







首先弄清身份证18位的构成(这里只讲18位的 ):
| 位数 | 作用 |
|---|---|
| 第1、2位数字 | 表示所在省份的代码 |
| 第3、4位数字 | 表示所在城市的代码 |
| 第5、6位数字 | 表示所在区县的代码 |
| 第7~14位数字 | 表示出生年、月、日(1到9的月份和日用01到09表示) |
| 第15、16位数字 | 表示所在地的派出所的代码 |
| 第17位数字 | 表示性别,奇数表示男性,偶数表示女性 |
| 第18位数字 | 是校检码,是随计算机的随机产生, 用来检验身份证的正确性。校检码可以是0~9的数字,当校验码为10时,则在身份证上用X代替显示,以符合国家公民身份证要求标准。 |
我们要用的就是第7~14位和第17位,来获取出生日期和性别
先来看一下sql和查询结果
select substr('123456198909210248',7,8) AS BRITH,
regexp_replace(
regexp_substr(substr('123456198909210248',17,1 ),'^\d*[13579]$') ,'^\d*[13579]$','男'
)||regexp_replace(
regexp_substr(substr('123456198909210248',17,1 ),'^\d*[02468]$') ,'^\d*[02468]$','女'
)AS SEX
from dual
查询结果:
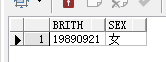
让我们一起来看看sql代码:
1、substr函数 格式: substr(string string, int a, int b)
(1)string 需要截取的字符串
(2)a截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取)
(3)b 要截取的字符串的长度
而这里substr(‘123456198909210248’,7,8) 就表示截取证件号的第7~14位数字即出生日期
2、再看一下正则式
^\d*[13579]$
我们逐个了解各个字符的含义
| 字符 | 含义 |
|---|---|
| ^ | 匹配一个字符串的开始。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的开头。 |
| \b | 匹配一个数字字符。 |
| * | 匹配零个或多个。 |
| [ ] | 用于指定一个匹配列表,您尝试匹配列表中的任何一个字符。 |
| $ | 匹配字符串的结尾。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的末尾。 |
这个式子就表示匹配10以内的奇数,同理
^\d*[02468]$
就表示匹配10以内的偶数
3、regexp_substr(expression, regexp) --返回满足条件的字符或字符串,
regexp_substr(substr(‘123456198909210248’,17,1 ),’^\d*[13579]$’)
就表示只返回奇数(偶数的只返回偶数)
4、 regexp_replace(expression, regexp, replacement) --将expression中的按regexp匹配到的部分用replacement代替.
regexp_replace(
regexp_substr(substr('123456198909210248',17,1 ),'^\d*[13579]$') ,'^\d*[13579]$','男'
)
就表示若为奇数返回男,若为偶数返回空,
regexp_replace(
regexp_substr(substr('123456198909210248',17,1 ),'^\d*[02468]$') ,'^\d*[02468]$','女'
)AS SEX
就表示若为偶数返回女,若为奇数返回空
将这两个用 || 拼接起来就能实现若为奇数返回男,若为偶数返回女
5、常用的正则式字符
| 字符 | 含义 |
|---|---|
| ^ | 匹配一个字符串的开始。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的开头。 |
| $ | 匹配字符串的结尾。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的末尾。 |
| * | 匹配零个或多个。 |
| + | 匹配一个或多个出现。 /^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+(\.{1,2}[a-z]+)+$/ |
| ? | 匹配零次或一次出现。 |
| 。 | 匹配任何字符,除了空。 |
| [ ] | 用于指定一个匹配列表,您尝试匹配列表中的任何一个字符。 |
| [^] | 用于指定一个不匹配的列表,您尝试匹配除列表中的字符以外的任何字符。 |
| ( ) | 用于将表达式分组为一个子表达式。 |
| {M} | 匹配m次。 |
| {M,} | 至少匹配m次。 |
| {M,N} | 至少匹配m次,但不多于n次。 |
| \n | n是1到9之间的数字。在遇到\ n之前匹配在()内找到的第n个子表达式。 |
| [ . . ] | 匹配一个可以多于一个字符的整理元素。 |
| [:] | 匹配字符类。 |
| [==] | 匹配等价类。 |
| \d | 匹配一个数字字符。 |
| \D | 匹配一个非数字字符。 |
| \w | 匹配包括下划线的任何单词字符。 |
| \W | 匹配任何非单词字符。 |
| \s | 匹配任何空白字符,包括空格,制表符,换页符等等。 |
| \S | 匹配任何非空白字符。 |
| \A | 在换行符之前匹配字符串的开头或匹配字符串的末尾。 |
| \Z | 匹配字符串的末尾。 |
| *? | 匹配前面的模式零次或多次发生。 |
| +? | 匹配前面的模式一个或多个事件。 |
| ?? | 匹配前面的模式零次或一次出现。 |
| {N}? | 匹配前面的模式n次。 |
| {N,}? | 匹配前面的模式至少n次。 |
| {N,M}? | 匹配前面的模式至少n次,但不超过m次。 |
| 用途 | 表达式 |
|---|---|
| 用户名 | /^[a-z0-9_-]{3,16}$/ |
| 密码 | /^[a-z0-9_-]{6,18}$/ |
| 十六进制 | /^#?([a-f0-9]{6}|[a-f0-9]{3})$/ |
| 电子邮箱 | /^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/ /^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+(\.{1,2}[a-z]+)+$/ |
| URL | /^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/ |
| IP地址 | /((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)/ /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/ |
| HTML标签 | /^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/ |
| 删除代码\\注释 | (?<!http:|\S)//.*$ |
| Unicode编码中的汉字范围 | /^[\u2E80-\u9FFF]+$/ |














 1908
1908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









