






一、指标计算链路
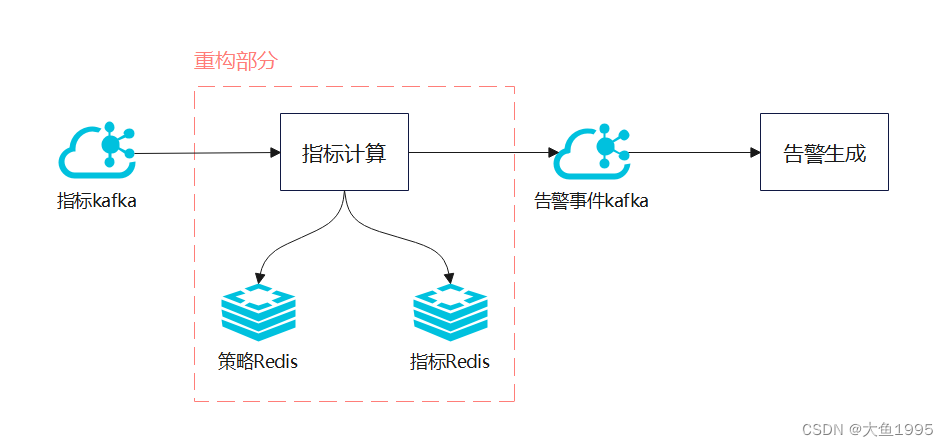
1. 指标kafka:经过清洗增维后的时序指标数据
关键信息:指标采集时间、资源ID、metric指标名称、tag标签(集群架构的实例ID、kafka的topic-groupId等信息)
2. 指标计算服务(重构部分):对【时序指标+告警策略】计算出告警或恢复事件
策略Redis:以资源维度存储该资源相关的告警策略(告警策略:指标+告警阈值)
指标Redis:存储计算的历史指标数据、策略抑制标识
3. 告警事件kafka:指标计算后的告警或者恢复事件
4. 告警生成服务:根据告警/恢复事件,生成告警并落库,发生通知到责任人
二、指标计算重构前流程
- 1. 根据资源ID从策略Redis查询告警策略列表
- 注:由于访问频繁,这里加多了一层本地缓存
- 2. 根据metric(指标)和tag(附加信息),对告警策略进行过滤
- 如果当前消费的kafka指标时序数据没有对应的策略,则结束流程
- 3. 循环遍历策略
- 3.1 根据【资源ID+tag+指标+策略ID】从指标Redis读出历史指标、抑制标识
- 3.2 根据策略规则,结合历史指标,计算本次结果是告警事件还是恢复事件
- 3.3 根据抑制标识,判断是否发送事件给下游(告警事件kafka)
- 3.4 更新指标Redis的历史指标,告警抑制标识
三、当前告警计算存在的问题
- 功能问题
- 1. 没有对指标采集时间去重,会造成误告警
- 比如上游在某一分钟重复推送异常数据,满足策略设置的连续x周期异常则产生告警
- 2. 没有对指标采集时间排序,会造成误告警
- 比如T1为正常指标、T2为异常指标,先消费T2产生告警后才消费T1导致误恢复
- 3. 没有对指标采集时间过滤,会造成误告警
- 如机器采集的时区不对,或者链路问题导致指标时间穿越,将无效指标也加入计算
- 4. 线程安全问题
- 多线程更新Redis的历史指标、告警抑制标识,会有覆盖写的风险
- 5. 代码难维护
- 双指标计算、严格周期匹配等问题修复代码引入较多特殊处理
- 6. 新功能迭代难展开
- 如双指标计算拓展为多指标计算,单层级指标计算拓展为多层级
- 1. 没有对指标采集时间去重,会造成误告警
- 性能问题
- 指标数据全网大概3000w/min,单节点峰值处理效率仅有50w/min,线上部署4套集群共120台节点
- 重构问题
- 资源指标告警核心业务功能,重构上线风险大
四、重构关键举措
1. 以指标维度存储历史指标数据,而非【策略+指标】维度,在双指标或多指标计算场景均可使用
2. 对指标采集时间进行过滤、去重、排序
- 过滤:对指标时间大于当前时间过多的数据进行无效的过滤,避免场景占用缓存
- 去重:对指标时间以分钟维度存储,同一分钟只能有一条指标数据,同时双指标的严格周期匹配更为精准
- 排序:对指标推送时间进行排序,避免阻塞或上游原因导致的乱序问题
3. 使用lua脚步追加历史指标缓存,并返回历史指标
- lua脚步的原子性可以避免多线程消费导致的覆盖写问题
- 减少Reids交互次数,由一读一写的两次操作变成lua脚步的一次操作
4. 访问Redis均使用pipeline管道模式进行批量操作,大幅度减少Redis交互,有效提高并发
- Redis处理简单命令的速度是微秒级别,但是网络IO是毫秒级别,通过批处理可以大幅提高程序性能
5. 访问策略Redis使用了本地缓存,还需要指标时序数据推送到指标kafka时,根据资源ID路由到kafka分区,这样可以大幅提高本地缓存的命中率,减少策略Redis的访问,减少内存消耗
6. 上线风险控制
- 重构上线时选择一个影响较小的集群,创建新的部署集群试运行,单独链路运行
- 消费指标kafka时用临时groupId
- 推送告警事件kafka时用临时topic
- 在并行跑一段时间,告警抑制标识都生效后,停掉旧链路并启用新链路进行验证
- 如果验证过程中有问题,需要切换回旧链路
五、指标计算重构后流程
- 1. 批量消费:根据资源ID列表去重后查询策略Redis
- 本地缓存没有的才去策略Redis读取
- 2. 根据metric(指标)和tag(附加信息),对告警策略进行过滤
- 如果当前消费的kafka指标时序数据没有对应的策略,则结束流程
- 3. 通过pipeline批量调用lua脚步,追加历史指标数据并返回历史指标
- 4. 根据策略规则,结合历史指标,计算本次结果是告警事件还是恢复事件
- 5. 通过pipeline批量调用lua脚步,追加告警抑制标识,并返回是否抑制
- 6. 根据抑制标识,判断是否发送事件给下游(告警事件kafka)
六、重构预期结果
1. 解决已知的误告警问题
2. Redis交互次数骤减,如默认一批消费是500指标数据
- 策略Redis:
- 重构前:最多访问500次,本地缓存没数据的情况下
- 重构后:只访问1次
- 指标Redis:
- 重构前:每次对历史指标和抑制标识进行读和写,总共500 * 4 = 2000次
- 重构后:只访问2次
3. 提高指标计算性能,通过demo预计单节点(4核8G)由50w/min可以提升至850w/min,3节点可达2200w/min,并且Redis各项指标没有明恶化趋势
- 线上120个节点可以缩容至6 - 10,容器资源节省110节点
- 之前由于性能瓶颈问题拆分的4套容器部署集群和4套Redis集群,可以只保留1套Redis
- 按华为云主机4核8G年费4k/年*110,Redis集群3主3从32G 3w/年* 3,释放资源可达到50w+/年
4. 更好的展开新迭代:多指标、多层级策略的计算
七、关键实现
lua脚本实现原子性追加指标(排序、去重,截取),并返回追加后的历史指标数据
- KEYS[1]:资源ID,以资源ID维度的hash结构进行数据存储
- ARGV[1]:hash结构的field字段,以tag+metric作为field
- ARGV[2]:通过“|”拼接采集时间以及指标值,存储时进行排序
- ARGV[3]:历史数据存储的最大元素数量,由业务的最大监测周期决定
-- LUA标准库没有string.split函数,需要自定义
local function split(str, delimiter)
local result = {}
local pattern = string.format('([^%s]+)', delimiter)
for word in string.gmatch(str, pattern) do
table.insert(result, word)
end
return result
end
-- 将范围内元素往后挪一位
local function shiftElements(table, startIdx, endIdx)
for i = endIdx, startIdx, -1 do
table[i + 1] = table[i]
end
end
-- 获取输入参数 key(资源ID)、field(tag+metric)、value(采集时间|指标值)、historyMaxCount(历史指标存储最大数量)
local key = KEYS[1]
local field = ARGV[1]
local value = ARGV[2]
local historyMaxCount = tonumber(ARGV[3])
-- 时间与指标值的分隔符
local splitStr = '|'
-- 新指标的时间戳
local newTime = tonumber(split(value, splitStr)[1])
-- 从Redis获取历史指标
local historyValues = redis.call('HGET', key, field)
if not historyValues then
redis.call('HSET', key, field, value)
return value
end
-- 历史指标切分
local arr = split(historyValues, ',')
-- 历史指标是已经排序好的,新的指标一般都是最后的,从后到前进行遍历进行插入
local count = #arr
for i = count, 1, -1 do
local oldTime = tonumber(split(arr[i], splitStr)[1])
-- 如果存在采集时间相等的情况,直接替换
if oldTime == newTime then
arr[i] = value
redis.call('HSET', key, field, table.concat(arr, ','))
return table.concat(arr, ',')
end
-- 新指标大于旧指标时间
if oldTime < newTime then
-- 从i+1的位置进行插入,所有元素往后挪一位
if i < count then
shiftElements(arr, i + 1, count)
end
arr[i + 1] = value
break
end
end
-- 如果从后到前遍历后元素数量没有变化,则标识最新的指标采集时间小于所有指标
if count == #arr then
shiftElements(arr, 1, count)
arr[1] = value
end
-- 如果历史指标数量超过最大限制,需要进行截取
local resultValue
if #arr > historyMaxCount then
resultValue = table.concat(arr, ',', #arr - historyMaxCount + 1, #arr)
else
resultValue = table.concat(arr, ',')
end
redis.call('HSET', key, field, resultValue)
redis.call('EXPIRE', key, 3600)
return resultValueJava关键实现:
- 程序启动时postConstruct钩子上传lua脚本到Redis服务器,返回sha1编号
- 通过pipeline管道批量调用脚本 evalsha <sha1> 并返回结果
private String SCRIPT_APPEND_METRIC_SHA1 = null;
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private ResourceLoader resourceLoader;
@PostConstruct
public void postConstruct() {
log.info("init script append metric");
Resource resource = resourceLoader.getResource("classpath:lua\\metric_append.lua");
try (InputStream inputStream = resource.getInputStream()) {
byte[] bytes = FileCopyUtils.copyToByteArray(inputStream);
String script = new String(bytes, StandardCharsets.UTF_8);
redisTemplate.execute((RedisCallback<String>) redisConnection ->
SCRIPT_APPEND_METRIC_SHA1 = redisConnection.scriptLoad(script.getBytes(StandardCharsets.UTF_8))
);
log.info("init script append metric end, SHA1: {}", SCRIPT_APPEND_METRIC_SHA1);
} catch (Exception exception) {
log.error("init script append metric error", exception);
}
}
public void test(){
// pipeline批量调用lua脚步,返回追加后的指标
List<Object> resultList = redisTemplate.executePipelined((RedisCallback<String>) connection -> {
String key = "metric_append:" + message.getHrn();
String field = message.getMetric() + message.getTag();
String value = message.getDate().getTime() / 1000 / 60 * 60 + "|" + message.getValue();
connection.evalSha(SCRIPT_APPEND_METRIC_SHA1, ReturnType.fromJavaType(String.class), 1, key.getBytes(StandardCharsets.UTF_8),
field.getBytes(StandardCharsets.UTF_8), value.getBytes(StandardCharsets.UTF_8), "10".getBytes(StandardCharsets.UTF_8));
return null;
});
}















 3246
3246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









