







背景:集群宕机以后,重启报错,DATADG1磁盘组无法启动
1.手动挂起DATADG1磁盘组 报错
alter diskgroup datadg1 mount
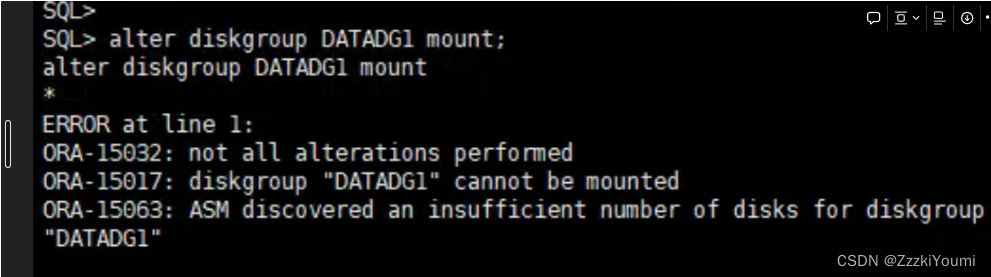
后台ASM报错
根据报错 found 0 disks 怀疑 是磁盘组里的磁盘有问题,没有启动
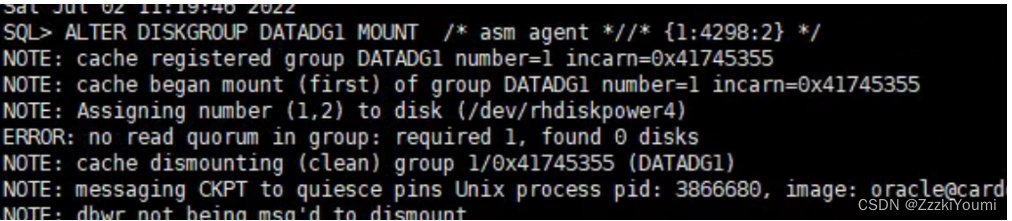
2.查询磁盘状态
select name,path,STATE,MODE_STATUS from v$asm_disk;
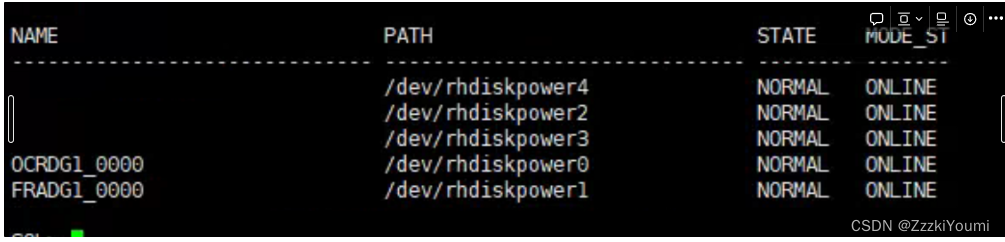
发现磁盘都在,但是磁盘组没法跟磁盘对应起来
3.硬件工程师检查硬盘、以及存储网关都正常,磁盘权限也正常
4.怀疑是磁盘头损坏了,导致磁盘组跟磁盘无法对应
select group_Number,disk_number,mount_status ,header_status from v$asm_disk;
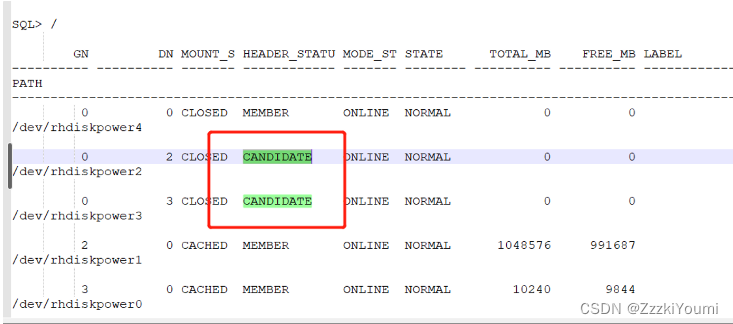
发现2,3磁盘头状态为CANDIDATE
5.使用kfed查看磁盘头
kfed read /dev/rhdiskpower2
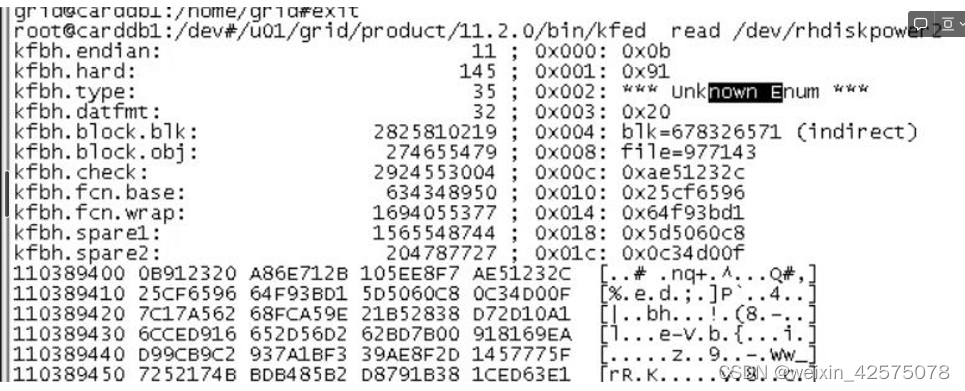
kfbh.type显示异常 正常情况下应该是KFBTYP_DISKHEAD
6.修复2,3磁盘头
从版本10.2.0.5开始ASM 会对disk header做一个额外的备份。即第二AU 的倒数第二个block中备份了一份KFBTYP_DISKHEAD。这个ASM Disk header的作用是当真的KFBTYP_DISKHEAD被意外覆盖或损坏时可以使用Oracle 工具 KFED使用repair选项来修复Disk header
kfed repair //dev/rhdiskpower2
此时检查 磁盘头状态正常,显示为KFBTYP_DISKHEAD
7.一节点的数据库反复重启
修复磁盘头以后,磁盘能够正常挂起,并且数据库能够拉起
但是数据库在运行一段时间后 ,出现宕机
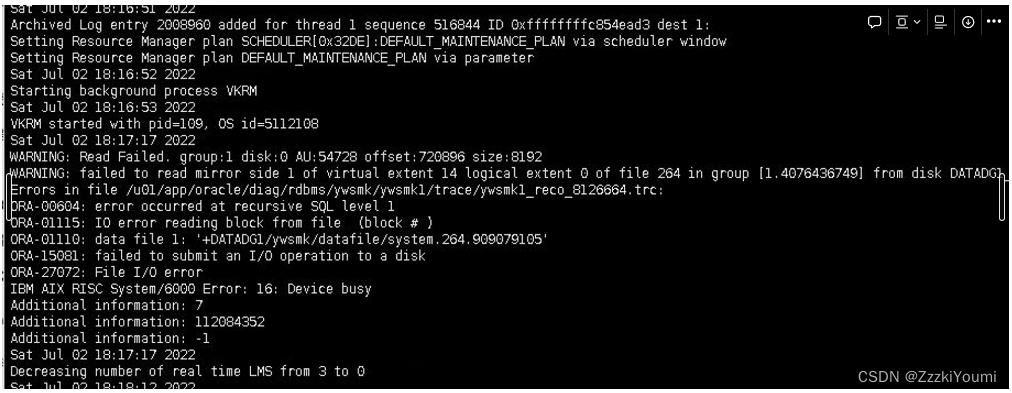
数据库日志显示 IO错误
由于操作系统为AIX,排查两个节点的磁盘参数
lsattr -El hdisk20 | grep reserve
发现二节点并没有设置no_reserve
这个参数的作用:这个参数其实是表示操作系统是否持有存储卷的共享锁方式
设置
chdev -l hdisk21 -a reserve_policy=no_reserve
设置完成后,一节点能够正常运行
8.二节点gpnpd服务无法启动
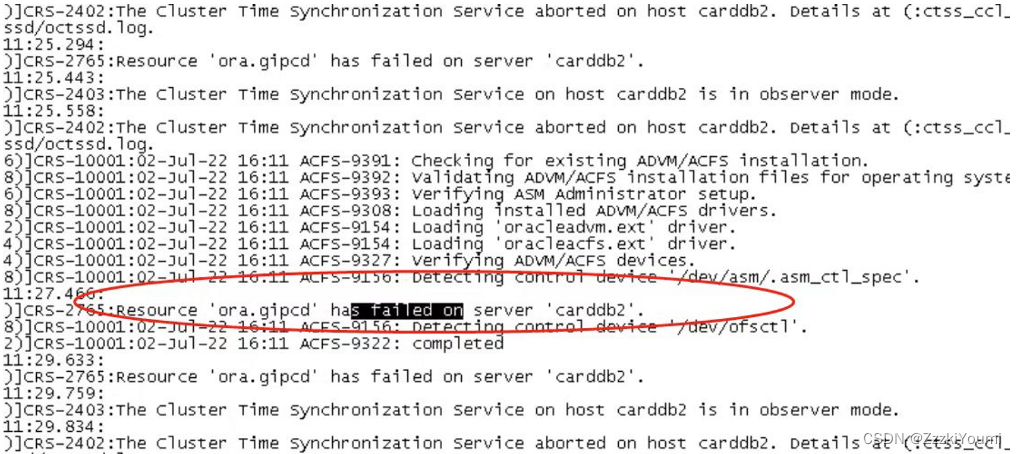
根据gipcd 日志信息
匹配到官方文档Doc ID 2034669.1
删除以上三个目录的缓存,重启rac,二节点启动成功














 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









