






CompletableFuture:组合式异步编程
让代码免受阻塞之苦
使用 CompletableFuture 发起异步请求
可以使用工厂方法supplyAsync创建CompletableFuture对象:
List<CompletableFuture<String>> priceFutures = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f", shop.getName(), shop.getPrice(product))))
.collect(toList());
使用这种方式,你得到一个List<CompletableFuture<String>>,列表中的每个CompletableFuture对象在计算完成后都包含商店的String类型的名称。但是,由于用CompletableFutures实现findPrices方法要求返回一个List<String>,需要等待所有的future执行完毕,将其包含的值抽取出来,填充到列表中才能返回。
为了实现这个效果,可以向最初的List<CompletableFuture<String>>施加第二个map操作,对List中的所有future对象执行join操作,一个接一个地等待它们运行结束。注意CompletableFuture类中的join方法和Future接口中的get有相同的含义,并且也声明在Future接口中,它们唯一的不同是join不会抛出任何检测到的异常。使用它你不再需要使用try/catch语句块让你传递给第二个map方法的Lambda表达式变得过于臃肿。所有这些整合在一起,你就可以重新实现findPrices了,具体代码如下。
public List<String> findPrices(String product) {
List<CompletableFuture<String>> priceFutures = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(//使用CompletableFuture以异步方式计算每种商品的价格
() -> shop.getName() + " price is " + shop.getPrice(product)))
.collect(Collectors.toList());
return priceFutures.stream()
.map(CompletableFuture::join)//等待所有异步操作结束
.collect(toList());
}
这里使用了两个不同的Stream流水线,而不是在同一个处理流的流水线上一个接一个地放置两个map操作——这其实是有缘由的。考虑流操作之间的延迟特性,如果你在单一流水线中处理流,发向不同商家的请求只能以同步、顺序执行的方式才会成功。因此,每个创建CompletableFuture对象只能在前一个操作结束之后执行查询指定商家的动作、通知join方法返回计算结果。下图解释了这些重要的细节。
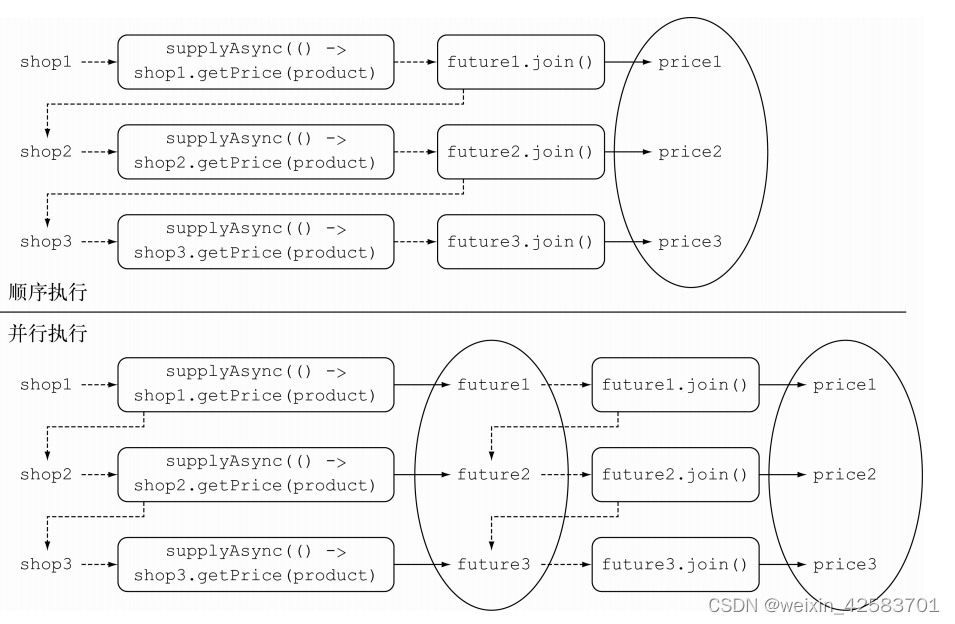
上图的上半部分展示了使用单一流水线处理流的过程,执行的流程(以虚线标识)是顺序的。事实上,新的CompletableFuture对象只有在前一个操作完全结束之后,才能创建。与此相反,图的下半部分展示了如何先将CompletableFutures对象聚集到一个列表中(即图中以椭圆表示的部分),让对象们可以在等待其他对象完成操作之前就能启动。运行代码上面的代码来了解下第三个版本findPrices方法的性能,你会得到下面这几行输出:
[BestPrice price is 123.26, LetsSaveBig price is 169.47, MyFavoriteShop price
is 214.13, BuyItAll price is 184.74]
Done in 2005 msecs
这个结果让人相当失望,超过2秒意味着利用CompletableFuture实现的版本,比刚最开始的代码中原生顺序执行且会发生阻塞的版本快。但是它的用时也差不多是使用并行流的前一个版本的两倍。尤其是,考虑到从顺序执行的版本转换到并行流的版本只做了非常小的改动,就让人更加沮丧。与此形成鲜明对比的是,为采用CompletableFutures完成的新版方法做了大量的工作!但,这就是全部的真相吗?这种场景下使用CompletableFutures真的是浪费时间吗?或者我们可能漏掉了某些重要的东西?继续往下探究之前,想想你测试代码的机器是否足以以并行方式运行四个线程。
寻找更好的方案
并行流的版本工作得非常好,那是因为它能并行地执行四个任务,所以它几乎能为每个商家分配一个线程。但是,如果你想要增加第五个商家到商店列表中,让你的“最佳价格查询”应用对其进行处理,这时会发生什么情况?毫不意外,顺序执行版本的执行还是需要大约5秒多钟的时间,下面是执行的输出(使用顺序流方式的程序输出):
[BestPrice price is 123.26, LetsSaveBig price is 169.47, MyFavoriteShop price
is 214.13, BuyItAll price is 184.74, ShopEasy price is 176.08]
Done in 5025 msecs
使用顺序流方式的程序输出
非常不幸,并行流版本的程序这次比之前也多消耗了差不多1秒钟的时间,因为可以并行运行(通用线程池中处于可用状态的)的四个线程现在都处于繁忙状态,都在对前4个商店进行查询。第五个查询只能等到前面某一个操作完成释放出空闲线程才能继续,它的运行结果如下(使用并行流方式的程序输出):
[BestPrice price is 123.26, LetsSaveBig price is 169.47, MyFavoriteShop price
is 214.13, BuyItAll price is 184.74, ShopEasy price is 176.08]
Done in 2177 msecs
使用并行流方式的程序输出
CompletableFuture版本的程序结果如何呢?添加第5个商店对其进行测试,结果如下(使用CompletableFuture的程序输出):
[BestPrice price is 123.26, LetsSaveBig price is 169.47, MyFavoriteShop price
is 214.13, BuyItAll price is 184.74, ShopEasy price is 176.08]
Done in 2006 msecs
使用CompletableFuture的程序输出
CompletableFuture版本的程序似乎比并行流版本的程序还快那么一点儿。但是最后这个版本也不太令人满意。比如,如果你试图让你的代码处理9个商店,并行流版本耗时3143毫秒,CompletableFuture版本耗时3009毫秒。它们看起来不相伯仲,究其原因都一样:它们内部采用的是同样的通用线程池,默认都使用固定数目的线程,具体线程数取决于Runtime. getRuntime().availableProcessors()的返回值。然而,CompletableFuture具有一定的优势,因为它允许你对执行器(Executor)进行配置,尤其是线程池的大小,让它以更适合应用需求的方式进行配置,满足程序的要求,而这是并行流API无法提供的。让我们看看怎样利用这种配置上的灵活性带来实际应用程序性能上的提升。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









