







1.首先,我这里用的是idea,git
右键项目名称,然后点击show in Explorer(跳转到你本地存储代码的文件目录)
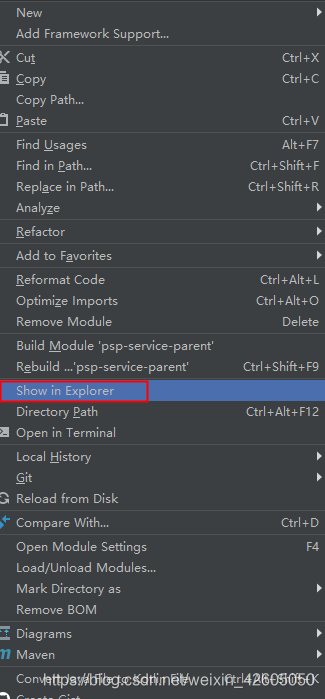
2.然后双击打开本地储存项目的储存文件,然后右键,
然后点击Git Bash Here(安装过git的才有),进入git命令后,输入以下命令:git log --format='%aN' | sort -u | while read name; do echo -en "$name\t"; git log --author="$name" --pretty=tformat: --numstat | grep "\(.java\)$" | awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }' -; done
按enter即可显示当前项目中,你和你团队中的其他同事,每个人所开发的代码行数以及删除的代码行数。















06-16
 869
869
869
10-31
5706
5706
08-20
633
633
02-24
1万+
1万+
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









