







文章目录
4. Attention Is All You Need
文章于2017年12月发表
参见The Annotated Transformerhttp://nlp.seas.harvard.edu/2018/04/03/attention.html
考虑到RNN(或者LSTM,GRU等)的计算是顺序的,RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t 的计算依赖 t−1时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于 特别长的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题:
- 首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;
- 其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。

1. Embedding
输入为:Word Embedding + Position Embedding
1.1 Word Embedding
1.2 Position Embedding
在RNN中,对句子的处理是一个个word按顺序输入的。但在 Transformer 中,输入句子的所有word是同时处理的,没有考虑词的排序和位置信息。因此,Transformer 的作者提出了加入 “positional encoding” 的方法来解决这个问题。“positional encoding“”使得 Transformer 可以衡量 word 位置有关的信息。
Positional Encoding的公式如下:
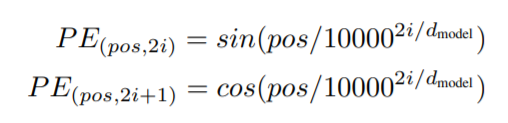
其中,pos指的是这个 word 在这个句子中的位置;2i指的是 embedding 词向量的偶数维度,2i+1指的是embedding 词向量的奇数维度。
为什么上面的两个公式能体现单词的相对位置信息呢?
某个序列中不同位置的单词,在某一维度上的位置编码数值不一样,即同一序列的不同单词在单个纬度符合某个正弦或者余弦,可认为他们的具有相对关系。
2. Encoder
Encoder部分是由N个相同的小的Encoder Layer串联而成。

2.1 Multi-Head Self-attention

2.1.1 Self-attention
本文选择的是Scaled Dot-Product Attention。
elf-attention的输入是序列词向量,此处记为x。x经过一个线性变换得到query(Q), x经过第二个线性变换得到key(K), x经过第三个线性变换得到value(V)。
也就是:
- key = linear_k(x)
- query = linear_q(x)
- value = linear_v(x)
**注意:这里的linear_k, linear_q, linear_v是相互独立、权重(WQ, WK, WV)是不同的,通过训练可得到。**得到query(Q),key(K),value(V)之后按照下面的公式计算attention(Q, K, V):
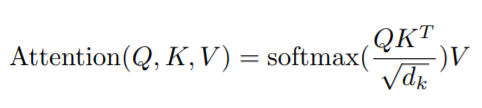
这里Z就是attention(Q, K, V)。
d
k
=
d
m
o
d
e
l
/
h
d_k=d_{model}/h
dk=dmodel/h,然后用
d
k
d_k
dk 对
Q
K
T
QK^T
QKT进行缩放,防止
Q
K
T
QK^T
QKT太大,可能会将softmax函数推入梯度极小的区域。
2.1.2 Multi-head attention
将embedding之后的X按维度 d m o d e l d_model dmodel=512 切割成h=8个,分别做self-attention之后再合并在一起。
Multi-Head Attention主要有两个作用:
- 增加了模型捕获不同位置信息的能力,如果你直接用映射前的Q, K, V计算,只能得到一个固定的权重概率分布,而这个概率分布会重点关注一个位置或个几个位置的信息,但是基于Multi-Head Attention的话,可以和更多的位置上的词关联起来。
- 因为在进行映射时不共享权值,因此映射后的子空间是不同的,认为不同的子空间涵盖的信息是不一样的,这样最后拼接的向量涵盖的信息会更广。
有实验证明,增加Mult-Head Attention的头数,是可以提高模型的长距离信息捕捉能力的。
2.2 Feed-Forward Network
Feed-Forward Network可以细分为有两层,第一层是一个线性激活函数,第二层是激活函数是ReLU。可以表示为:
FFN=max(0,xW1+b1)W2+b2
总的来说Encoder 是由上述小encoder layer 6个串行叠加组成。encoder sub layer主要包含两个部分:
- SubLayer-1 做 Multi-Headed Attention
- SubLayer-2 做 Feed Forward Neural Network
3. Decoder
Decoder也是N=6层堆叠的结构。被分为3个 SubLayer,Encoder与Decoder有三大主要的不同:
- Decoder SubLayer-1 使用的是 “Masked” Multi-Headed Attention 机制,防止为了模型看到要预测的数据,防止泄露。
- SubLayer-2 是一个 Encoder-Decoder Multi-head Attention。
- LinearLayer 和 SoftmaxLayer 作用于 SubLayer-3 的输出后面,来预测对应的 word 的 probabilities 。
3.1 Masked Multi-Headed Attention
Mask 的目的是防止 Decoder “seeing the future”,即防止看到未来的信息,这里mask是一个下三角矩阵,对角线以及对角线左下都是1,其余都是0。
优点:每层计算复杂度比RNN要低;可以进行并行计算;从计算一个序列长度为n的信息要经过的路径长度来看, CNN需要增加卷积层数来扩大视野,RNN需要从1到n逐个进行计算,而Self-attention只需要一步矩阵计算就可以。Self-Attention可以比RNN更好地解决长时依赖问题。Self-Attention模型更可解释,Attention结果的分布表明了该模型学习到了一些语法和语义信息。
缺点:实践上:有些RNN轻易可以解决的问题transformer没做到,比如推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)。
欢迎进群交流~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









