







最近无意间看到一个MySQL分页优化的测试案例,并没有非常具体地说明测试场景的情况下,给出了一种经典的方案,
因为现实中很多情况都不是固定不变的,能总结出来通用性的做法或者说是规律,是要考虑非常多的场景的,
同时,面对能够达到优化的方式要追究其原因,同样的做法,换了个场景,达不到优化效果的,还要追究其原因。
个人对此场景在不用情况表示怀疑,然后自己测试了一把,果然发现一些问题,同时也证实了一些预期的想法。
本文就MySQL分页优化,从最最简单的情况出发,来做一个简单的分析。
另:本文测试环境是最最低配置的云服务器,相对来说服务器硬件环境有限,不过对于不同的语句(写法)应该是“平等的”
MySQL经典的分页“优化”做法
MySQL分页优化中,有一种经典的问题,在查询越“靠后”的数据越慢(取决于表上的索引类型,对于B树结构的索引,SQL Server中也一样)
select * from t order by id limit m,n。
也即随着M的增大,查询同样多的数据,会越来越慢
面对这一问题,于是就产生了一种经典的做法,类似于(或者变种)如下的写法
就是先把分页范围内的id单独找出来,然后再跟基表做关联,最后查询出来所需要的数据
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
这种做法是不是总是生效的,或者说是在什么情况下后者才能到达到优化的目的?有没有做了改写之后无效甚至变慢的情况?
与此同时,绝大多数查询都是有筛选条件的,
如果有筛选条件的情况,
sql语句就变成了select * from t where *** order by id limit m,n
如果如法炮制,改写成类似
select * from t
inner join (select id from t where *** order by id limit m,n )t1 on t1.id = t.id
在这种情况下,改写后的sql语句还能达到优化的目的吗?
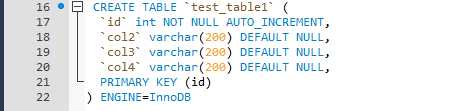
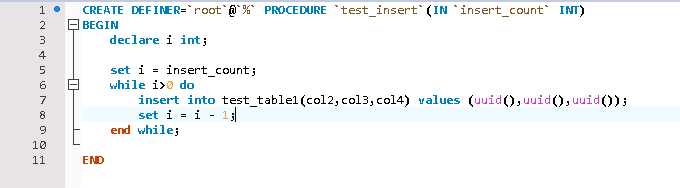
测试环境搭建
测试数据比较简单,通过存储过程循环写入测试数据,测试表的InnoDB引擎表。
这里要注意的是日志写入模式一定要修改成sync_binlog = 0,否则默认情况下,500w数据,估计一天都写不完,这个与日志写入模式有关,就不多说了,

分页查询优化的缘由
首先还是先看一下这个经典的问题,分页的时候,越“靠后”查询相应
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









