




简介:快速傅里叶变换(FFT)是高效计算离散傅里叶变换(DFT)的方法,广泛应用于信号分析、图像处理等领域。本文将深入解析FFT算法原理,包括其基本思想、二分FFT、Cooley-Tukey算法、翻转与位移,并通过实例展示其在信号分析、图像处理、通信工程、数字信号处理和数据分析中的实际应用。同时,探讨了提高FFT计算效率的优化策略。
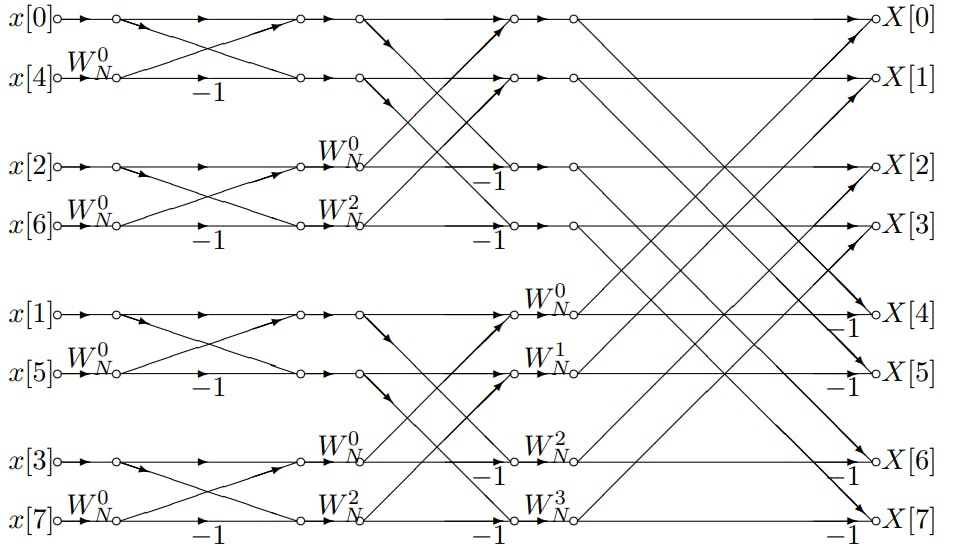
1. FFT算法原理
快速傅里叶变换(FFT)是一种高效计算离散傅里叶变换(DFT)及其逆变换的算法。在数字信号处理、图像处理、音频分析等多个领域中,FFT发挥着至关重要的作用。其基本思想是将长序列的DFT拆分成多个较短序列的DFT进行计算。FFT算法相比于直接计算DFT的方法,大大减少了计算量,其核心在于利用了DFT的周期性和对称性属性。
1.1 傅里叶变换简介
傅里叶变换是一种数学变换,用于将信号从时域转换到频域。该变换揭示了信号的频率成分,即信号中各个频率分量的幅度和相位。而FFT作为一种数值方法,能够快速计算连续傅里叶变换的近似值,极大地提高了计算效率。
1.2 DFT与FFT的区别
离散傅里叶变换(DFT)是对连续傅里叶变换的一种近似,适用于数字信号处理。然而,直接计算DFT的复杂度为O(N^2),对于长序列数据处理是不切实际的。FFT算法通过分治策略将DFT的计算复杂度降低至O(NlogN),在时间效率上实现了巨大的突破。
在下一章中,我们将详细探讨二分FFT的执行流程,并分析其时间复杂度,从而更深入地理解FFT算法的高效性。
2. 二分FFT执行流程
2.1 二分FFT算法的步骤
2.1.1 输入序列的分割
输入序列的分割是二分FFT(快速傅里叶变换)算法的初始步骤。在这一阶段,算法将一个复数序列分成两个较短的子序列,以便进行递归处理。假设我们有一个长度为N的输入序列 X[0] 到 X[N-1] ,其中N是2的幂。二分FFT首先将序列分为两个等长的部分:一个是偶数索引序列 X[0] , X[2] , X[4] , …, X[N-2] ,另一个是奇数索引序列 X[1] , X[3] , X[5] , …, X[N-1] 。这是因为基于离散傅里叶变换(DFT)的性质,可以将原序列的DFT分解为两个较小DFT的组合。
对于一般的二分FFT,我们通常采用蝶形操作对数据进行重新组合。这种分割方法是高效且易于实现的。下面是分割序列的基本步骤:
- 初始化一个长度为N的数组
X,填充输入序列。 - 创建两个临时数组
X_even和X_odd,用于存放分割后的子序列。 - 通过循环,将
X中的偶数索引元素分配到X_even,奇数索引元素分配到X_odd。 - 确保
X_even和X_odd的长度都是N/2。
2.1.2 递归子序列处理
分割后,我们分别对偶数索引子序列 X_even 和奇数索引子序列 X_odd 进行递归处理。由于这两部分都是原序列长度的一半,因此递归的深度可以减少,最终达到降低整体计算复杂度的目的。
递归处理的步骤可以概括如下:
- 对
X_even和X_odd执行二分FFT算法。 - 这一步骤是重复的。对于每一个长度为N/2的子序列,算法继续将其分成两个长度为N/4的子序列,并继续递归。
- 递归将继续进行,直到子序列的长度达到1或者2。此时,可以直接计算出该长度为1或2的DFT。
2.1.3 合并子序列结果
在递归过程结束后,我们需要将所有子序列的DFT结果合并,以得到原始序列的DFT。这个合并过程同样涉及蝶形操作,它根据输入序列的频率分量将子序列重新组合。合并步骤的关键在于正确地应用旋转因子(twiddle factors)。
合并子序列的步骤如下:
- 对于每个子序列的DFT结果,计算对应的旋转因子。
- 使用蝶形操作和旋转因子,将
X_even和X_odd的结果组合起来,形成更长序列的DFT。 - 重复这个过程,直到最后达到原始序列的长度。
2.2 二分FFT的时间复杂度分析
2.2.1 理论时间复杂度推导
二分FFT算法的时间复杂度是通过递归深度来决定的。对于长度为N的输入序列,二分FFT的递归深度为 log2(N) ,因为每次递归都将序列长度减半。每一层递归都包含 N/2 个蝶形操作,因此每层递归的时间复杂度是O(N/2)。
将所有递归层的时间复杂度加起来,我们可以得到整个算法的时间复杂度:
总时间复杂度 = O(N) * log2(N)
这表示二分FFT的时间复杂度比原始的DFT算法低得多,后者的时间复杂度为O(N^2)。
2.2.2 实际应用中的时间消耗
在实际应用中,二分FFT的时间消耗不仅仅取决于理论时间复杂度,还受到实现方式、硬件性能以及优化技巧的影响。例如,现代的硬件平台提供了快速的浮点数运算单元和向量化指令集,这对于提高FFT的计算效率至关重要。
优化FFT性能的方法包括:
- 使用缓存友好的数据访问模式。
- 利用循环展开技术减少循环的开销。
- 在支持并行计算的硬件上运行算法,如GPU或多核心处理器。
为了实现这些优化,通常需要编写与平台密切相关的代码。不过,由于FFT算法的广泛使用,许多库已经内置了这些优化,使得开发者可以较为简单地获得性能提升。
3. Cooley-Tukey算法介绍
3.1 Cooley-Tukey算法的历史背景
3.1.1 算法的起源和发展
Cooley-Tukey算法是在1965年由James Cooley和John Tukey提出的,它的出现是数字信号处理历史上的一次重大突破。在此之前,快速傅里叶变换(FFT)的高效算法并不存在,导致频域分析的计算量巨大,难以应用于实际问题。在FFT出现之前,傅里叶变换通常需要O(N^2)的计算复杂度,其中N是采样点数。这在计算机技术还不发达的年代,对于长序列数据的处理几乎是不可接受的。
Cooley和Tukey的算法将这一复杂度降低到了O(NlogN),大大提高了计算效率。这一成就使得FFT成为了一个实用工具,尤其是在信号处理、图像处理、音频处理和无线通信等领域中。
该算法的提出基于对特定长度序列的傅里叶变换进行分治处理。其核心思想是将长序列数据分成多个短序列,然后利用周期性将复杂的离散傅里叶变换(DFT)简化为一系列短序列的DFT计算,最后将这些短序列的DFT结果组合起来,得到原长序列的DFT结果。
3.2 Cooley-Tukey算法的特点
3.2.1 算法的主要贡献和改进点
Cooley-Tukey算法的主要贡献在于其引入的分治策略和位逆序排列思想。该算法假设输入序列长度N是2的幂次,从而能够将原始的DFT问题分解为两个较小的DFT问题。这一策略的数学基础是基于复数的性质以及DFT的对称性质。
改进点之一是输入数据的位逆序排列,这是为了保证在递归过程中可以有效地利用DFT的周期性和对称性。位逆序排列的引入,使得原本看似无序的输入数据,在经过FFT处理后能够呈现出有序的频谱信息。这一点对于理解FFT算法的内部机制至关重要。
3.3 Cooley-Tukey算法与其他FFT算法比较
3.3.1 算法效率和适用范围
Cooley-Tukey算法的效率在N为2的幂次时表现得尤其出色,这也是其在数字信号处理中得到广泛应用的原因之一。然而,当序列长度N不满足2的幂次时,算法需要进行适当的修改或扩展,例如引入填充零的操作。
与其它FFT算法相比,如Rader算法、Bluestein算法等,Cooley-Tukey算法在处理具有特定长度限制的数据时更高效。针对不同长度的序列数据,其他算法如Winograd算法可能在计算复杂度上有更进一步的优化,但算法实现复杂度较高,而Cooley-Tukey算法则在实现复杂度和效率之间取得了良好的平衡。
由于Cooley-Tukey算法的这些优点,它成为了工程实践中最常用的FFT算法之一。不过,需要注意的是,它并不是唯一的FFT算法,针对不同的应用场景和特定的数据长度,有时会选择其他更适合的FFT变种。
现在,我们可以用一个简单的代码示例来说明Cooley-Tukey算法的基本原理。这里提供一个简单的Python实现,用于展示FFT的核心思想:
import numpy as np
def fft(x):
N = len(x)
if N <= 1: return x
even = fft(x[0::2])
odd = fft(x[1::2])
T = [np.exp(-2j * np.pi * k / N) * odd[k] for k in range(N // 2)]
return [even[k] + T[k] for k in range(N // 2)] + [even[k] - T[k] for k in range(N // 2)]
# 示例输入数据
data = np.array([0.0, 1.0, 0.0, -1.0])
# 执行FFT
fft_result = fft(data)
print("FFT result:", np.round(fft_result, 3))
在这段代码中,我们实现了FFT的基本步骤。首先检查数据长度,如果长度小于等于1,直接返回。否则,我们将输入数据分为偶数项和奇数项两个序列,分别进行递归调用。然后,计算旋转因子并将结果合并,最终得到FFT的输出。这个简单的实现演示了Cooley-Tukey算法如何将一个长序列的DFT分解为更小的子问题,并高效地组合结果。
代码中的旋转因子 exp(-2j * np.pi * k / N) 就是基于复数的指数函数,它反映了FFT算法中利用复数性质来简化计算的原理。这个旋转因子确保了我们能够利用DFT的对称性和周期性来减少计算量。
需要注意的是,这个代码示例仅用于演示FFT算法的基本原理,并没有考虑性能优化,实际应用中,一般会使用高度优化过的库函数,如NumPy中的 np.fft.fft 函数,以达到更佳的性能。
# 使用NumPy库的FFT实现
fft_result_numpy = np.fft.fft(data)
print("NumPy FFT result:", np.round(fft_result_numpy, 3))
通过比较两种实现结果,我们可以验证我们的简单FFT实现与NumPy库实现是否一致,进一步加深对FFT算法的理解。
4. 输入序列位翻转与位移的重要性
4.1 位翻转(Bit-reversal)的概念与意义
4.1.1 位翻转的数学原理
位翻转是FFT算法中一个关键步骤,其目的是重新排列输入序列的位序,使得序列中的元素顺序符合特定的顺序。在数学上,位翻转可以通过交换二进制表示中对应位置的比特来实现。位翻转操作等价于将序列的索引从线性序列重新映射到其蝶形运算图中的位置。
例如,对于长度为8的输入序列,其索引从0到7,经过位翻转后,原本的索引顺序为0,1,2,3,4,5,6,7,翻转后将变为0,4,2,6,1,5,3,7。
位翻转操作确保了FFT算法中的蝶形运算能够按照正确的顺序进行,因为蝶形运算依赖于特定的输入顺序来保持数据的依赖性。
4.1.2 位翻转在FFT中的作用
在FFT算法中,位翻转操作确保了数据流的正确路径。如果没有位翻转,FFT算法将不能正确地执行,因为算法在执行蝶形运算时需要按特定顺序访问数据点。
通过位翻转,我们可以保证在每一轮递归处理中,输入的子序列都是按照计算上的要求来排列的。这一过程对于FFT算法能够正确执行至关重要,是算法效率和准确性的关键所在。
4.2 序列位移的实现方法
4.2.1 位移操作的算法实现
序列位移是FFT算法中另一个重要的步骤。位移操作通常发生在递归或迭代处理的子序列中。在这个过程中,序列被分割成更小的部分,并且每一部分的元素都会发生位移变化。这种变化使得每个子序列在进行蝶形运算之前都调整到正确的相位。
位移操作一般通过在序列的每个元素上乘以一个2的幂次方因子来实现。这可以看作是在频域上对信号进行移位的一种形式,从而在FFT输出时将信号的特定部分移动到频谱的中心。
4.2.2 位移对计算效率的影响
正确的位移操作可以提高FFT算法的计算效率。这主要是因为位移操作能够减少蝶形运算中不必要的乘法和加法操作,特别是在处理复数数据时。
在实现位移操作时,必须仔细处理索引和位操作,以确保位移的正确性和算法的运行速度。通过优化位移步骤,FFT算法可以达到接近理论上的时间复杂度,从而在信号处理和数据分析中发挥最大的性能。
graph TD;
A[FFT开始] --> B[输入序列位翻转]
B --> C[递归或迭代处理]
C --> D[子序列位移]
D --> E[蝶形运算]
E --> F[合并子序列结果]
F --> G[FFT结果]
在上述的流程图中,展示了FFT算法中位翻转和位移步骤在整体处理流程中的位置和作用。它强调了这两个步骤对于整个FFT算法流程的重要性,并说明了它们是如何协同工作的以确保算法的正确执行和效率。
位翻转和位移操作对于理解和实现FFT算法具有重要意义,它们不仅关系到算法的正确性,而且对算法效率的提升也有着直接的影响。在信号处理和图像分析等应用领域,掌握这些操作原理和实践技巧对于开发高效的算法和程序来说是不可或缺的。
5. 信号分析中的FFT应用
5.1 FFT在信号分析中的基本原理
5.1.1 信号频谱分析的基础
频谱分析是信号处理领域中的一项基础而关键的任务,它涉及将时域信号转换到频域,以便于观察和分析信号的频率成分。传统的方法是通过积分变换,如傅里叶变换,将时域信号转换为频域信号。这种方法在数学上是准确的,但在计算机上实现时,直接计算整个傅里叶变换非常耗时,尤其是在处理长序列时。
快速傅里叶变换(FFT)的出现极大地改进了这一过程。FFT是傅里叶变换的一种高效算法,主要针对长度为2的幂次的序列进行优化。它利用信号序列的对称性和周期性,将长序列分解为多个较短的子序列进行运算。FFT算法大幅度减少了计算次数,从而大大加快了变换速度。
5.1.2 FFT在频谱分析中的优势
在信号处理中,FFT相比于传统的傅里叶变换,最明显的优势就是速度。FFT算法的时间复杂度为O(NlogN),而直接计算傅里叶变换的时间复杂度为O(N^2),对于大规模数据集而言,FFT能显著减少运算时间,从而提高分析效率。
除此之外,FFT算法的另一个显著优势是其对信号频域特性的清晰展现。通过FFT转换后的频谱,可以明确看到信号中各个频率成分的分布情况,这对于噪声检测、频率分析、系统辨识等应用来说至关重要。在工程应用中,FFT还常常与窗函数结合使用,可以减小频谱泄漏,提高信号处理的准确性。
5.1.3 FFT在信号分析中的应用实例
信号分析中的FFT应用包括但不限于以下领域:
-
音频信号处理 :在音乐、通信、语音识别等领域中,对音频信号的频谱分析可以帮助我们更好地理解信号的结构和内容,例如分析乐器的音色或人的语音特性。
-
无线通信 :在无线通信系统中,频谱分析可以用来确定信号的频率分布,便于信号的过滤和调制。
-
地震数据处理 :在地球物理勘探中,FFT用于分析地震波形数据,以识别不同岩层的特性。
5.2 FFT在信号处理中的实际案例
5.2.1 音频信号的频谱分析
在音频信号处理中,频谱分析能帮助我们了解音频信号中包含哪些频率成分,从而对音频信号进行分类、质量评估或编辑。例如,在音乐制作中,通过FFT分析,音频工程师可以精确地控制音频的均衡器(EQ)来增强或减弱某些特定的频率成分。
音频信号频谱分析的实现可以通过以下步骤进行:
-
信号采集 :首先需要采集到音频信号,这可以通过麦克风等设备进行。
-
信号预处理 :根据需要,对信号进行滤波、放大等预处理操作。
-
采样和量化 :将模拟信号转换为数字信号,这一步通常通过模数转换器(ADC)实现。
-
FFT变换 :将处理后的数字信号进行快速傅里叶变换,得到频谱信息。
-
频谱分析 :根据频谱信息,进行进一步的分析和处理。
以下是使用Python语言和numpy库实现音频信号频谱分析的简单示例:
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
# 读取音频文件
rate, data = wavfile.read('audio.wav')
# 频谱分析
fft_result = np.fft.fft(data)
fft_freq = np.fft.fftfreq(len(data), 1/rate)
# 绘制频谱图
plt.plot(fft_freq, np.abs(fft_result))
plt.title('Audio Spectrum Analysis')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.show()
在上述代码中,我们读取一个名为 audio.wav 的音频文件,然后执行FFT变换,最后绘制出信号的频谱图。这个图表可以帮助我们直观地看到不同频率成分的强度,从而进行进一步的音频处理。
5.2.2 振动信号的频域诊断
振动信号分析是机械系统故障诊断中的一个重要领域,特别是在预测性维护方面。通过振动信号的频谱分析,我们可以检测出设备潜在的故障模式,如不平衡、不对中、轴承缺陷等。
使用FFT对振动信号进行频谱分析的基本步骤如下:
-
信号采集 :使用振动传感器收集设备运行时的振动数据。
-
信号预处理 :将采集到的模拟信号转换成数字信号,并进行滤波和降噪处理。
-
FFT变换 :对预处理后的数据执行快速傅里叶变换,得到信号的频谱信息。
-
频域分析 :根据频谱分析结果,识别出设备的异常频率成分,推断可能的故障类型。
-
状态监测和预测 :结合设备的历史数据和经验知识,对设备未来的运行状态进行预测。
在机械系统的振动分析中,FFT同样可以大大减少分析的时间和提高准确性,从而有助于及时维护和减少停机时间。
6. 图像处理中的FFT应用
6.1 图像处理中FFT的基础概念
6.1.1 图像的频率域与空间域
在图像处理领域中,图像通常可以用空间域和频率域两种方式来描述。空间域描述是直接针对图像的像素值进行操作和分析,而频率域则是通过傅里叶变换将图像信息从空间域转换到频率域。频率域分析图像可以让我们从频谱的角度理解图像内容,这对于图像去噪、增强、压缩等操作提供了新的视角。
傅里叶变换(Fourier Transform)是将图像从空间域变换到频率域的关键工具。它把图像分解成不同频率的正弦和余弦波,每一个波对应于图像的一个频率成分。图像中的每一个像素点都与这些频率成分相对应,因此,通过分析这些频率成分,我们可以对图像进行深入的处理。
6.1.2 FFT在图像处理中的作用
快速傅里叶变换(Fast Fourier Transform,FFT)是傅里叶变换的一种快速实现算法,其在图像处理中的作用举足轻重。FFT可以大大减少变换所需的时间,使得图像在频率域内的操作变得可行,特别是在实时处理或处理大尺寸图像时。
利用FFT,我们可以在频率域中实现图像的滤波、压缩和特征提取等操作。例如,在图像滤波中,高频成分常常与图像的细节和噪声相关联,而低频成分则与图像的主体结构相关。通过调整这些频率成分的强度,我们可以实现图像的平滑、边缘增强等效果。
6.2 FFT在图像增强和压缩中的应用
6.2.1 图像去噪与对比度调整
图像去噪是图像处理的一个重要环节,通过FFT可以有效地对图像进行去噪处理。在频率域中,图像的噪声往往表现为高频信号,而图像的主体内容则表现为低频信号。因此,通过在频率域内设置一个阈值,去除或减弱高频部分的信号,可以有效去除噪声,而主体内容则得以保留。
对比度调整则是通过在频率域中增减特定频率成分的幅度来实现的。如果想要增加图像的对比度,可以增加中频成分的幅度,因为中频成分通常与图像的边缘和细节相关,调整它们的幅度可以显著影响图像的视觉效果。
6.2.2 图像数据压缩的FFT方法
图像压缩旨在减少存储空间需求或传输时间,同时尽可能保持图像质量。基于FFT的图像压缩方法通常采用变换编码技术。首先,通过FFT将图像从空间域转换到频率域,然后对频率域内的系数进行编码,通常采用某种量化方法减少系数的精度,以降低数据量。
为了进一步提高压缩比,可以应用心理视觉模型,只保留对人类视觉系统更为重要的频率成分,忽略掉那些不太显著的成分。这种方法既能够有效压缩数据,又能尽可能保留图像的视觉质量。
import numpy as np
from scipy.fftpack import fft2, ifft2
# 示例代码:FFT进行图像频域转换
def fft_image(image):
# 对图像应用二维FFT变换
fft_transform = fft2(image)
# 计算频率域的幅度谱
magnitude_spectrum = np.abs(fft_transform)
return magnitude_spectrum
def ifft_image(magnitude_spectrum):
# 逆变换回空间域
complex_spectrum = np.fft.ifft2(magnitude_spectrum)
# 计算逆变换后的图像
reconstructed_image = np.real(complex_spectrum)
return reconstructed_image
# 假设image是一个已经加载的灰度图像
# magnitude_spectrum = fft_image(image)
# reconstructed_image = ifft_image(magnitude_spectrum)
通过以上的函数,我们可以展示一幅图像经过FFT变换前后的对比。该代码段首先定义了 fft_image 函数来执行二维FFT变换,并获取频率域的幅度谱。接着定义了 ifft_image 函数来执行逆变换,将处理后的频域数据转换回空间域,得到重建后的图像。
在实际应用中,我们会在频域中对幅度谱进行修改,例如进行去噪或对比度调整,然后再执行逆变换。这些处理步骤需要结合图像处理的具体需求来定制。
7. FFT算法的优化策略
7.1 并行计算在FFT中的应用
并行计算技术通过使用多个处理器同时工作,可以在处理复杂计算任务时显著提高性能。对于FFT算法来说,并行化可以有效地缩短计算时间,特别是在处理大规模数据集时。
7.1.1 并行FFT的理论基础
并行FFT主要基于将FFT分解为多个可以并行处理的子问题。例如,可以将输入序列分成两部分,分别独立计算其FFT,最后合并结果。这就要求底层的FFT实现能够支持并行操作,如使用快速傅里叶变换库(FFTW)中的并行版本或利用CUDA等GPU计算平台。
7.1.2 并行FFT的实践技巧
在实践中,根据硬件的配置选择合适的并行计算工具至关重要。例如,在使用CUDA进行并行FFT时,要注意内存的分配和线程的同步。并行计算通常涉及多个维度的优化,包括但不限于:
- 数据传输:优化内存访问模式,减少CPU和GPU之间的数据传输。
- 核函数设计:设计高效的核函数以最大化线程利用率。
- 线程块和网格:合理配置线程块大小和网格尺寸以利用GPU架构。
// CUDA并行FFT实现的伪代码示例
__global__ void parallel_fft_kernel cufftDoubleComplex *data, int n) {
// 核函数内的FFT操作代码
}
// 主函数调用示例
int main() {
cufftHandle plan;
cufftPlan1d(&plan, n, CUFFT_Z2Z, batch); // 创建计划
cufftExecZ2Z(plan, data_d, data_d, CUFFT_FORWARD); // 执行并行FFT
cudaDeviceSynchronize(); // 确保执行完成
// 其他操作...
}
7.2 储存优化与预计算技术
7.2.1 减少存储需求的方法
在FFT计算中,存储需求是影响算法效率的一个重要因素。减少存储需求的方法包括:
- 原地计算:某些FFT算法变体允许使用输入数组存储输出结果,从而减少额外的内存分配。
- 数据压缩:通过丢弃对结果影响较小的数据来减少存储需求,例如在某些情况下可以采用低精度数据表示。
7.2.2 预计算策略的实现
预计算是指在计算开始前,预先完成一些可以独立于输入数据计算的步骤。例如,对于基2的FFT算法,可以预先计算出所有必要的旋转因子,将它们存储在查找表中,然后在FFT计算过程中直接使用。
# 预计算旋转因子的Python示例代码
import numpy as np
def precompute_twiddle_factors(n):
"""预先计算旋转因子"""
factors = np.array([np.exp(-2j * np.pi * k / n) for k in range(n)])
return factors
twiddle_factors = precompute_twiddle_factors(1024)
# 在FFT计算中使用twiddle_factors
7.3 FFT算法选择与组合
7.3.1 不同FFT算法的适用场景
FFT算法的选择依赖于具体的应用场景。例如,Cooley-Tukey算法适用于长度为2的幂次的序列,而混合基FFT算法则能够处理更广泛的序列长度。
7.3.2 算法组合优化案例分析
在特定情况下,组合使用不同的FFT算法可以达到优化效果。例如,可以使用混合基FFT来处理非2幂长度的数据,然后在小数据集上使用优化过的基2 FFT算法。
graph TD
A[开始优化] --> B[数据长度检查]
B --> |2幂长度| C[Cooley-Tukey FFT]
B --> |非2幂长度| D[混合基FFT]
C --> E[结束优化]
D --> E
在实践中,一个典型的优化策略是先进行数据预处理,将非2幂长度的序列补充到最近的2幂长度,然后应用Cooley-Tukey算法。这一组合方法结合了不同FFT算法的优势,既保持了高效性又拓宽了适用范围。
简介:快速傅里叶变换(FFT)是高效计算离散傅里叶变换(DFT)的方法,广泛应用于信号分析、图像处理等领域。本文将深入解析FFT算法原理,包括其基本思想、二分FFT、Cooley-Tukey算法、翻转与位移,并通过实例展示其在信号分析、图像处理、通信工程、数字信号处理和数据分析中的实际应用。同时,探讨了提高FFT计算效率的优化策略。


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









