







 本文详细介绍使用Scrapy框架爬取百度新闻的过程,包括前期准备、网页分析、代码编写及结果展示,适合初学者掌握Scrapy的基本操作。
本文详细介绍使用Scrapy框架爬取百度新闻的过程,包括前期准备、网页分析、代码编写及结果展示,适合初学者掌握Scrapy的基本操作。
本次博客使用 Scrapy爬虫框架 爬取 百度新闻,并保存到 Mysql数据库 中。除了知道爬虫知识外,还需要了解一下数据库的知识。
…
如果你不太了解数据库的知识,请你不要慌,看我的Mysql系列博客就好啦…(虽然是转载,但也是我一个字一个字敲的,都是经过大脑和验证的)
一、前期准备
- 会简单使用Fidder进行抓包;
- 会一点Scrapy爬虫框架(网上教程很多,也可看我第二章内容);
- 会一点简单的数据库操作(建库、建表、增删查改)
二、初识Scrapy
工欲善其事必先利其器,Scrapy框架的安装,请看我这篇博客 (传送门), 里面详细且正确的告诉大家如何安装Scrapy框架。
安装好Scrapy框架后,我们该如何使用它呢?下面我会简单介绍几个Scrapy框架常用的命令。知道了这些命令,我们就能创建并运行爬虫项目了。
- startproject命令
- genspider命令
- crawl命令
注意:这些命令都是在cmd中操作,且是以管理员身份打开
1、startproject命令
语法:
scrapy startproject 爬虫项目名
我们可以通过这个命令创建一个Scrapy框架爬虫项目,如下:

说明:
- D:\pythonProgram\scrapytest1路径 是创建存放爬虫项目的文件夹的路径。这个文件夹在何处创建,读者随意;
- scrapy startprojct 是固定搭配,scrapy是Scrapy框架中每个命令必带的前缀;
- newsbaidu 是爬虫项目名
创建完之后,我们可以去此路径查看一下,如下:
2、genspider命令
语法:
scrapy genspider -t 爬虫文件模板 爬虫文件名 域名
我们可以通过这个命令创建一个爬虫文件,注意,是创建爬虫文件。前面那个startprojct命令是创建爬虫项目,一个项目里面可有多个爬虫文件。
在Scrapy框架中,其为我们提供了四个爬虫文件模板,我们可以在cmd中输入 scrapy genspider -l(这里是小写的l,不是数字1),如下:

一般的爬虫项目,我们使用basic模板创建爬虫文件即可,其它3个模板,如需求,请读者自行了解!
创建爬虫文件,如下:
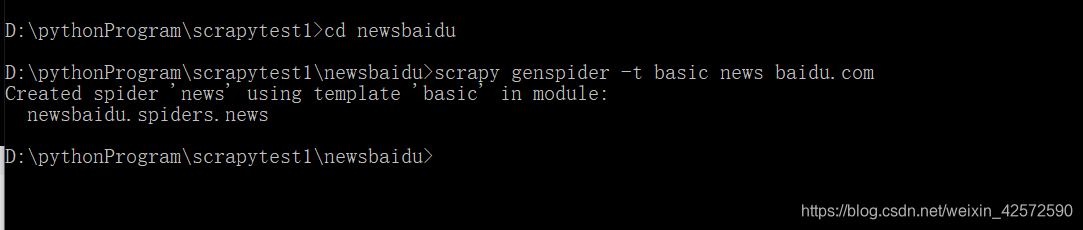
说明:
- cd newsbaidu:创建爬虫文件前,需先进入爬虫项目;
- scrapy genspider -t:是创建爬虫文件模板的固定搭配;
- basic:爬虫文件模板
- news:项目里的爬虫文件名
- baidu.com:要爬取网站的域名
3、crawl命令
语法:
# 显示爬取日志
scrapy crawl 爬虫文件名
或
# 不显示爬取日志
scrapy crawl 爬虫文件名 --nolog
这个命令的作用是运行爬虫文件,进行网页数据爬取。现在还未编写爬虫文件,需等到最后运行爬虫文件时,再演示。
4、简析项目文件结构
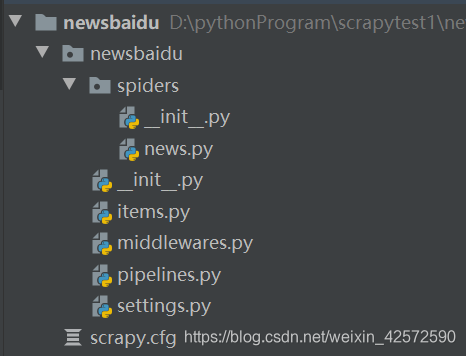
从上往下,逐一简单介绍:
- newsbaidu:项目名称
- spiders:爬虫主程序脚本文件夹
- news.py:爬虫脚本文件,数据爬取主要在此
- items.py:指定保存文件的数据结构,即数据的封装实体类
- middlewares.py:中间件,处理request和reponse等相关配置
- pipelines.py:项目管道文件,可对采集后数据的进行处理
- settings.py:设置文件,指定项目的一些配置
- scrapy.cfg:配置文件,指定路径
我们主要操作的文件,就是上面加粗的文件。
三、网页分析(重点&难点)
1、简单分析网页
打开浏览器进入百度新闻首页,如下:
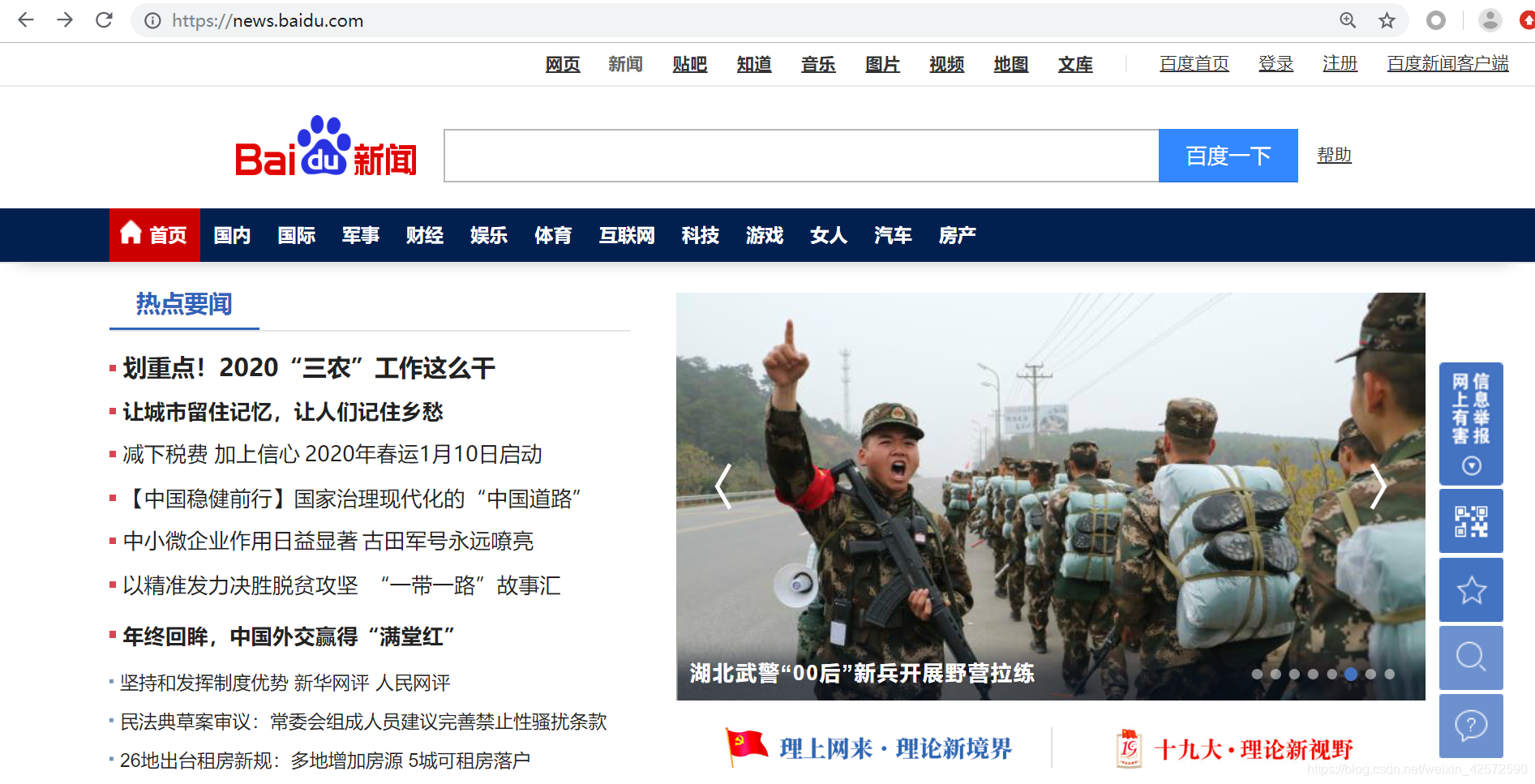
复制 “让城市留在记忆,让人们记住乡愁”,进入首页源代码查看是否存在这句话,如下:

发现有这句话。我们进行第一个猜测:可能全部的新闻标题和新闻url都在首页源代码中。为了验证这个猜测,我们再选择首页中的一句话 “伊朗宣布将于周五开始与中俄军演,为伊斯兰革命后首次”,进入首页源代码查看是否存在,如下:
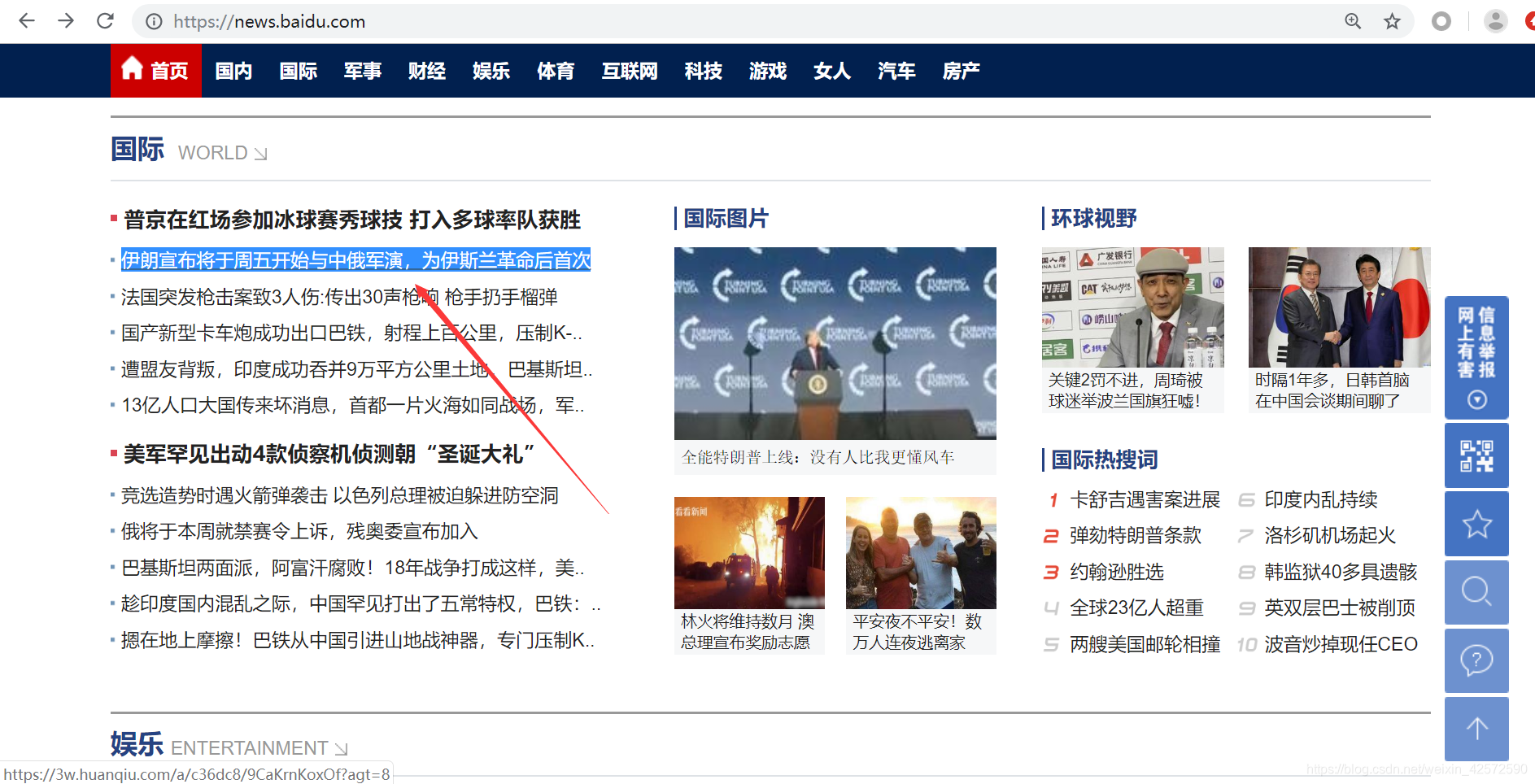
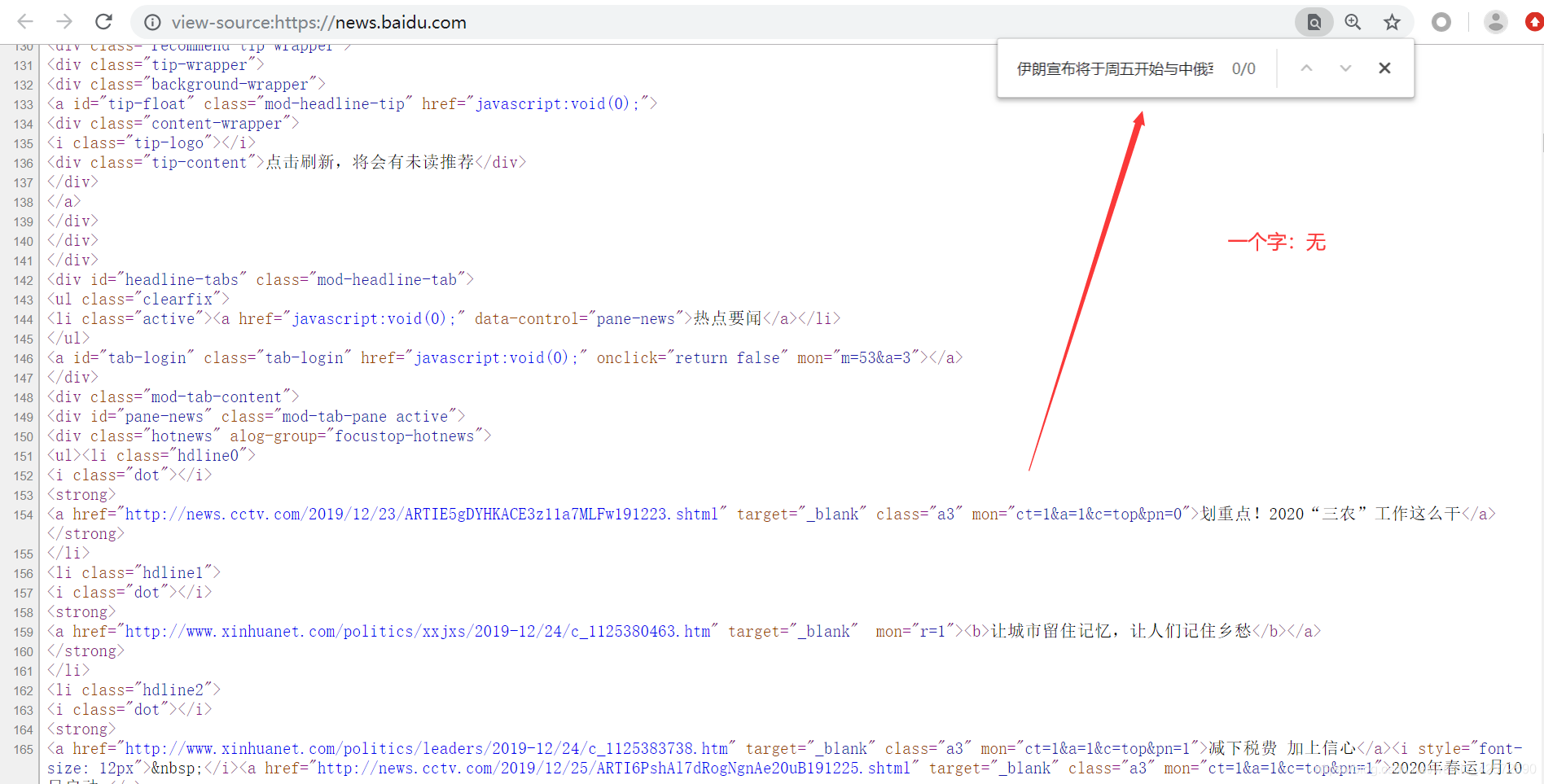
经过几次上面的操作,我们发现:除了热点要闻可以在首页源代码都查询,其他都不能 。这个时候,我们可能要想一下,百度新闻中其他新闻标题和url信息是不是 通过JS的Ajax异步请求生成的呢 ?下面我们就通过Fiddler抓包分析。
2、Fiddler抓包分析
前面 :我使用的是谷歌浏览器,所以要想用Fidder进行抓包分析,除了下载一个Fiddler软件,还需要给谷歌浏览器安装一个SwitchyOmega插件,怎么在谷歌下载和安装这个插件,请自行百度啦(不然跑题了…)。使用火狐浏览器的朋友呢,不用下载这个插件,可以在浏览器里面直接配置,也请自行百度啦。
(1)打开Fiddler软件
(一个小技巧:在刷新页面之前,Fiddler里面就开始不知道抓些什么包了,我们可以在底下输入:clear,清除掉这些记录哦!)
(2)在谷歌浏览器里面刷新百度新闻页面
刷新完页面后,我们进入Fiddler,它已经为我们抓了很多包了,接下来要靠我们自己了。这里也有小技巧呐:如果我们前面分析出,数据可能存放在JS文件中,我们肯定要特别关照一下下Fiddler抓的JS文件了。请看下图:
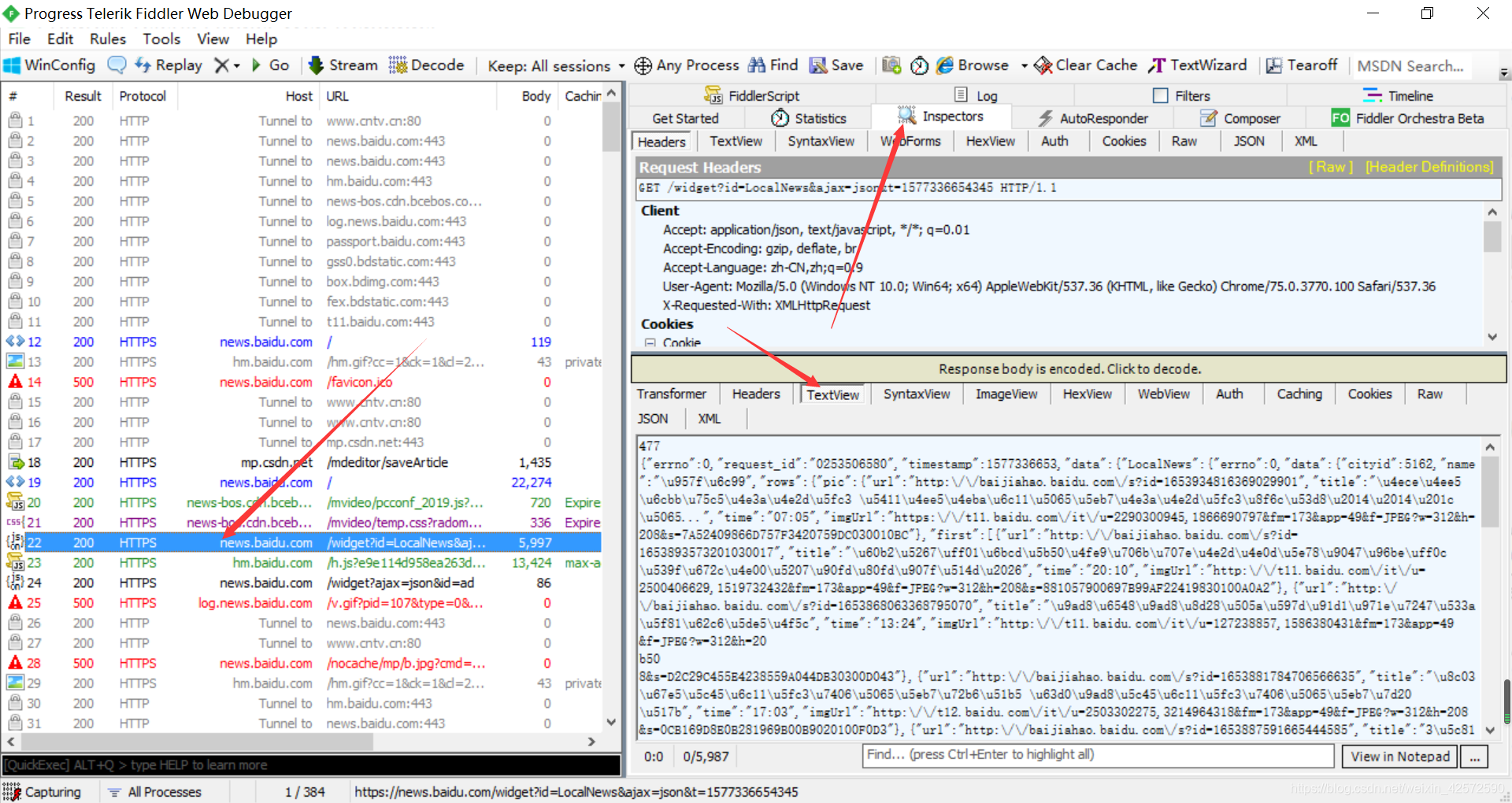
这显示的是什么鬼??是人看的吗?! 这当然不是人看的了,我们可以复制里面的Unicode编码,借助Python自带的编辑器IDLE,将其转码,我们人再看。如下:
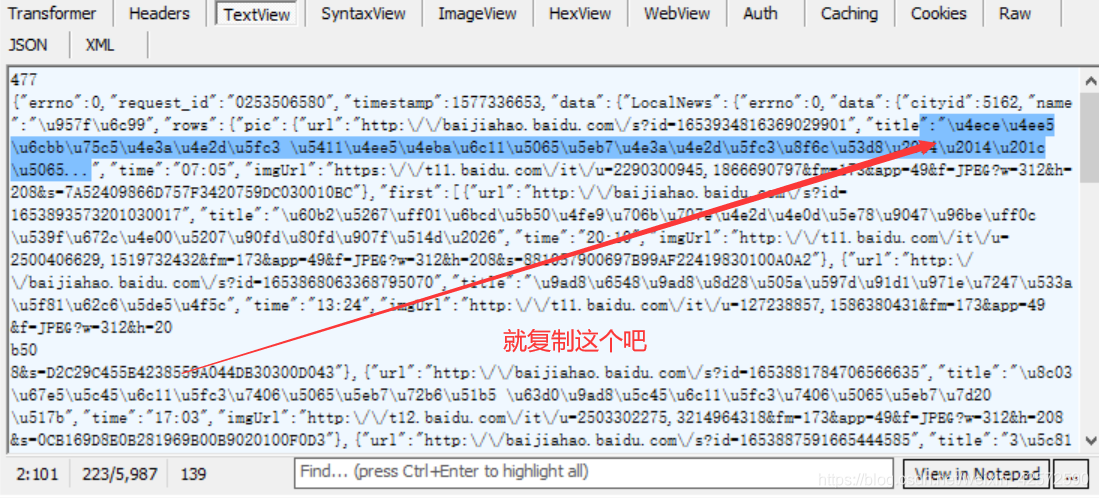
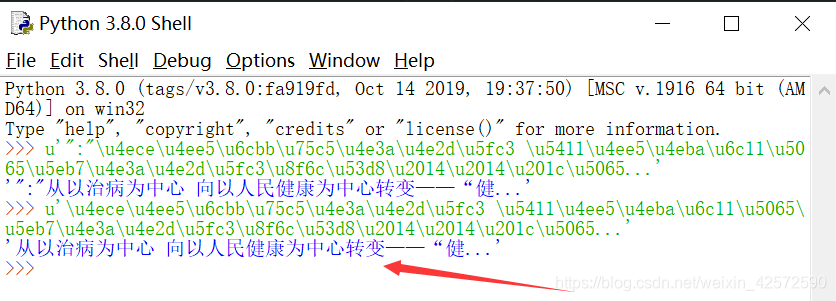
原来那串Unicode编码是这个意思,真有意思啊。我们复制这句话到百度新闻首页找找,如下:
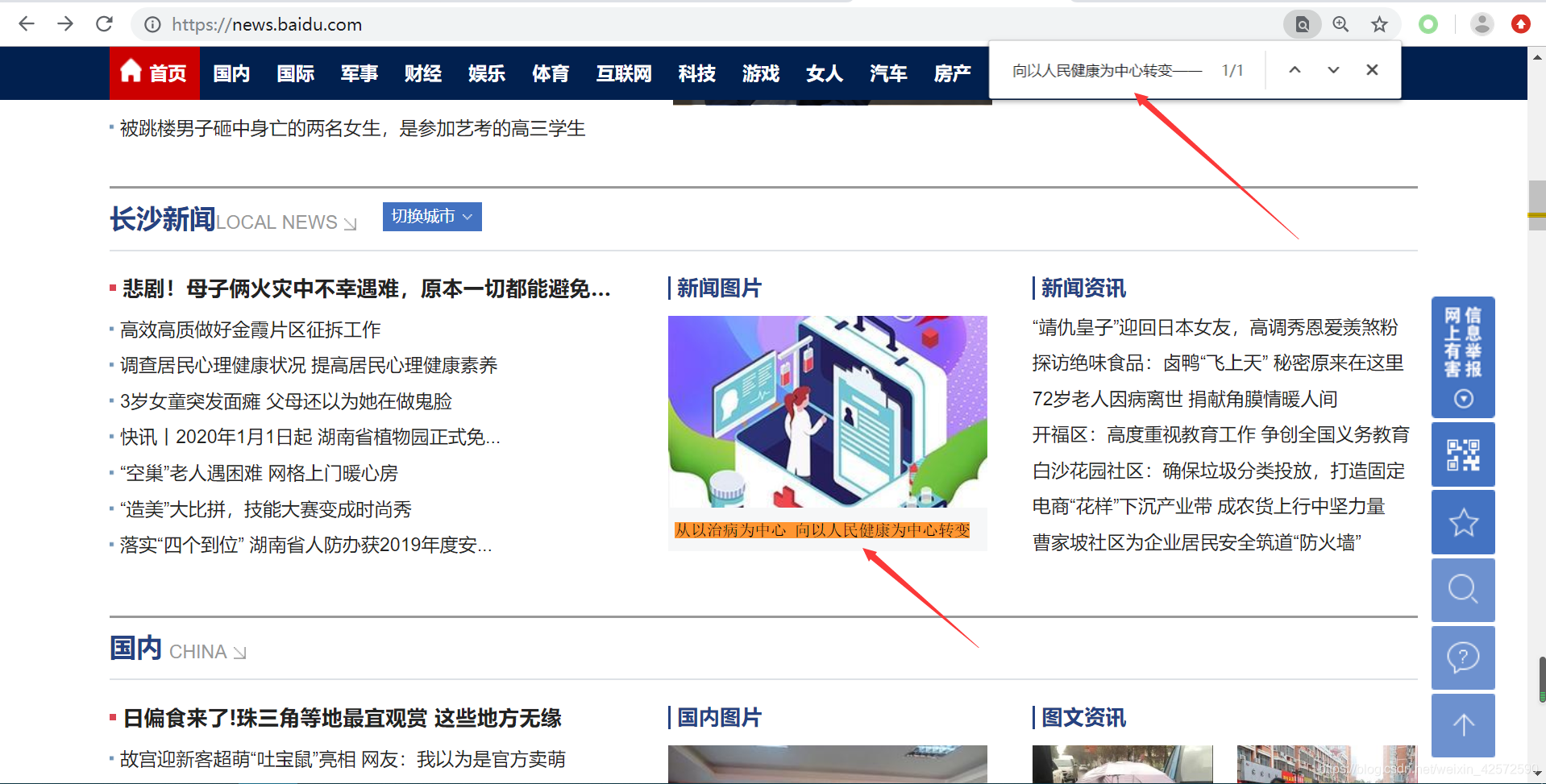
嘿!还真找到了。我们进行第二个猜测:数据都存放在这个JS文件里面。我们就再去Fiddler里面观察一下这个JS文件,发现好像不太对,这里面的数据一看明显就太少了,和百度新闻首页里面那么多新闻数据完全不是一个数量级别。难道?数据还存放在其他JS文件中?就再去Fiddler里面找其他JS文件…(读者,你先去找吧…任你找,找破天也不会找的,哈哈哈哈哈)
好像找不到了,其他JS文件夹里面没有数据啊…我再重新刷新一下百度新闻页面,说不定会出来。刷啊刷啊,找啊找啊,还是没的。
这个时候,我们好像束手无策。别急,我们百度一下,看以前有没有人分析过百度新闻,看他们怎么找到规律的。百度了一下,好像、貌似没有…(如果有,也请读者好好琢磨琢磨,他们是怎么找到规律的!)
我们就盯着有数据的JS文件看,进行天马行空的想象了。我们观察到JS的url好像有点古怪,如下:
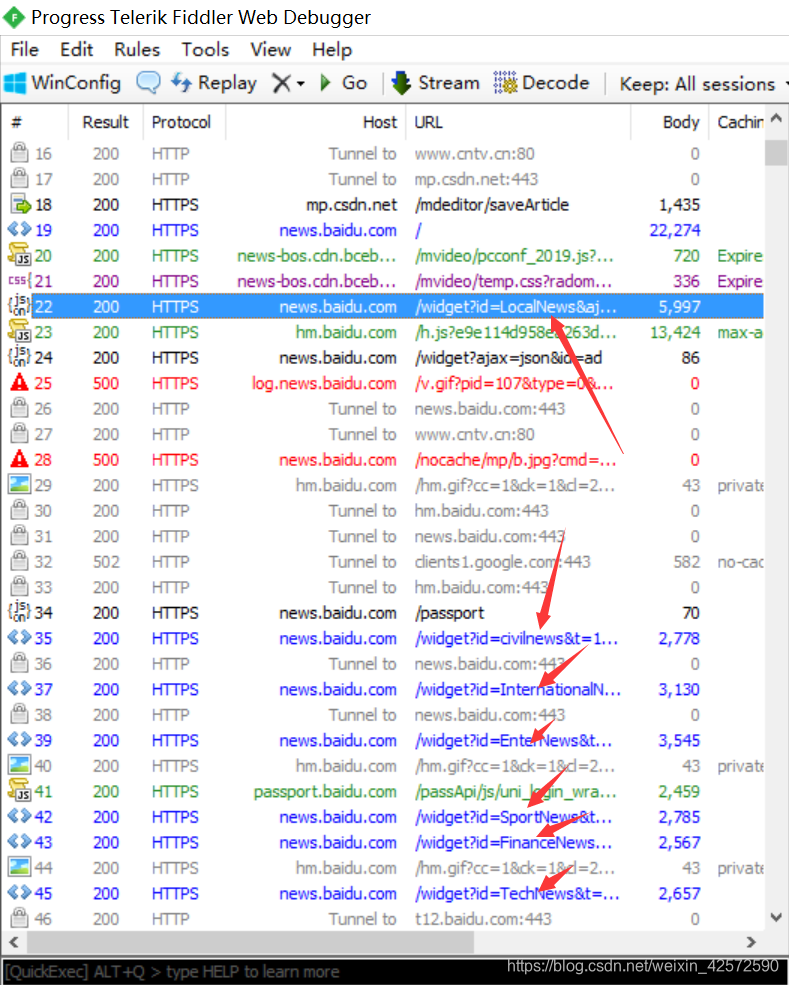
好像,有数据的JS文件的url和底下那几个比较显眼的绿色的get请求文件的url有那么一丢丢的类似。如果英文水平还行,应该可以看懂箭头指向的单词是什么意思。然后,再对比一下百度新闻首页中的新闻类别,我们好像发现了一点什么!!
复制这些文件的url(对着这个文件,右击 > Copy > Just Url),进行对比和测试,如下:
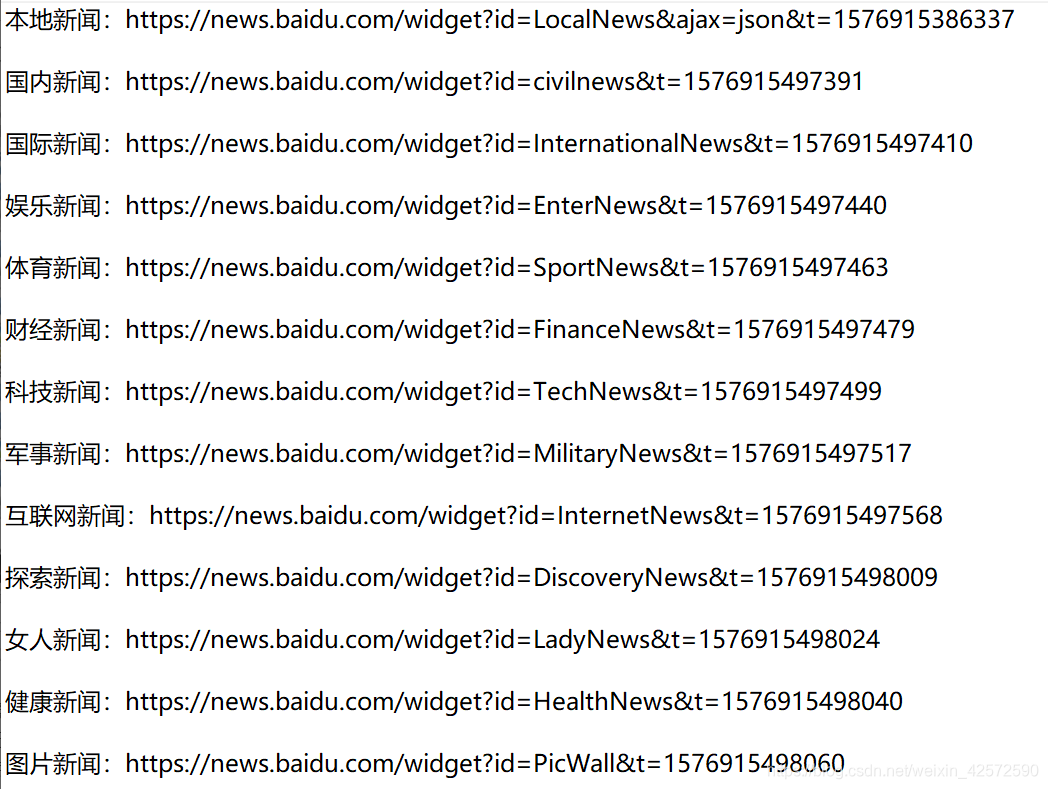
经过对比和测试这些url,我们可以发现:
- 每个url后面的 t=1579xxxxxxx,应该是时间戳,删除也不会对进入url有影响;
- 除了本地新闻的url还多一串:&ajax=json,我们进行测试,这个代表JSON格式,为其他url后面加上这个字符串,也都从html网页格式变成了JSON格式。
有了这些新闻的JSON数据格式,接下来就是分析正则表达式,提取我们想要的数据了。
- 对本地新闻,标题正则表达式:“title”:"(.*?)";url正则表达式:“url”:"(.*?)"
- 对其他新闻,标题正则表达式:“m_title”:"(.*?)";url正则表达式:“m_url”:"(.*?)"
分析,我们就到此结束。如有疑问,请多多练习!
四、代码编写
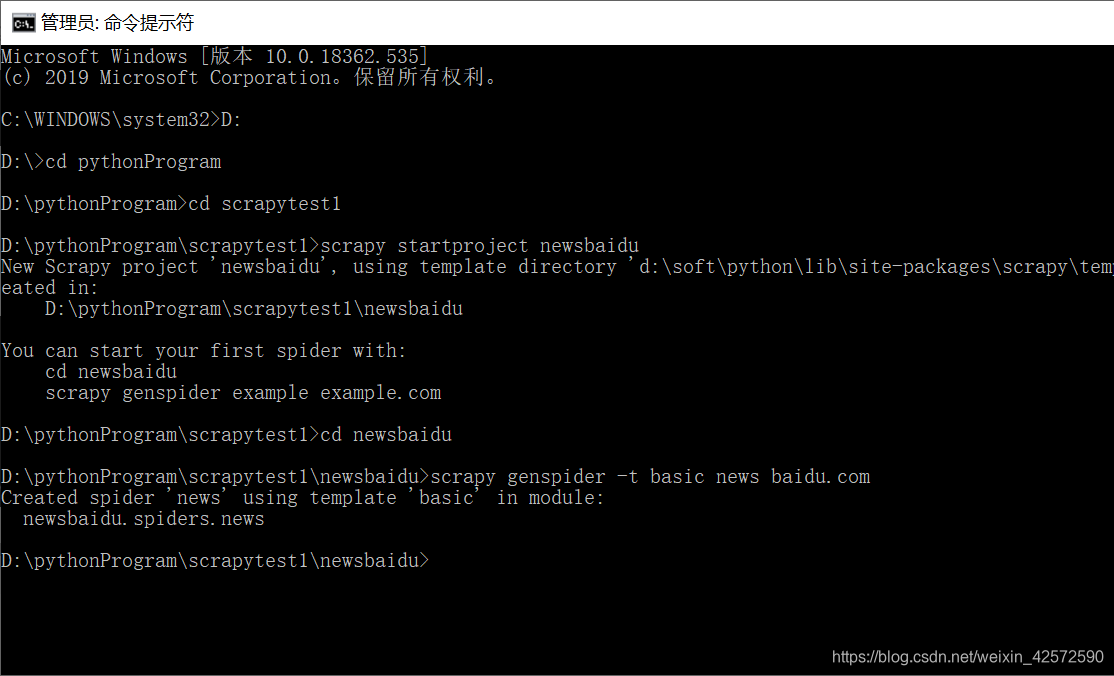
1、爬虫项目创建(先在cmd中)
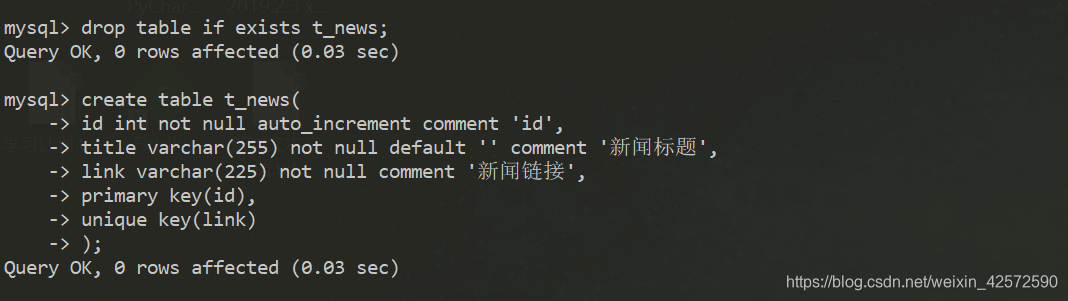
2、数据库表的创建
3、爬虫代码编写
(1)进入Pycharm,导入爬虫项目newsbaidu
File > Open >
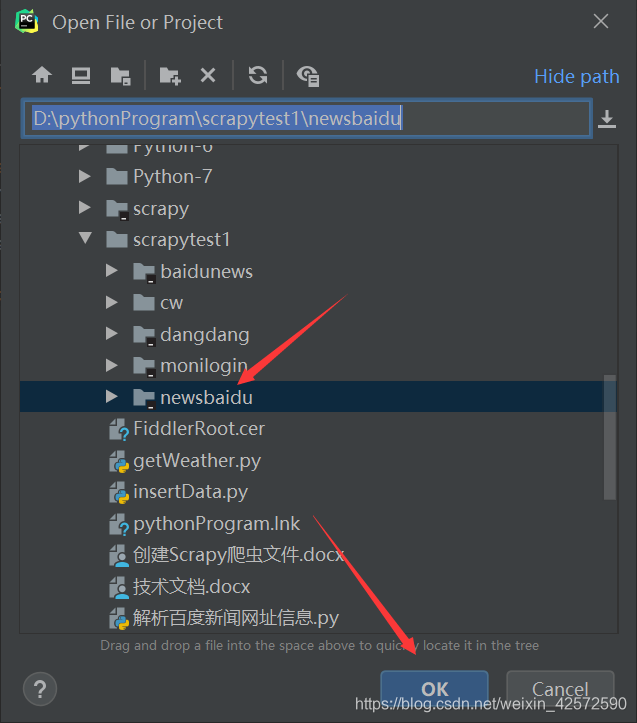
(2)设置配置文件settings.py


(3)item.py编写
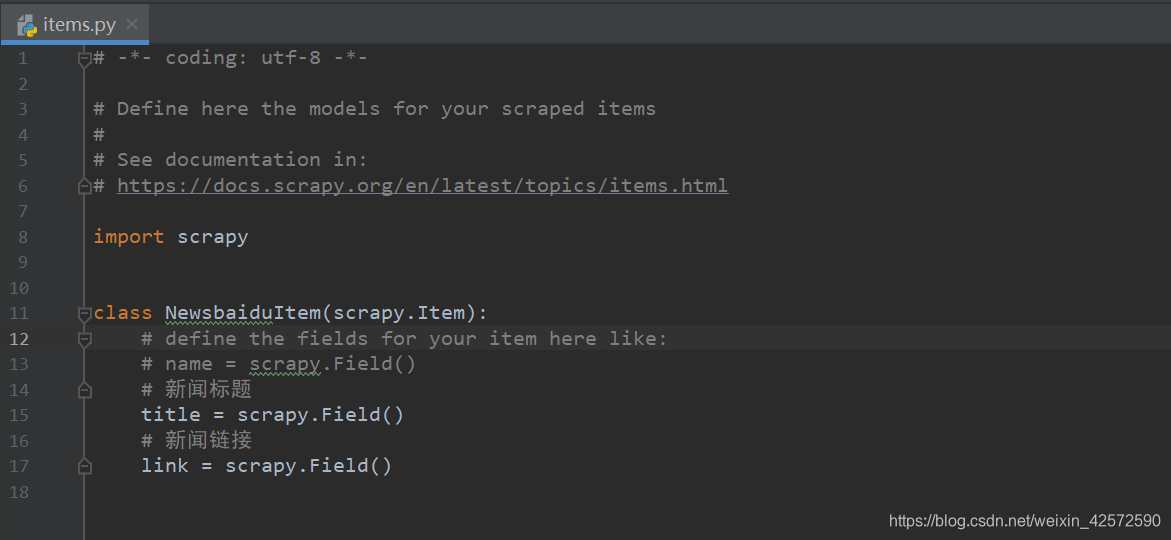
(4)编写news.py
# -*- coding: utf-8 -*-
import scrapy
import re
from scrapy.http import Request
from newsbaidu.items import NewsbaiduItem
class NewsSpider(scrapy.Spider):
name = 'news'
# 域名
allowed_domains = ['baidu.com']
# 爬取开始网址
start_urls = ['https://news.baidu.com/widget?id=LocalNews&ajax=json']
# 百度新闻类别
allid = ['LocalNews', 'civilnews', 'InternationalNews', 'EnterNews', 'SportNews', 'FinanceNews', 'TechNews',
'MilitaryNews', 'InternetNews', 'DiscoveryNews', 'LadyNews', 'HealthNews', 'PicWall']
# 构造百度新闻网址
allurl = []
for url in range(0, len(allid)):
thisid = allid[url]
thisurl = "https://news.baidu.com/widget?id=" + thisid + "&ajax=json"
allurl.append(thisurl)
def parse(self, response):
for i in range(0, len(self.allurl)):
print("第" + str(i) + "个栏目")
print("爬取网址:" + self.allurl[i])
yield Request(self.allurl[i], callback=self.next)
"""某个新闻模块数据爬取"""
def next(self, response):
print("进入next方法")
# 进入本地新闻
if (response.url == 'https://news.baidu.com/widget?id=LocalNews&ajax=json'):
data = response.body.decode("utf-8", "ignore")
alldata = self.get_data(data, self.pattern(1))
else: # 进入其他新闻
data = response.body.decode("utf-8", "ignore")
alldata = self.get_data(data, self.pattern(2))
# 创建BaidunewsItem对象
item = NewsbaiduItem()
item["title"] = alldata[0]
item["link"] = alldata[1]
yield item
# 用于正则表达式的匹配
def pattern(self, choice):
# 存放正则表达式
pattern = []
if (choice == 1):
# 编写正则表达式
pat1 = '"title":"(.*?)"'
pat2 = '"url":"(.*?)"'
pattern.append(pat1)
pattern.append(pat2)
elif (choice == 2):
# 编写正则表达式
pat1 = '"m_title":"(.*?)"'
pat2 = '"m_url":"(.*?)"'
pattern.append(pat1)
pattern.append(pat2)
return pattern
'''处理本地新闻数据,获取新闻标题和url'''
def get_data(self, data, pattern):
print("调用了get_data1方法")
# 编写正则表达式
pat1 = pattern[0]
pat2 = pattern[1]
# 爬取网页数据里面的新闻标题
titledata = re.compile(pat1, re.S).findall(data)
# 爬取网页数据里面的url数据
urldata = re.compile(pat2, re.S).findall(data)
# 存放新闻标题
titilall = []
# 存放新闻url
urlall = []
for i in range(0, len(titledata)):
# 转码,显示成中文——这步只是为了调试方便
thistitle = re.sub(r'(\\u[\s\S]{4})', lambda x: x.group(1).encode("utf-8").decode("unicode-escape"),
titledata[i])
titilall.append(thistitle)
# 处理url,用/替换\/
for j in range(0, len(urldata)):
thisurl = re.sub("\\\/", "/", urldata[j])
urlall.append(thisurl)
# 存放新闻标题和url
alldata = []
alldata.append(titilall)
alldata.append(urlall)
return self.deal_data(alldata)
# 处理新闻标题和新闻url,使其一一对应
def deal_data(self, alldata):
print("进入deal_data方法")
# 判断新闻标题和url是否一一对应
if (len(alldata[0]) == len(alldata[1])):
return alldata
else: # 根据源码分析,我们可以得知:都是新闻标题比url多,我们只要从前删除标题直到标题数量与url数量相等时即可
# 首先求出新闻标题比新闻url多几个
count_url = len(alldata[0]) - len(alldata[1])
for i in range(0, count_url):
alldata[0].pop(0)
return alldata
5、编写pipelines.py
把数据出入数据库中。
# -*- coding: utf-8 -*-
import pymysql
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class NewsbaiduPipeline(object):
def process_item(self, item, spider):
# 连接数据库
conn = pymysql.connect(
host="localhost",
user="root",
passwd="ydjws",
db="test",
port=3306,
charset="utf8",
)
# 游标
cur = conn.cursor()
for i in range(0, len(item["title"])):
title = item["title"][i]
link = item["link"][i]
# 编写sql语句
sql = "insert into t_news(title,link) values ('" + title + "','" + link + "')"
try:
cur.execute(sql)
conn.commit()
except Exception as err:
print(err)
conn.rollback()
conn.close()
return item
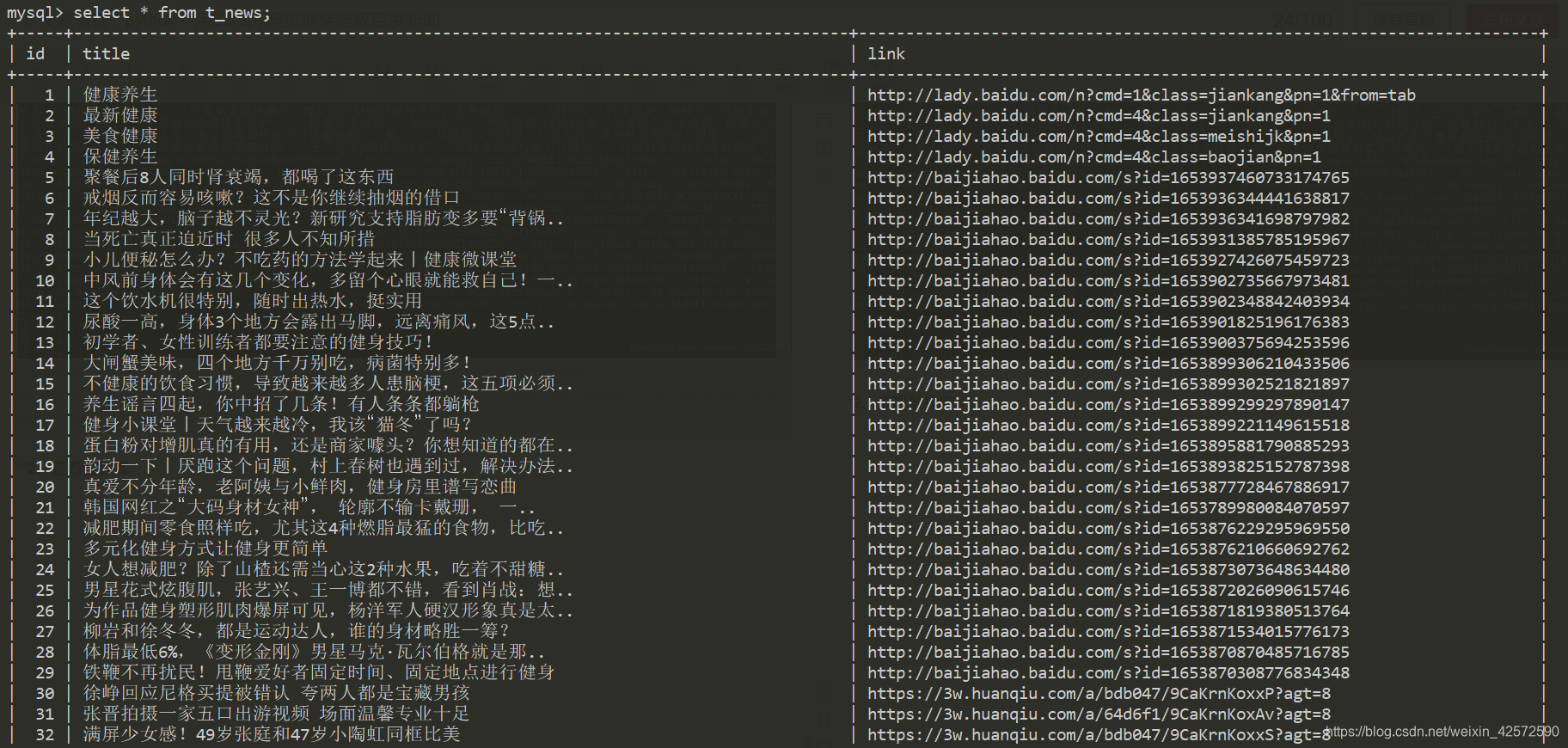
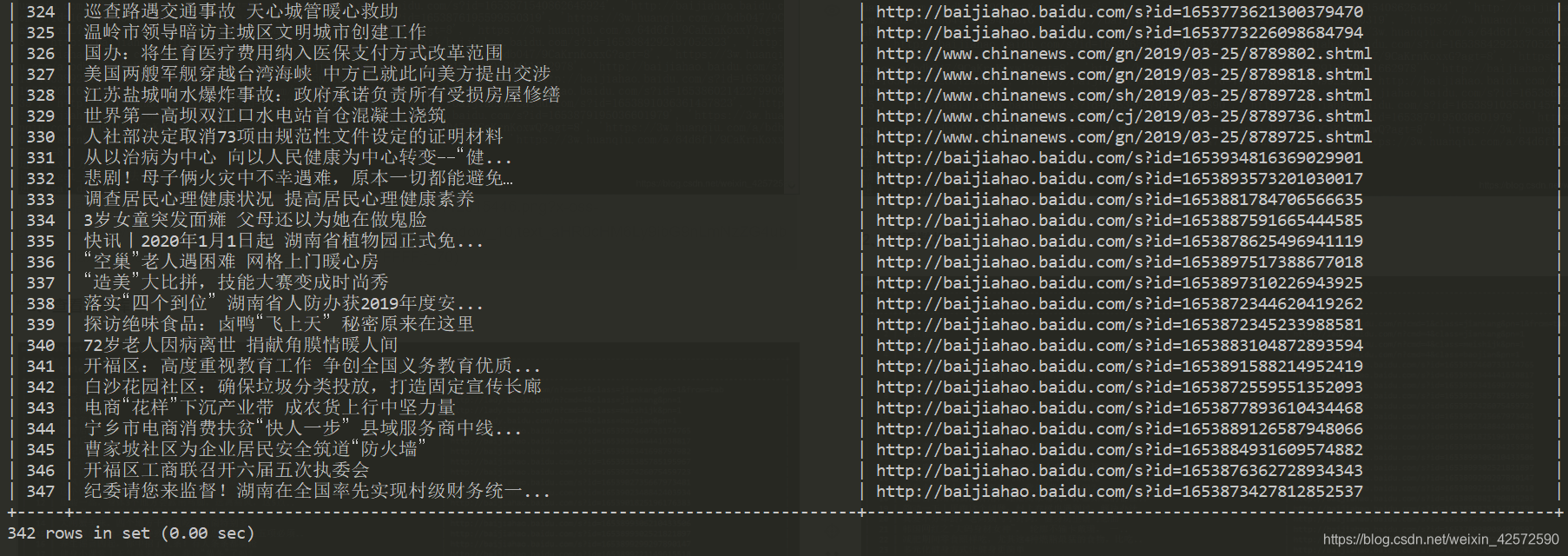
五、结果展示
1、执行scrapy crawl news --nolog
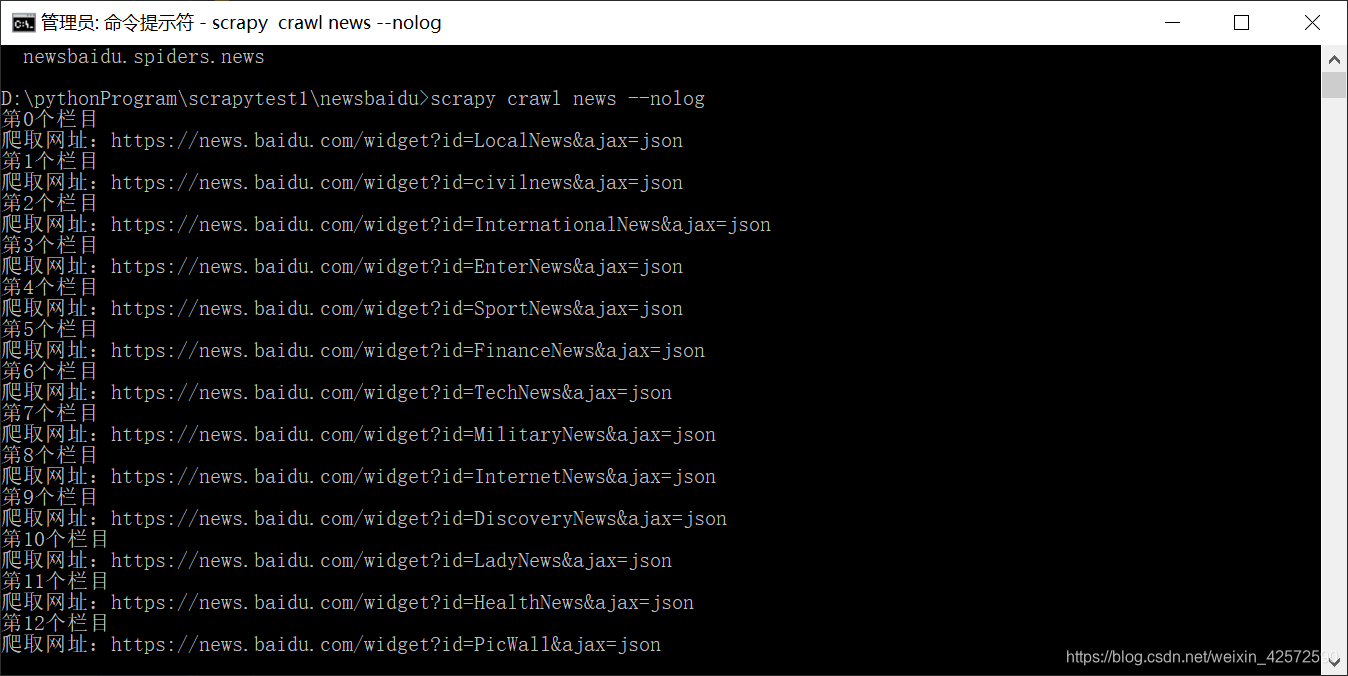
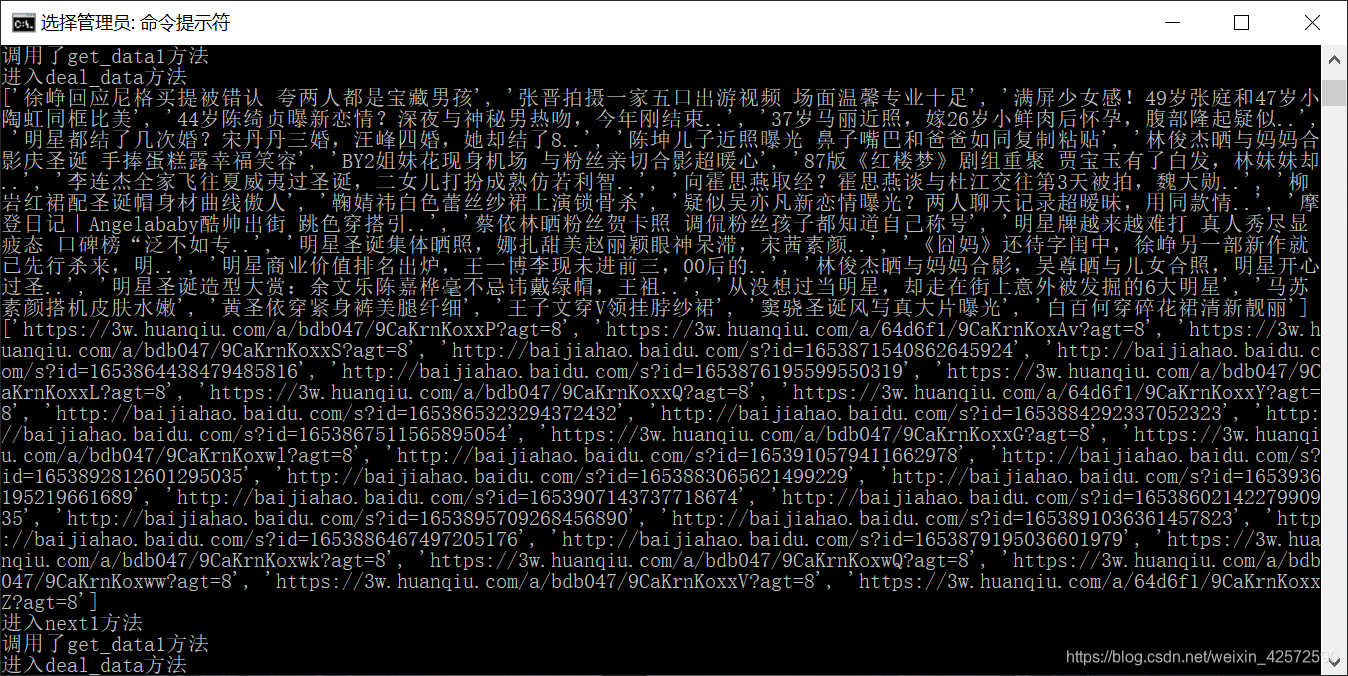
2、查看数据库

















 4683
4683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









