







大家好,我是剑南,今天我为大家带来的内容是python异步IO的协程知识的分享。
为何引出协程
协程是python中比较难理解的知识。在python中执行多任务可以采用多进程或者是多线程来执行,但是两者都存在一些缺点,因此,我们提出了协程。
多线程优缺点分析
优缺点分析
优点:在一个进程内线程共享全局变量,多线程方便共享数据。
缺点:线程可以对全局变量随意的修改,这会造成线程之间对全局变量的混乱(即线程非安全)
引入案例
import threading
import time
def test1(num_list):
num_list.append(10000)
print('test1--->num:%s' % num_list)
def test2(num_list):
print('test2--->num:%s' % num_list)
if __name__ == "__main__":
num_list = [11, 22, 33, 44]
t1 = threading.Thread(target=test1, args=(num_list, ))
t1.start()
time.sleep(1)
t2 = threading.Thread(target=test2, args=(num_list, ))
t2.start()
运行结果,如下所示:
test1--->num:[11, 22, 33, 44, 10000]
test2--->num:[11, 22, 33, 44, 10000]
多进程优缺点分析
优缺点分析
优点:稳定性强。
缺点:创建进程的代价非常大,因为操作系统要给每个进程分配固定的资源,并且操作系统对进程的总数会有一定的限制,若线程过多,操作系统的调度都会出现问题,会造成假死状态。
同步与异步的理解
同步:当发出一个“调用”时,在没有得到结果之前,该“调用”就不用返回,“调用者”需要一直等待,直到”调用“结束,才能进行下一步工作。
异步:”调用“发出之后,就直接返回了,即使是没有返回结果也没有问题,当”被调用者“完成任务后,通过状态通知”调用者“继续回来处理该调用。
接下来我们就来了解一下普通同步代码实现的多IO任务的案例。具体代码,如下所示:
import time
def testIO_1():
print('开始运行IO任务1....')
time.sleep(2) # 假设该任务运行2秒
print('IO任务已经完成,耗时2秒')
def testIO_2():
print('开始运行IO任务2....')
time.sleep(3) # 假设该任务运行3秒
print('IO任务已经完成,耗时3秒')
start = time.time()
testIO_1()
testIO_2()
print('所有IO任务,总耗时%.5f秒' % float(time.time() - start))
运行结果,如下所示:
开始运行IO任务1....
IO任务已经完成,耗时2秒
开始运行IO任务2....
IO任务已经完成,耗时3秒
所有IO任务,总耗时5.04647秒
在上面的代码中,我们实现了顺序两个同步IO任务testIO_1()与testIO_2(),最后总耗时为5秒。我们都知道,在计算机中CPU的运算速率要远远大于IO速率,而当CPU运算完毕之后,如果再要闲置很长时间去等待IO任务完成才能进行下一个任务的计算,这样执行任务的效率很低。
因此,我们可以想到,能否在上述IO任务执行前中断当前IO任务(对应time.sleep(2)),进入下一个任务,当IO任务完成之后再唤醒该任务。
因此,协程便诞生了。
async与await实现协程
async与await这两个关键字是出现在python3.4之后的,代替了python2版本中的yield from。
async:声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等待挂起条件(time.sleep(3))消失后,再回来执行。
await:声明程序挂起,比如异步程序执行到某一步时需要很长时间的等待,就将此挂起,去执行其他异步函数。
对于await,我举个例子:假设有两个异步函数async a与async b,其中a代码中某一步有await,当程序碰到关键字await之后,便会挂起a,去执行b,当挂起条件结束,不论b是否执行完毕,都必须马上从b跳出来,去执行a。
更改上面的代码,如下所示:
import time
import asyncio
async def testIO_1():
print('开始执行IO任务1...')
await asyncio.sleep(2) # 假设任务耗时2秒
print('IO任务1完成,耗时2秒')
return testIO_1.__name__
async def testIO_2():
print('开始执行IO任务2...')
await asyncio.sleep(3) # 假设任务耗时3秒
print('IO任务2完成,耗时3秒')
return testIO_2.__name__
async def main(): # 调用方
tasks = [testIO_1(), testIO_2()] # 把任务添加到tasks
done, pending = await asyncio.wait(tasks) # 子生成器
# print(done)
# print(pending)
for r in done: # done和pending都是一个任务,所以返回结果需要逐个调用result()
print('协程无序返回值:', r.result())
if __name__ == "__main__":
start = time.time()
loop = asyncio.get_event_loop() # 创建事件循环对象
try:
loop.run_until_complete(main()) # 完成事件循环,直到最后一个任务结束
finally:
loop.close() # 结束事件循环
print('所有IO任务,总耗时%.5f' % float(time.time() - start))
运行结果,如下所示:
开始执行IO任务2...
开始执行IO任务1...
IO任务1完成,耗时2秒
IO任务2完成,耗时3秒
协程无序返回值: testIO_1
协程无序返回值: testIO_2
所有IO任务,总耗时2.99948
多种方式实现协程
一、通过asyncio.wait()
你可以将一个操作分成多部分并分开执行,wait(tasks)可以被用于中断任务集合(tasks)中的某个被事件循环轮询到的任务,直到协程在后台操作完成之后才被唤醒。
对于上面的代码,我们采用的就是这种方式。
done, pending = await asyncio.wait(tasks)
此处传入并发运行的协程对象,通过await返回一个包含done与pending的元组,done表示已完成的任务列表,pending表示未完成的任务列表。
二、asyncio.gather()
如果你只关心协程并发运行后的结果集合,可以考虑采用gather(),它不仅通过await返回仅一个结果集,而且这个结果集的结果顺序是传入任务的原始顺序。
具体代码,如下所示:
import time
import asyncio
async def testIO_1():
print('开始执行IO任务1...')
await asyncio.sleep(2) # 假设任务耗时2秒
print('IO任务1完成,耗时2秒')
return testIO_1.__name__
async def testIO_2():
print('开始执行IO任务2...')
await asyncio.sleep(3) # 假设任务耗时3秒
print('IO任务2完成,耗时3秒')
return testIO_2.__name__
async def main():
results = await asyncio.gather(testIO_1(), testIO_2())
print(results)
if __name__ == "__main__":
start = time.time()
loop = asyncio.get_event_loop() # 创建事件循环对象
try:
loop.run_until_complete(main()) # 完成事件循环,直到最后一个任务结束
finally:
loop.close() # 结束事件循环
print('所有IO任务,总耗时%.5f' % float(time.time() - start))
运行结果,如下所示:
开始执行IO任务1...
开始执行IO任务2...
IO任务1完成,耗时2秒
IO任务2完成,耗时3秒
['testIO_1', 'testIO_2']
所有IO任务,总耗时3.00510
从运行结果,你会发现它是有序的,而采用wait()的方式是无序的。
三、asyncio.as_completed
as_completed(tasks)是一个生成器,它管理着一个协程列表的运行,当任务集合中的某个任务率先执行完毕时,会通过await关键字返回该任务的结果。可见其返回结果的顺序与wait()相同,均是按照完成任务顺序排列的。
具体代码,如下所示:
import time
import asyncio
async def testIO_1():
print('开始执行IO任务1...')
await asyncio.sleep(2) # 假设任务耗时2秒
print('IO任务1完成,耗时2秒')
return testIO_1.__name__
async def testIO_2():
print('开始执行IO任务2...')
await asyncio.sleep(3) # 假设任务耗时3秒
print('IO任务2完成,耗时3秒')
return testIO_2.__name__
async def main():
tasks = [testIO_1(), testIO_2()]
for completed_task in asyncio.as_completed(tasks):
results = await completed_task
print('协程无序返回值', results)
if __name__ == "__main__":
start = time.time()
loop = asyncio.get_event_loop() # 创建事件循环对象
try:
loop.run_until_complete(main()) # 完成事件循环,直到最后一个任务结束
finally:
loop.close() # 结束事件循环
print('所有IO任务,总耗时%.5f' % float(time.time() - start))
运行结果,如下所示:
开始执行IO任务2...
开始执行IO任务1...
IO任务1完成,耗时2秒
协程无序返回值 testIO_1
IO任务2完成,耗时3秒
协程无序返回值 testIO_2
所有IO任务,总耗时3.01378
小结
1、同步编程的并发性不高
2、多进程编程效率需要受CPU核数限制,当任务数量远大于CPU核数时,执行效率会降低。
3、多线程需要线程之间的通信,而且需要锁机制来防止共享变量被不同线程乱改,而且由于python中的全局解释锁,所以也无法做到真正的并行。
从上面的程序可以看出,使用as_completed(tasks)和wait(tasks)相同之处是返回结果的顺序是协程的完成顺序,与gather()相反。不同之处就是as_completed(tasks)可以实时返回当前完成的结果,而wait(tasks)需要等待所有协程结束后返回的done去获取结果。
实战 ——妹子图
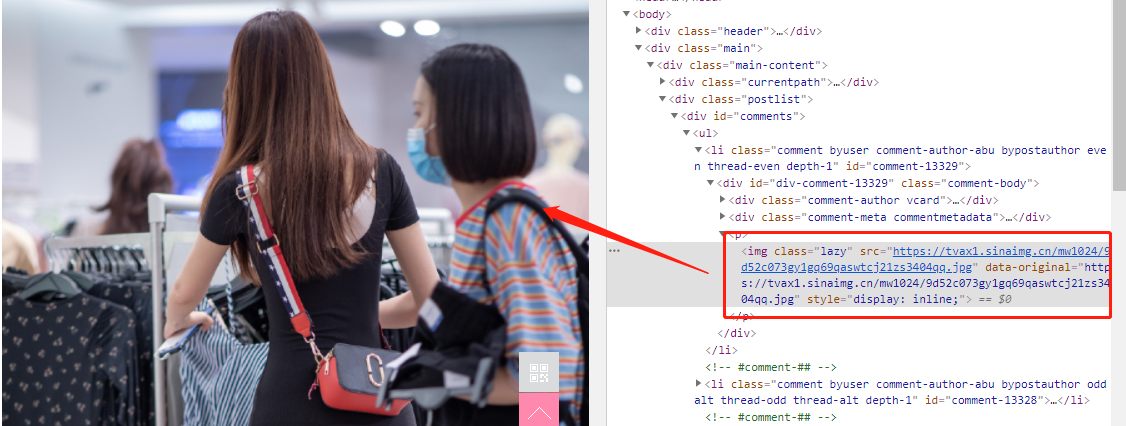
基础部分,我就不再过多的叙述。
最主要的任务就是获取到每一张图片的URL。
主要的库:
- httpx
- asyncio
- lxml
因为图片一共有144页,每页的url地址不同,首先获取每一页的url地址。
def get_page_url():
page_urls = []
for i in range(1, 5):
url = f'https://www.xxx.com/jiepai/comment-page-{i}/'
page_urls.append(url)
return page_urls
接下来就通过请求每一页的url地址,并对网页进行解析获取图片的url地址。
def get_img_urls():
img_urls = []
page_urls = get_page_url()
for page_url in page_urls:
response = httpx.get(page_url, headers=headers)
html = etree.HTML(response.text)
lis = html.xpath('//div[@id="comments"]/ul/li')
print(lis)
for li in lis:
data_originals = li.xpath('./div//img/@data-original')
# print(data_originals)
# img_urls.extend(data_originals)
for data_original in data_originals:
# print(data_original)
img_urls.append(data_original)
return img_urls
获取到url之后,只需要创建协程函数即可。
async def save_img(index, img_url):
print(f'*****正在下载第{index}张*****')
content = httpx.get(img_url, headers=headers).content
with open(f'./街拍美女/{index}.jpg', 'wb') as f:
f.write(content)
def main():
loop = asyncio.get_event_loop()
img_urls = get_img_urls()
print(len(img_urls))
tasks = [save_img(img[0], img[1]) for img in enumerate(img_urls)]
try:
loop.run_until_complete(asyncio.wait(tasks))
finally:
loop.close()
效果展示
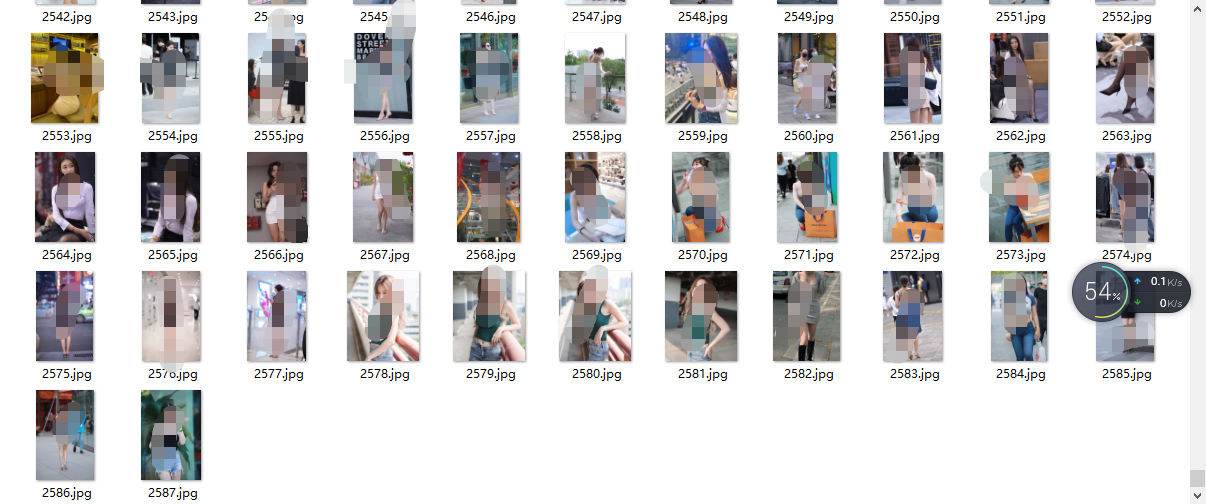
至此,成功获取到了两千多张图片。
本站地址不提供,防止进入小黑屋(需要可以私聊我)
告诉大家一个消息,本站导航栏中有几个栏目,我都已经写好代码,直接套用即可,需要可以私聊。















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









