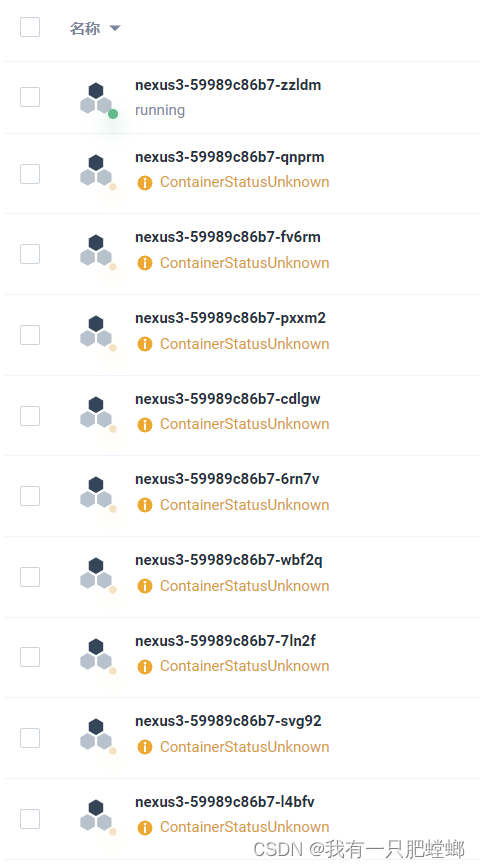
解决办法,删除多余的 pod,一个一个删除,非常费劲
- 获取 namespace 中状态为 ContainerStatusUnknown 的 pod,并删除
kubectl get pods -n [namespace] | grep ContainerStatusUnknown | awk '{print $1}' | xargs kubectl delete pod -n [namespace]
获取所有非 Running 状态下的 pod,并删除
kubectl get pods -A | grep -v Running | awk '{print $2}' | xargs kubectl delete pod -n kubesphere-system















 4943
4943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









