







实验链接
通过该实验了解文件恢复、数据提取的相关技术及应用、熟练掌握三款相关开源工具foremost、scalpel、bulk_exetractor的使用。
链接:http://www.hetianlab.com/expc.do?ce=6ca30fb8-e0c2-41f3-8335-731e91774df4
实验简介
实验所属系列: 数据安全
实验对象: 本科/专科信息安全专业
相关课程及专业: 系统安全
实验类别: 实践实验类
预备知识
-
关于foremost
Foremost是基于文件开始格式,文件结束标志和内部数据结构进行恢复文件的程序
Foremost参数说明
$ foremost[-v|-V|-h|-T|-Q|-q|-a|-w-d] [-t <type>] [-s <blocks>] [-k<size>] [-b <size>] [-c <file>] [-o<dir>] [-i <file] -V - 显示版权信息并退出 -t - 指定文件类型. (-t jpeg,pdf ...) -d -打开间接块检测 (针对UNIX文件系统) -i - 指定输入文件 (默认为标准输入) -a - 写入所有的文件头部, 不执行错误检测(损坏文件) -w - 向磁盘写入审计文件,不写入任何检测到的文件 -o - 设置输出目录 (默认为为输出) -c - 设置配置文件 (默认为foremost.conf) -q - 启用快速模式. 在512字节边界执行搜索. -Q - 启用安静模式. 禁用输出消息. -v - 详细模式. 向屏幕上记录所有消息 --------------------- -
Scalpel
对那些没有日志机制的旧有文件系统,scalpel 工具是一个很好的选择。scalpel 是快速文件恢复工具,通过读取文件系统的数据库来恢复文件。它是独立于文件系统的。
-
Bulk_exetractor
一个计算机取证工具,可以扫描磁盘映像、文件、文件目录,并在不解析文件系统或文件系统结构的情况下提取有用的信息,由于其忽略了文件系统结构,程序在速度和深入程度上都有了很大的提高
实验目的
通过该实验了解文件恢复、数据提取的相关技术及应用、熟练掌握三款相关开源工具foremost、scalpel、bulk_exetractor的使用。
实验环境
服务器:kali,IP地址:随机分配
测试脚本请在实验机内下载使用:http://tools.hetianlab.com/tools/T021.zip
实验步骤
步骤一
即使文件扩展名改变了或者被删去了,文件头部包含的信息可以识别出文件类型,并且通过文件头部和尾部的信息(文件开始格式,文件结束标志和内部数据结构进行恢复文件)可以尝试刻画出完整的文件数据提取是一个漫长的过程,建议使用自动化的工具来进行以节省时间。
一些常见的文件类型,当用16进制的编辑器打开时在文件头部打开时会包含如下信息:

本次实验专注于文件以及头部信息的分析与利用,通过上面提到的三个工具来进行本次的实验。
Foremost的使用
本次使用的镜像来自于互联网上开源的文件,可从此处下载 http://dftt.sourceforge.net/test11/index.html
Foremost是一款简单有效的命令行工具,通过分析文件头部和尾部的信息来恢复文件。通过kali左上角的application->11-Forensics->foremost启动:

启动后打开了一个终端:

关于程序的版本信息、开发人员以及一些使用选项都被呈现出来。
为了更好理解foremost和选项的使用,可以查阅foremost的系统管理员手册,输入man foremost:

在这个例子中主要用到的是两个选项,-i用于指定输入的文件,即前面下载的文件11-carve-fat.dd,-o用于指定一个空的文件夹,将其命名为foremost-recovery。通过foremost进行分析只需输入如下的命令就可以了:
foremost -i 11-carve-fat.dd -o foremost-recovery

尽管在处理过程中有些字符是乱码,但是结果已经在指定的输出的文件夹中被清楚的总结归类好了,打开foremost_recovey输出文件夹查看:

从上图可以看到被提取出来的文件,按照文件类型分门别类,同时还有个audit.txt,里面包含了分析过程中的详细信息,列出了foremost找到的所有文件以及文件偏移、大小规模等:

在audit.txt的最后,可以看到提取出的文件的总结:

可以看到有三个jpg的文件,这时可以在jpg子文件夹中查看:

可以看到foremost是一个的强大的数据恢复和文件提取的工具,文件提取所花的时间取决于源文件的规模,如果已经知道了所需提取文件的大小,可以使用使用 -t 来指定,然后进行提取,这样速度会更快。
比如指定只提取jpg:
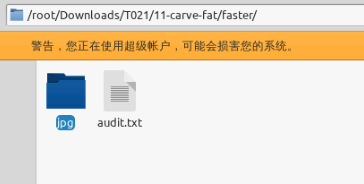
foremost -i 11-carve-fat.dd -t jpg -o faster
可以看到速度更快

不过生成的文件夹中也只有jpg一个子文件夹,同样有三张图片:
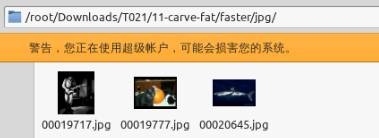
步骤二
Scalpel
Scalpel作为早期的foremost的升级版被开发出来,主要是针对解决foremost提取文件时高CPU占用率和ROM使用率的问题而开发。和Foremost不一样,所需提取的文件类型需要在scalpel的配置文件中设置。
配置文件的路径:
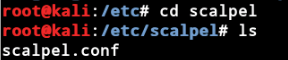
使用nano打开并修改,nano scalpel.conf
这是默认的:


在上图中可以看到所有类型的前面都被#注释了,如果需要使用scalpel提取某种类型的文件,将它前面的#删去就可以了。
请按照下图删除一些内容:
 也可以在文件中直接修改:
也可以在文件中直接修改:

这样的话,如果待提取文件中有gif,jpg,png,bmp则会被提取出来。
保存并退出,接下来输入scalpel启动它。
启动后会显示使用的语法、其他选项以及关于工具的其他信息:

为了便于对比,同样使用前面foremost实验的那个文件。
使用-o指定输出文件夹为scalpeloutput,后面跟着输入文件:
scalpel -o scalpeloutput/ 11-carve-fat.dd

从上图中可以看到提取出6个文件,其中gif1个,jpg5个。
打开输出的文件夹:
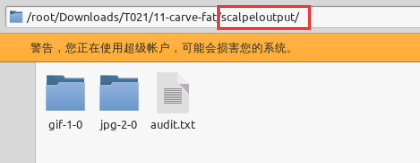
在jpg文件夹中虽然有5个,但是只有3个确实是jpg文件:

这可能是因为这两个文件恰好符合jpg文件的特征,但是本身可能是无意义的数据块,从而被scalpel错误地提取出来了。
提取的特征在前面那张截图中可以看到,jpg的特征是这样子的:

同样在audit.txt中可以看到详细的处理信息:

步骤三
Bulk_extractor
在前面的实验中我们可以看到,foremost和scalpel是比较有效的文件恢复和提取的工具,但是仅限于几种特定的类型,为了进一步的提取数据,使用Bulk_exetractor。
除了foremost、scalpel能提取的恢复、提取的数据外,Bulk_exetractor还可以提取的数据包括:信用卡号码、邮箱地址、url、网页信息等。
这次使用到的文件也是互联网上公开的,可以从http://downloads.digitalcorpora.org/corpora/scenarios/2009-m57-patents/drives-redacted/下载。
在使用Bulk之前,可以-h查看帮助说明:
bulk_extractor -h

这次使用从terry-work-usb-2009-12-11.E01中提取信息并将输出保存至bulk_output文件夹。
输入如下命令即可:
bulk_extractor -o bulk_output terry-work-usb-2009-12-11.E01

在分析工作结束后,bulk会显示所有线程都完成了,并且给出分析过程及提取出的信息的总结:

图中还能看到md5 hash、总共处理的MB,甚至还有3个邮件特征。
列出输出文件夹中的内容:
ls -l bulk_output/

需要注意的是,不是所有列出来的文件都包含数据。只有在月份左边的那些数字大于0的文件才包含数据。
在输出文件夹中可以看到很多独立的txt文件:

可以查看上图中列出的数字大于0的文件。
比如telephone.txt:

显示的都是电话号码。
url.txt:

显示的是浏览的网页和链接等。
总结
在本次实验中,通过三款工具,学习了文件恢复和数据提取的相关技能。首先通过CTF隐写类题目中最常见的工具Foremost来进行文件提取,它会通过扫描整个镜像来搜索支持的文件类型。
Scalpel针对同一个文件进行提取,只不过需要在配置文件中针对目标文件类型做些修改。这两款工具都提供了audit.txt来总结提取出的文件列表以及分析的详细信息。
Bulk_exetractor是一款十分出色的工具,被用来提取数据、发现隐藏的信息,在上面的实验中已经见识它的威力了。
答题
















 1291
1291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









