







Partitioner
重定向Mapper输出到多个Reducer
Hadoop默认的机制是对键进行散列来确定reducer
Hadoop默认通过HashPartitioner类强制执行此策略
通过key2.hashCode()*
定义用户自己的Partitioner
实现getPartition()
返回一个介于0和reducer任务数之间的整数,指向键值
对要发送到reducer.
Combiner
— 本地reduce,在分发Mapper结果之前做一下“本地Reduce”
— hadoop通过扩展Mapreduce框架,在mapper和reducer之间增加Combiner步骤来解决上述瓶颈.
— 目的是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载
— 定义Combiner, MapReducer框架使用它的次数是:0、1…N次.
它可以先接受Mapp的数据,即对Mapp输出的数据处理,从而输出一些最为有效的数据再传给Reduce.
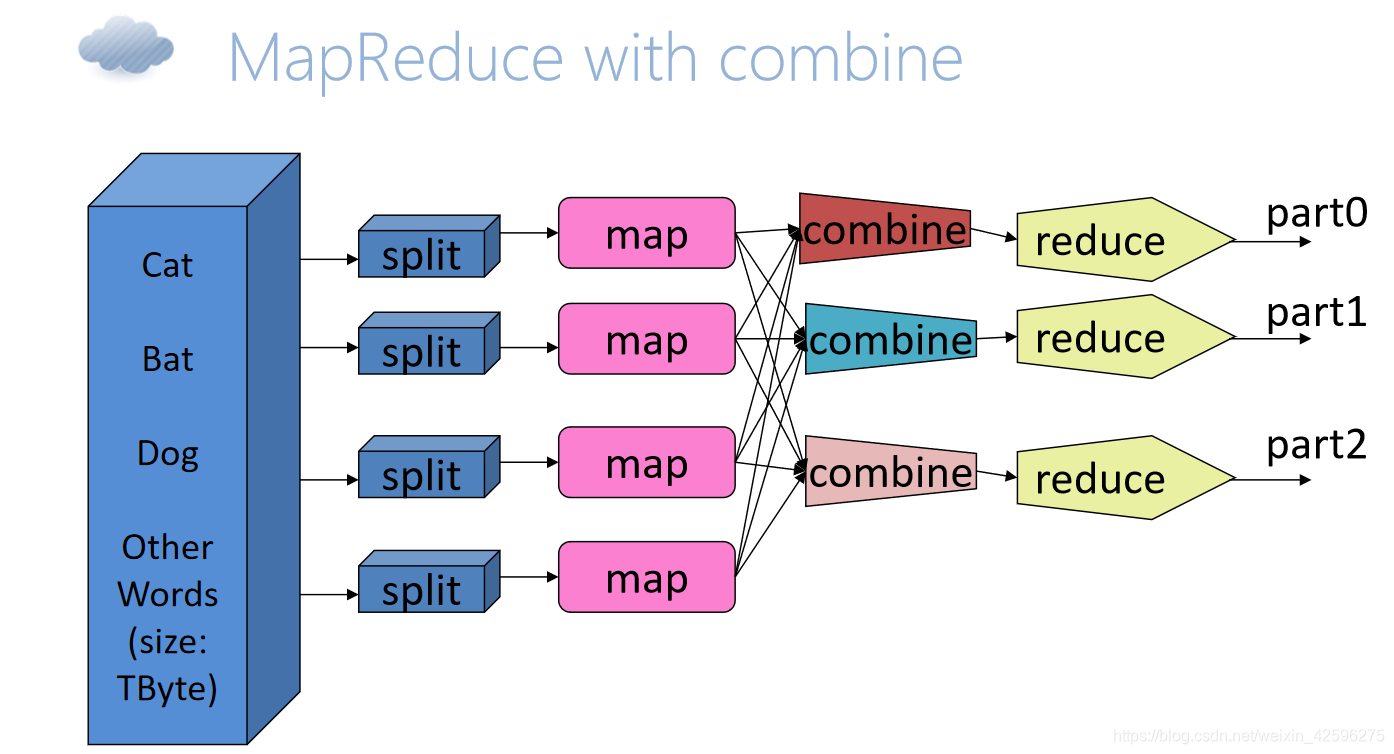
定义Combiner.
— Combiner和Reducer执行相同的操作
— Combiner需要实现Reducer接口
— 大部分计数,求最大值的操作Combiner可以直接使用Reducer
#例子:WordCountWithPartitioner#
代码:
package ex6;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountWithPartitioner {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static class LetterPartitioner
extends Partitioner<Text, IntWritable>{
@Override
public int getPartition(Text key, IntWritable value,
int numPartitions) {
int letterLocation=key.toString().toUpperCase().charAt(0)-'A' + 1;
int[] interval=new int[numPartitions];
for (int j = 0; j < interval.length; j++) interval[j]=26/numPartitions;
for (int i=0;i<26%numPartitions;i++) interval[i]++;
for(int i=0;i<numPartitions;i++) {
if (letterLocation<=interval[i])return i;
}
return 0;
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = {"testdata/input3","testdata/output3/1"};
Job job = new Job(conf, "word count");
job.setJarByClass(WordCountWithPartitioner.class);
job.setMapperClass(TokenizerMapper.class);
job.setPartitionerClass(LetterPartitioner.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
#例子:WordCountWithCombiner#
代码:
package ex6;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountWithCombiner {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static class LetterPartitioner extends Partitioner<Text, IntWritable>{
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
return (key.toString().toUpperCase().charAt(0)-'A')%numPartitions;
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = {"testdata/input3","testdata/output4/1"};
Job job = new Job(conf, "word count");
job.setJarByClass(WordCountWithCombiner.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
注意:
并不是所有的程序都可以使用Combiner,它相当于只是一个本地Reduce,只是提前做一个规约;像计数,求最值,求和等操作可以使用Combiner.并且对于Combiner来说,不需要去更改它的key2和value2的数据类型。
总结:整个mapreduce程序的性能取决与map往reduce之间所送的数据量的多少,数量越少,整个程序的性能就越好.那么怎样让数据变少,这里得到的方法是通过建立本地的reduce来减少计算量从而达到降低map往reduce输送数据量的目的,而Combiner可以做到这点.














 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









