




简介:Hibernate Tools是Hibernate框架的辅助工具,提供了一键生成Entity Bean的功能,极大地简化了Java开发中的ORM操作。本文将指导开发者如何安装和使用Hibernate Tools插件,通过配置和逆向工程自动生成Entity Bean,以及如何进行注解配置和验证。学会这些技巧可以大幅提高开发效率,并促进在实际项目中对Hibernate框架的有效运用。 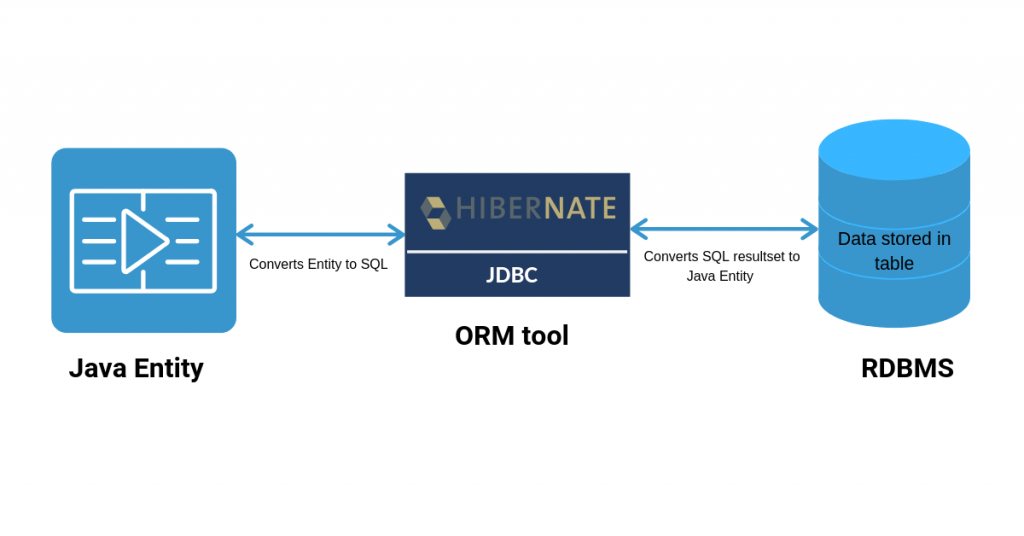
1. Hibernate框架介绍
什么是Hibernate框架
Hibernate是一个开源的对象关系映射(ORM)框架,它使得Java开发人员能够以对象的形式来操作数据库。在传统的方式下,我们通常需要通过JDBC API来处理数据库表中的数据,这种方式相对繁琐且易出错。Hibernate通过映射Java类到数据库表,并提供了面向对象的操作数据库的API,极大地简化了数据库编程的工作。
Hibernate的核心功能
Hibernate为开发者提供了以下核心功能:
- 数据持久化:可以将对象状态持久化到数据库中,并提供了一系列的API来管理对象状态。
- 查询语言:提供了一种强大且易于理解的查询语言HQL(Hibernate Query Language),使得数据查询更加方便和高效。
- 缓存:支持一级缓存和二级缓存,有效地提高了数据访问的性能。
如何开始使用Hibernate
要开始使用Hibernate,首先需要理解其基本架构和组件,然后配置好项目的依赖,最后编写相应的实体类和映射文件。本章将为您介绍Hibernate框架的基本概念和使用场景,为接下来深入学习Hibernate的高级特性和最佳实践打下坚实的基础。
2. 安装Hibernate Tools插件
2.1 选择合适的开发环境
2.1.1 IDE环境的选择标准
选择一个合适的集成开发环境(IDE)对于提高开发效率至关重要。一个理想的IDE应当具备以下几个标准:
- 插件支持 :IDE应支持Hibernate Tools插件,这样才能方便地进行ORM映射和数据库操作。
- 智能代码提示 :智能的代码提示和自动完成功能可以极大提升编码效率和准确性。
- 友好的调试工具 :集成强大的调试工具,帮助开发者快速定位和解决问题。
- 丰富的扩展库 :应提供方便的扩展库管理,以便引入第三方库和框架。
- 版本控制集成 :与版本控制系统(如Git)良好的集成,方便代码管理。
- 社区和插件生态系统 :一个活跃的开发社区和丰富的插件生态系统,可以方便地获取帮助和增加新功能。
2.1.2 Hibernate Tools插件的功能概述
Hibernate Tools是一个用于简化Hibernate开发过程的Eclipse插件。其核心功能包括:
- 逆向工程 :通过分析数据库结构自动创建实体类和映射文件。
- 代码生成 :可以生成实体类、映射文件以及Hibernate会话工厂类。
- XML和注解支持 :支持Hibernate的XML和注解配置方式。
- 集成HQL编辑器 :提供HQL(Hibernate Query Language)查询编辑器,支持语法高亮和自动完成。
- 增强的调试能力 :提供更详尽的运行时信息和调试支持。
2.2 插件安装步骤详解
2.2.1 Eclipse中的安装方法
- 打开Eclipse IDE,通过菜单栏选择
Help->Eclipse Marketplace...。 - 在搜索框中输入“Hibernate Tools”,找到对应的插件并点击“Install”按钮。
- 按照提示完成安装,并在安装结束后重启Eclipse。
2.2.2 IntelliJ IDEA中的安装方法
- 打开IntelliJ IDEA,进入
File->Settings->Plugins。 - 点击“Marketplace”标签页,搜索“Hibernate Tools”。
- 找到插件后点击“Install”并等待安装完成。
- 安装完成后重启IDEA。
2.2.3 Visual Studio Code中的安装方法
VS Code虽然不是传统的Java IDE,但通过插件也能够支持Hibernate开发:
- 打开VS Code,进入
Extensions侧边栏。 - 搜索“Hibernate”并找到Hibernate插件,点击“Install”。
- 安装后可能需要手动配置Hibernate Tools路径或额外插件来实现完整的功能。
2.3 插件版本更新与兼容性
2.3.1 查看Hibernate Tools的最新版本
- 访问Hibernate Tools的官方下载页面或者在Eclipse Marketplace中查看最新版本。
- 可以查看插件的发布日志,了解新版本的更新点。
2.3.2 处理IDE与Hibernate Tools版本不兼容的问题
- 当IDE与Hibernate Tools版本不兼容时,先尝试更新IDE到最新版本。
- 如果问题依旧,可以考虑在IDE中降级Hibernate Tools插件版本。
- 在Eclipse中,通过
Help->Eclipse Marketplace...->Installed Software标签页找到对应的Hibernate Tools插件并进行更新或卸载操作。 - 在IntelliJ IDEA中,进入
File->Settings->Plugins->Installed标签页,查找Hibernate Tools插件并处理更新或卸载问题。
通过上述的章节内容,我们已经系统地介绍了如何选择合适的IDE环境,以及在Eclipse、IntelliJ IDEA和Visual Studio Code中安装Hibernate Tools插件的方法,并且提供了处理版本兼容性问题的方案。在下一章节中,我们将深入探讨如何配置Hibernate与数据库的连接,这是任何基于Hibernate框架应用开发的基础。
3. 配置Hibernate数据库连接
在使用Hibernate进行数据库操作之前,确保数据库连接已经正确配置是关键步骤之一。本章节将详细介绍如何配置Hibernate数据库连接,包括基本的数据库连接设置、驱动和连接池的配置以及方言的配置。
3.1 数据库连接的基本配置
3.1.1 配置文件(hibernate.cfg.xml)介绍
Hibernate通过一个核心配置文件 hibernate.cfg.xml 来管理所有的数据库连接和持久化类的映射信息。该文件通常位于项目的 src 目录下,或者在资源目录(resource folder),具体路径取决于项目的构建系统。
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 其他配置属性 -->
</session-factory>
</hibernate-configuration>
在该文件中, <session-factory> 标签内包含了所有的配置属性,例如数据库连接URL、用户名、密码、驱动类等。
3.1.2 配置数据库连接参数
配置数据库连接的关键参数包括:
-
hibernate.connection.driver_class:用于指定数据库驱动类的名称。 -
hibernate.connection.url:数据库的URL地址。 -
hibernate.connection.username:数据库登录用户名。 -
hibernate.connection.password:数据库登录密码。 -
hibernate.dialect:配置数据库方言,Hibernate根据方言来生成符合数据库特性的SQL语句。 -
hibernate.connection.pool_size:配置连接池的大小,用于管理数据库连接。
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/mydatabase</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">password</property>
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="hibernate.connection.pool_size">20</property>
3.2 驱动和连接池的配置
3.2.1 数据库驱动的选择与配置
数据库驱动负责应用程序与数据库之间的通信。选择合适的驱动类对于保证性能和稳定性至关重要。通常情况下,驱动类的配置会涉及到JDBC驱动,例如对于MySQL数据库,可能会使用 com.mysql.jdbc.Driver 。
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
3.2.2 连接池的作用与配置方法
连接池管理着一组数据库连接,并根据需要分配和回收连接。Hibernate支持多种连接池实现,常用的有 org.hibernate.connection.C3P0ConnectionProvider 和 org.hibernate.connection.HikariConnectionProvider 。
通过配置连接池,可以有效提升数据库操作的性能。配置 hibernate.connection.pool_size 可以设置连接池的大小,以控制同时可用的最大连接数。
<property name="hibernate.connection.pool_size">20</property>
3.3 配置hibernate.dialect属性
3.3.1 数据库方言的作用
Hibernate方言(Dialect)是指Hibernate用来生成特定数据库的SQL语句的一组类和方法。数据库方言允许Hibernate使用数据库特有的功能,如特定的数据类型、SQL函数和查询语法等。
3.3.2 如何根据数据库选择合适的方言
选择合适的方言可以使Hibernate更好地与特定的数据库交互。例如,对于MySQL数据库,可以使用 org.hibernate.dialect.MySQLDialect 。
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
根据选用数据库的不同,方言也会有所变化。需要查阅Hibernate文档,选择正确的方言类。正确的方言配置将有助于避免SQL语法错误和性能问题。
本章节深入介绍了Hibernate数据库连接的配置方法。通过理解并正确配置 hibernate.cfg.xml 文件,开发者可以确保应用程序能够有效地连接数据库,并进行高效的数据操作。下一章节将介绍Hibernate Tools的逆向工程工具,通过逆向工程从数据库表生成Entity Bean,简化开发过程。
4. 生成Entity Bean的逆向工程步骤
4.1 逆向工程的准备工作
4.1.1 分析数据库表结构
逆向工程是根据现有的数据库表结构自动生成Java实体类(Entity Bean)的过程。这一环节的重要性在于确保生成的实体类能够准确反映数据库中的数据结构,包括表字段、数据类型、约束等。进行逆向工程之前,开发者需要对目标数据库的表结构有一个清晰的了解。这通常涉及以下活动:
- 审查现有数据库结构 :查看所有表的名称、字段及其数据类型、主键、外键和索引等。
- 理解数据关系 :识别表之间的关联关系,如一对多、多对多等,这将帮助在生成实体类时设置正确的映射关系。
- 考虑业务需求 :根据业务需求和设计模式,评估是否需要调整数据库表结构或生成的实体类。
4.1.2 创建配置文件的路径和命名规则
在进行逆向工程之前,开发者需要创建必要的配置文件,并确定其路径和命名规则。这些配置文件是逆向工程过程中的关键输入,它们指导Hibernate Tools如何连接数据库以及如何生成Java实体类。
- 配置文件的路径 :通常,配置文件放在项目的资源目录(例如,
src/main/resources)下,以确保它们在构建过程中能够被正确地包含。 - 命名规则 :命名应该具有描述性并且遵循项目约定。例如,数据库连接配置文件可能命名为
hibernate.cfg.xml,实体类生成配置文件可能命名为generator.properties。
4.2 执行逆向工程的详细步骤
4.2.1 通过图形界面进行操作
逆向工程可以通过多种方式执行,其中之一是通过图形用户界面(GUI),许多IDE(例如IntelliJ IDEA)内置了对Hibernate Tools的支持。
- 在IDE中打开GUI :以IntelliJ IDEA为例,通过“Tools”->“Generate Entity Classes”菜单选项打开逆向工程向导。
- 配置数据库连接 :选择正确的数据库驱动,并填写数据库连接信息,如URL、用户名和密码。
- 选择要生成实体的表 :在界面中选择需要逆向工程的表,并可设置排除某些表或表中的列。
- 设置生成选项 :包括实体类的包名、生成注解还是XML映射文件等。
- 执行并生成实体类 :点击“OK”或“Generate”按钮,开始执行逆向工程。
4.2.2 通过命令行进行操作
除了图形界面,逆向工程也可以通过命令行工具执行。这种方式适合自动化构建流程,或者当开发者倾向于使用文本编辑器配置文件时。
- 使用
reverse-engineer目标 :Hibernate Tools提供的Ant任务可以实现这一功能。 - 配置
build.xml文件 :定义一个Ant任务,并配置数据库连接、表选择、生成选项等参数。 - 执行Ant任务 :通过命令行运行Ant工具,传入
build.xml文件路径,执行逆向工程任务。
<project name="ReverseEngineering" default="reverse-engineer">
<target name="reverse-engineer">
<taskdef name="reverse-engineer" classname="org.hibernate.tool.ant HibernateReverseEngineeringTask">
<classpath refid="classpath"/>
</taskdef>
<reverse-engineer configurationfile="path/to/generator.properties"/>
</target>
</project>
4.3 生成Bean的自定义配置
4.3.1 排除不需要生成的表或字段
在逆向工程过程中,有时并不需要生成数据库中所有的表或字段对应的Java Bean。为了避免生成不必要或敏感的数据结构,开发者可以自定义生成规则来排除特定的表或字段。
- 配置排除规则 :在
generator.properties文件中,可以使用exclude属性指定不需要生成的表或字段。 - 规则格式 :规则格式通常为正则表达式,可针对表名或字段名进行匹配。
exclude=^(?!.*_test.*).*$ // 排除所有含有_test的表名
exclude=^(?!.*password).*$ // 排除所有含有password字段的表
4.3.2 手动编写或调整生成的Java Bean代码
虽然逆向工程能够自动创建实体类,但有时生成的代码可能不符合开发标准或性能要求,此时开发者需要手动编写或调整生成的Java Bean代码。
- 重构生成的代码 :根据实际需要,对生成的实体类进行重命名、修改属性访问级别或添加额外的方法。
- 集成自定义逻辑 :如果业务逻辑较为复杂,可能需要在实体类中集成一些自定义逻辑,如验证规则、业务方法等。
通过以上步骤,开发者可以完成Entity Bean的逆向工程生成,并根据项目需求进行必要的调整和优化。这为后续使用Entity Bean进行数据库操作打下了坚实的基础。
5. Hibernate Tools的Entity Bean命名策略和包名设置
在使用Hibernate Tools逆向工程生成Entity Bean时,正确的命名策略和包名设置对于代码的清晰度和可维护性至关重要。命名策略定义了表名到类名、列名到属性名的转换规则,而包名的配置则是为了更好地组织生成的Java代码。
5.1 命名策略的配置方法
5.1.1 默认命名策略解析
Hibernate Tools在没有明确指定命名策略的情况下,默认会采用一套内置的规则来生成Java类及其属性名称。这些默认规则通常遵循Java的命名约定,例如将表名转换为驼峰式命名的类名,列名转换为驼峰式命名的属性名。例如,数据库中的 users 表将被转换成 Users 类, user_id 列将被转换成 userId 属性。
5.1.2 自定义命名策略的实现方式
尽管默认的命名策略适用于大多数情况,但有时我们可能需要根据实际需求进行调整。Hibernate Tools允许通过配置文件来自定义命名策略,例如,通过 hibernate.ejb.naming_strategy 属性在 hibernate.cfg.xml 中指定自定义的 NamingStrategy 实现类。以下是一个简单的自定义命名策略示例:
import org.hibernate.boot.model.naming.Identifier;
import org.hibernate.boot.model.naming.PhysicalNamingStrategy;
import org.hibernate.engine.jdbc.env.spi.JdbcEnvironment;
public class CustomNamingStrategy implements PhysicalNamingStrategy {
@Override
public Identifier toPhysicalCatalogName(Identifier identifier, JdbcEnvironment context) {
return convertToIdentifier(identifier, "CATALOG");
}
@Override
public Identifier toPhysicalColumnName(Identifier identifier, JdbcEnvironment context) {
return convertToIdentifier(identifier, "COLUMN");
}
@Override
public Identifier toPhysicalSchemaName(Identifier identifier, JdbcEnvironment context) {
return convertToIdentifier(identifier, "SCHEMA");
}
@Override
public Identifier toPhysicalSequenceName(Identifier identifier, JdbcEnvironment context) {
return convertToIdentifier(identifier, "SEQUENCE");
}
@Override
public Identifier toPhysicalTableName(Identifier identifier, JdbcEnvironment context) {
return convertToIdentifier(identifier, "TABLE");
}
private Identifier convertToIdentifier(Identifier identifier, String prefix) {
String renamed = prefix + "_" + identifier.getText().toUpperCase();
return new Identifier(renamed, identifier.isQuoted());
}
}
然后在 hibernate.cfg.xml 中引用:
<property name="hibernate.ejb.naming_strategy">com.example.CustomNamingStrategy</property>
5.2 包名的配置和管理
5.2.1 包结构的合理规划
为了避免Java包名冲突,通常建议根据项目的结构和组织来规划包名。例如,可以为不同模块或业务功能创建不同的包结构。一个典型的包结构示例可能是:
-
com.example.model.user -
com.example.model.product -
com.example.model.order
在配置包名时,Hibernate Tools允许指定一个基本包名作为起点,逆向工程生成的Bean将依据此基本包名以及数据库的结构来放置在相应的子包中。例如,如果基本包名为 com.example.model ,那么 users 表的Entity Bean将会放在 com.example.model.user 包下。
5.2.2 自动化包名配置的高级技巧
要实现自动化包名配置,可以在 hibernate.cfg.xml 文件中设置如下:
<property name="hbm2ddl.auto">update</property>
<property name="hibernate.ejb.package_name_prefix">com.example.model</property>
同时,可以使用Hibernate的 AnnotationConfiguration 类来进一步细化包名的配置,例如:
Configuration configuration = new AnnotationConfiguration();
configuration.setPackage("com.example.model");
通过结合 package_name_prefix 和 AnnotationConfiguration ,可以灵活地控制生成代码的包名结构,而无需为每一个表手动指定。
通过上述配置,可以清晰地看到命名策略和包名设置的灵活性与强大功能。它们让开发者能够根据特定的项目需求和组织结构来定制Hibernate Tools的行为,最终生成结构更加合理、维护性更高的Java代码。
6. Hibernate Tools的注解配置选项
在本章节中,我们将深入探讨Hibernate Tools中的注解配置选项,这包括注解与XML配置的对比、如何在Hibernate Tools中启用注解、以及注解的类型和使用限制。
6.1 注解与XML配置的对比
6.1.1 注解的优势和使用场景
注解是一种强大且日益流行的方式来替代XML配置文件,因为它使得Java代码更加整洁和直观。注解通过在实体类和映射关系中直接添加元数据信息,使得开发人员可以省去编写繁琐的XML文件,从而提升开发效率和减少错误配置的可能性。
在某些情况下,注解是更好的选择:
- 简易映射 :对于简单的数据模型,使用注解可以快速定义实体类和映射关系,而无需额外的XML文件。
- 代码可读性 :注解直接标注在实体类上,代码的阅读者可以直观地理解数据的映射关系,无需切换到XML文件。
- 类型安全 :使用注解,编译时就能检测到许多配置错误,提高了代码的健壮性。
然而,XML配置在某些场景下仍然有其用武之地:
- 复用配置 :XML文件中的配置可以被多个类共享,这在使用注解时难以实现。
- 动态生成 :在某些特定情况下,配置可能需要动态生成,此时XML配置更加灵活。
6.1.2 注解与XML配置的兼容性分析
在Hibernate中,注解和XML配置是可以共存的。开发者可以根据需要选择使用注解或者XML,或者将两者结合使用。例如,可以在Java类中使用注解进行大部分配置,而对于特定的映射需求使用XML进行更细致的控制。
在Hibernate Tools中,开发者可以配置注解生成器,决定是否生成注解,以及是否保留XML配置文件。为了兼容性考虑,Hibernate Tools提供了灵活的选项,允许开发者在不同的项目或模块中选择不同的配置策略。
6.2 如何在Hibernate Tools中配置注解
6.2.1 启用注解生成的相关选项
在Hibernate Tools中,可以通过图形用户界面(GUI)或命令行工具启用注解生成选项。在GUI中,通常会有一个专门的配置部分,允许开发者勾选“Generate Annotations”或“Use Annotations”这样的复选框。
如果是通过命令行进行操作,可以通过添加特定的参数来启用注解。例如,在使用Hibernate Tools的 reverseEngineering 插件时,可以添加如下参数:
<property name="generateAnnotation" value="true"/>
6.2.2 注解的类型和使用限制
在启用注解生成后,开发者需要了解不同类型的注解及其用途。以下是一些基本的注解类型和它们的使用限制:
-
@Entity:标注在实体类上,表示该类是一个JPA实体。 -
@Table:用来指定实体对应的数据库表名。 -
@Id:用于标注实体的主键字段。 -
@GeneratedValue:指定主键的生成策略。 -
@Column:用于指定字段对应的列名及其它属性,如数据类型、是否可为空等。 -
@OneToOne,@OneToMany,@ManyToOne,@ManyToMany:用于表示实体间的关系。
需要注意的是,在使用注解时,必须确保所使用的Java版本和JPA实现兼容。例如,某些注解可能在较早的Java版本中不可用或有所不同。
通过以上配置和了解,开发者可以更高效地利用Hibernate Tools进行注解配置,提高开发效率,降低维护成本。在后续章节中,我们将进一步探讨生成的Entity Bean的验证和调试过程。
7. 生成Entity Bean的验证和调试
生成Entity Bean后,需要经过一系列验证和调试步骤,以确保这些Bean能够正确地与数据库交互。验证确保了代码的正确性和完整性,而调试则帮助我们发现和解决问题。
7.1 验证生成的Entity Bean
7.1.1 通过编译检查
为了验证生成的Entity Bean是否符合Java语言的规范,最直接的方法是通过编译器检查。通常IDE会自动编译代码,我们可以观察是否出现了编译错误。如果存在错误,需要检查生成的Java代码和配置文件是否有误。确认无误后,才能进行下一步的操作。
// 示例代码:简单的编译检查
public class User {
private Long id;
private String name;
// getters and setters
}
7.1.2 通过单元测试检查
单元测试是代码质量的重要保障。我们可以编写单元测试来验证Entity Bean的各个属性是否符合预期。例如,测试属性的getter和setter方法,确保它们能够正确地设置和返回值。
// 示例代码:单元测试Entity Bean
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class UserTest {
@Test
public void testUserBean() {
User user = new User();
user.setId(1L);
user.setName("John Doe");
assertEquals(Long.valueOf(1), user.getId());
assertEquals("John Doe", user.getName());
}
}
7.2 调试生成的代码
7.2.1 设置断点和查看运行时信息
当代码通过编译并初步验证后,使用调试工具进行运行时调试是必不可少的。在IDE中设置断点,可以暂停程序的执行,查看运行时的变量状态和程序流程。
// 示例代码:设置断点进行调试
public User getUserById(Long id) {
// 断点可以设置在此行
Session session = sessionFactory.openSession();
User user = (User) session.get(User.class, id);
session.close();
return user;
}
7.2.2 性能调优和潜在问题的诊断
调试过程中,我们还需要关注Entity Bean的性能表现和潜在的性能瓶颈。使用性能分析工具对代码进行分析,观察内存使用情况、数据库操作次数等关键指标。这样可以发现哪些地方可能导致性能下降,并进行针对性的优化。
graph LR
A[开始性能分析] --> B[收集运行时数据]
B --> C[分析数据库操作次数]
C --> D[检查内存使用情况]
D --> E[识别性能瓶颈]
E --> F[进行性能优化]
调试和验证是确保生成的Entity Bean能够可靠运行的关键步骤。通过编译和单元测试可以快速发现问题,而运行时调试和性能分析则更深入地揭示代码在实际使用中的表现。这些步骤对于提升代码质量、减少潜在错误具有重要作用。
简介:Hibernate Tools是Hibernate框架的辅助工具,提供了一键生成Entity Bean的功能,极大地简化了Java开发中的ORM操作。本文将指导开发者如何安装和使用Hibernate Tools插件,通过配置和逆向工程自动生成Entity Bean,以及如何进行注解配置和验证。学会这些技巧可以大幅提高开发效率,并促进在实际项目中对Hibernate框架的有效运用。


















 8500
8500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









