







好久没写博客了,本人也是听了一个大佬的讲解才会的Tire树,但允许我说实话,我听的真的是懵逼……

于是我自己弄懂后整理并讲解一下下面初学者常有的问题:
1.什么是Trie树?
2.Trie树的理论构建思维。
3.Trie树的C代码构建方法。
4.Trie树的字符串查找方法。
----------------------------------------------------------------------------完美分割线----------------------------------------------------------------------------------------
1.什么是Trie树?
Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
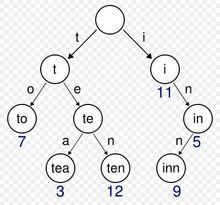
!!!事先说明,Trie树并不是二叉树模型,也就是说,每个节点的子节点可能有一个,两个或多个(如果字符限定为字母的话,最大子节点个数为26(小写字母数)+26(大写字母数)=52个)
也就是说,有一个根节点(最上面的那个)开始为空字符串,目前有两种走向(向右走或向左走),倘若向左走,这个空字符串就要添加一个字符 't' ,于是到第二阶段时,字符串目前的状态为 "t" ,接下来又有两种走向,倘若向左走,这个字符串就要添加下一个字符 'o' ,于是到了第三阶段时,字符串目前的状态为,"to",以此类推……
----------------------------------------------------------------------------完美分割线----------------------------------------------------------------------------------------
2.Trie树的理论构建思维
假设现在我要存储 5个字符串,他们分别是:
abcd
aer
abd
ab
bbc
我们先从第一个字符串开始来构建Trie树——————————————————————————————————————
 如右图所示我们按顺序从字符串的第一个字符依次往下建立,建立了一个关于字符串abcd的单向Trie树。
如右图所示我们按顺序从字符串的第一个字符依次往下建立,建立了一个关于字符串abcd的单向Trie树。
之后我们再从原基础上建立第二个字符串枝节————————————————————————————————————
 如右图所示,因为第一个字符串和第二个字符串的第一个字符都为 'a',所以就在第一个字符串的'a'的原基础上开始建立,由于第二个字符串的第二个字符不等于第一个字符串的第二个字符,所以产生分支。
如右图所示,因为第一个字符串和第二个字符串的第一个字符都为 'a',所以就在第一个字符串的'a'的原基础上开始建立,由于第二个字符串的第二个字符不等于第一个字符串的第二个字符,所以产生分支。
!!在这之后,即使第第二个字符串的第三个字符与第一个字符串的第三个字符相等,也不能共用!!
形象的说,没背叛前一直是兄弟,一但背叛后,不论后期有没有背叛,都不会再是兄弟了…………
之后我们再在原基础上建立第三个字符串的节点———————————————————————————————————
 可以看出,第一字符串和第三字符串共用了 'a', 'b'这两个字符,而第三个字符不相同,所以在'b'处产生分支。
可以看出,第一字符串和第三字符串共用了 'a', 'b'这两个字符,而第三个字符不相同,所以在'b'处产生分支。
之后我们再在原基础上添加第四个字符串的节点———————————————————————————————————
 我们发现第四字符串并没有在原基础上再添加多余的节点,这下好了,存在了不是终点就结束的字符串,那我们要怎样知道在'b'处存在一个为一个字符串终结点呢?
我们发现第四字符串并没有在原基础上再添加多余的节点,这下好了,存在了不是终点就结束的字符串,那我们要怎样知道在'b'处存在一个为一个字符串终结点呢?
答案很简单,做个标记就好了!
我们先暂时用褐色填充作为标记——————————————————————————————————————————

之后我们再完成添加第五个字符串的节点——————————————————————————————————————
 按照上面的套路来建立……
按照上面的套路来建立……
这样我们的Tire树就基本构建完毕了(注意是基本,还没完!)——————————————————————————————
我们还要给每个节点添加他们成为节点时的顺序(比如,'a'是第一个成为节点的字符,所以他标记为1,然后'a'的子节点'b'是第二个成为节点的字符,所以标记为2,然后依次按照字符成为节点的顺序标记顺序)
!!注意事项,已经标记过的字符保留最初的顺序!经过标记过的字符时,后面的字符的顺序都会减1

这样一个Trie树就完全构成了
----------------------------------------------------------------------------完美分割线----------------------------------------------------------------------------------------
3.Trie树的C代码构建方法
下面以这5个字符串为例子 {'abcd','aec','abd','ab','bbc'},我现在要用C代码来构建这个Trie树。
首先我们要创建一个整型二维数组来存储数据(你没有看错,就是整型二维数组)
现在假设我创建了一个 int s[100][30]; 的数组然后我们先看一下现在数组的样子
| 整型数组 | |||||||
| 列 行 | 0 | 1 | 2 | 3 | 4 | 5 | …… |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | |
| …… | |||||||
(在这里,我们将,行 中的0视为'a'的代号,1视为'b'的代号,3视为'c'的代号……)
我们要按一定的规律来进行数据的存储,下面将展示代码
#include<stdio.h>
#include<string.h>
int main()
{
int s[1000][30];
char temp_s; //临时字符
int totle=0,n,start; //totle为现在的字符顺序;
//stop_num记录字符串的终结字符对应的字符顺序号
int stop_num[100000],row_index;
scanf("%d",&n);
temp_s=getchar(); //这行代码是为了吸收输入数字时遗留下来的换行符
for(;n>0;n--){
start=0; //设定start为0
while(1){
//逐个吸收字符
scanf("%c",&temp_s);
//当该字符为换行符时代表改行字符串的结束,终止循环
if(temp_s=='\n') break;
//这里设'a'的位置为0,'b'的位置为1,以此类推
row_index=temp_s-'a';
//当对应的位置为为0时,对应的位置写上当前字符的顺序
if(s[start][row_index]==0) s[start][row_index]=++totle;
//将当前位置的值赋值给start
start=s[start][row_index];
}
//结束的start(顺序)处记为1,代表该顺序的字符为终结
stop_num[start]=1;
}
return 0;
} 下面将显示,完成上面一波操作后的数组状态(为了看得清楚,把0给省略掉了)
| 整型数组 | |||||||
| 列 行 | 0 | 1 | 2 | 3 | 4 | 5 | …… |
| 0 | 1 | 8 | |||||
| 1 | 2 | 5 | |||||
| 2 | 3 | 7 | |||||
| 3 | 4 | ||||||
| 4 | |||||||
| 5 | 6 | ||||||
| 6 | |||||||
| 7 | |||||||
| 8 | 9 | ||||||
| 9 | 10 | ||||||
| …… | |||||||
以及stop_num数组的状态(代表顺序 1,4,6,7,10的字符是字符串终止字符)
| 索引位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | …… |
| 值 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
这样我们就完成了Trie树的构建了—————————————————————————————————————————
----------------------------------------------------------------------------完美分割线----------------------------------------------------------------------------------------
4.Trie树的字符串查找方法
下面直接上代码
#include<stdio.h>
#include<string.h>
int main()
{
int s[1000][30];
char temp_s,temp_str[100]; //临时字符
int totle=0,n,start,i,len; //totle为现在的字符顺序;
//stop_num记录字符串的终结字符对应的字符顺序号
int stop_num[100000],col_index;
scanf("%d",&n);
temp_s=getchar(); //这行代码是为了吸收输入数字时遗留下来的换行符
for(;n>0;n--){
start=0; //设定start为0
while(1){
//逐个吸收字符
scanf("%c",&temp_s);
//当该字符为换行符时代表改行字符串的结束,终止循环
if(temp_s=='\n') break;
//这里设'a'的位置为0,'b'的位置为1,以此类推
col_index=temp_s-'a';
//当对应的位置为为0时,对应的位置写上当前字符的顺序
if(s[start][col_index]==0) s[start][col_index]=++totle;
//将当前位置的值赋值给start
start=s[start][col_index];
}
//结束的start(顺序)处记为1,代表该顺序的字符为终结
stop_num[start]=1;
}
//输入带匹配的字符串个数
scanf("%d",&n);
for(;n>0;n--){
start=0; //重设当前顺序为
scanf("%s",&temp_str);
len=strlen(temp_str); //获得当前字符串的长度
for(i=0;i<len;i++){
//当待匹配字符串完结,检测存储字符串也是否完结
if(i==len-1){
//检测存储字符串是否为终结字符串
if(stop_num[s[start][temp_str[i]-'a']]==1){
//若是则输出Match!
puts("Match!");
}
//否则输出Wrong!
else puts("Wrong!");
break; //终止循环
}
//获得字符的行坐标
col_index=temp_str[i]-'a';
//当选择到的位置不为0时,代表在该位置,该字符存在
if(s[start][col_index]!=0) start=s[start][col_index];
//不匹配时
else{
puts("Wrong!");
break;
}
}
}
return 0;
}读者可以自己写测试数据,本人也提供了一组测试数据如下
输入:
5
a
b
c
abc
ab
3
a
abe
f
输出:
Match!
Wrong!
Wrong!
以上就是Trie树的构建和搜索了,希望读者能从中明白Trie树这个数据结构。
如有不对或可以改进之处请写评论,谢谢您的指教!















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









