







概要
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多生产者、多订阅者,基于
zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访
问性能。 - 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。同时支持离线数据处理和实时数据处理。
本文主要是介绍kafka整体框架上的一些基本概念
整体架构
消息传递模式只要有两种:点对点传递模式、发布-订阅模式。
大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。
对于消息中间件,消息分推拉两种模式。Kafka只有消息的拉取,没有推送,消费者端通过轮询从broker端获取数据
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
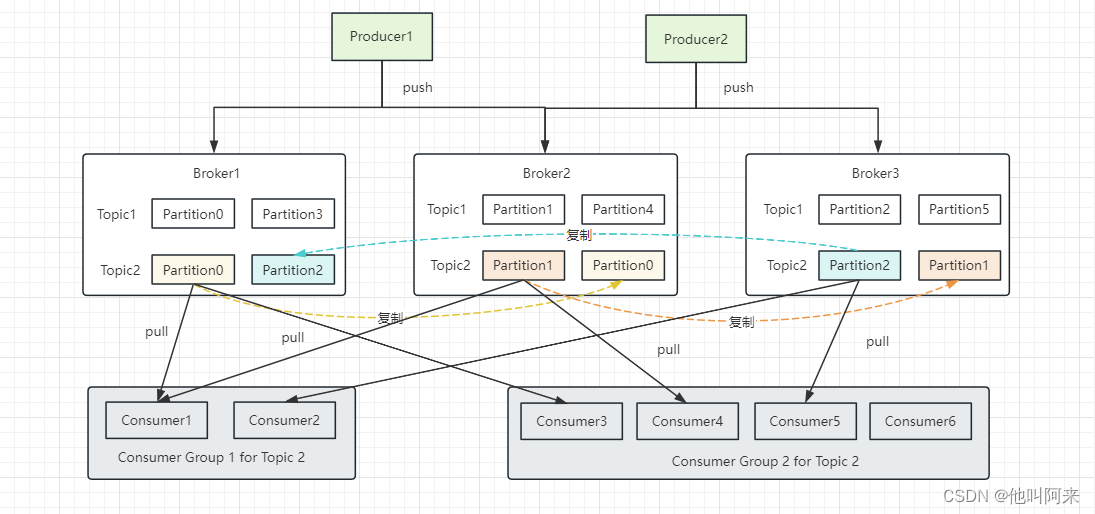
Broker
- 一个独立的Kafka服务器称为broker。一个或者多个broker可以组成kafka集群
- broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
- broker为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘上的消息。
Topic
- Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
- 主题可比是数据库的表或者文件系统里的文件夹。
- 主题可以被分为若干分区,一个主题通过分区分布于Kafka集群中,提供了横向扩展的能力
Partition
- 主题可以被分为若干个分区,一个分区就是一个提交日志。
- 消息以追加的方式写入分区,然后以先入先出的顺序读取。
- Kafka 通过分区来实现数据冗余和伸缩性。
Replicas
- Kafka 使用主题来组织数据,每个主题被分为若干个分区,每个分区有多个副本。
- 副本被保存在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。
- 副本有以下两种类型:
首领副本:每个分区都有一个首领副本。为了保证一致性,所有生产者请求和消费者请求都会经过这个副本。
跟随者副本:首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,它们唯一的任务就是从首领那里复制消息,保持与首领一致的状态。如果首领发生崩溃,其中的一个跟随者会被提升为新首领。
Producer
消息生产者,向Broker发送消息的客户端
Consumer
消息消费者,从Broker读取消息的客户端
Consumer Group
每个Consumer属于一个特定的ConsumerGroup,一条消息可以被多个不同的
Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费同一条消息
broker和集群
一个独立的Kafka服务器称为broker
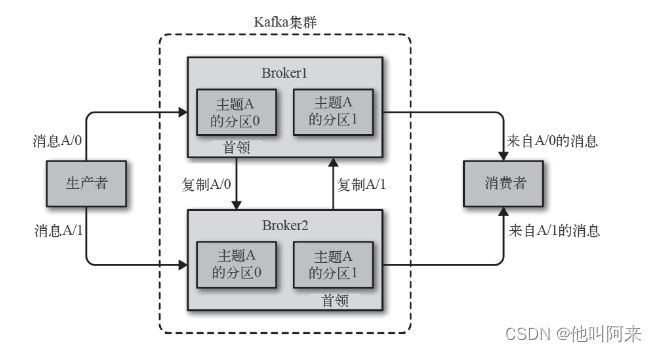
每个集群都有一个broker是集群控制器(从集群的活跃成员中选举出来)
控制器负责管理工作:
- 将分区分配给broker
- 监控broker
- 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
- 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
Producer
- producer采用push模式将消息发布到broker,每条消息都被append到patition中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
- producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
- 指定了 patition,则直接使用;
- 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition
- patition 和 key 都未指定,使用轮询选出一个 patition。
- 默认使用轮询的方式
Consumer和消费者组
从broker端读取消息的客户端,称为消费者;具有相同group.id的消费者,属于同一个消费组。一般来说,项目中用到的消费者都是以消费者组的形式存在的;一个消费者组含义一个或者多个消费者,抽象出组的概念对已broker端来说大有益处,broker端不需要关心有多少个消费者,始终以群组为单位来记录消费的位移信息。
分区与消费者之间的关系大致存在以下图中几种:
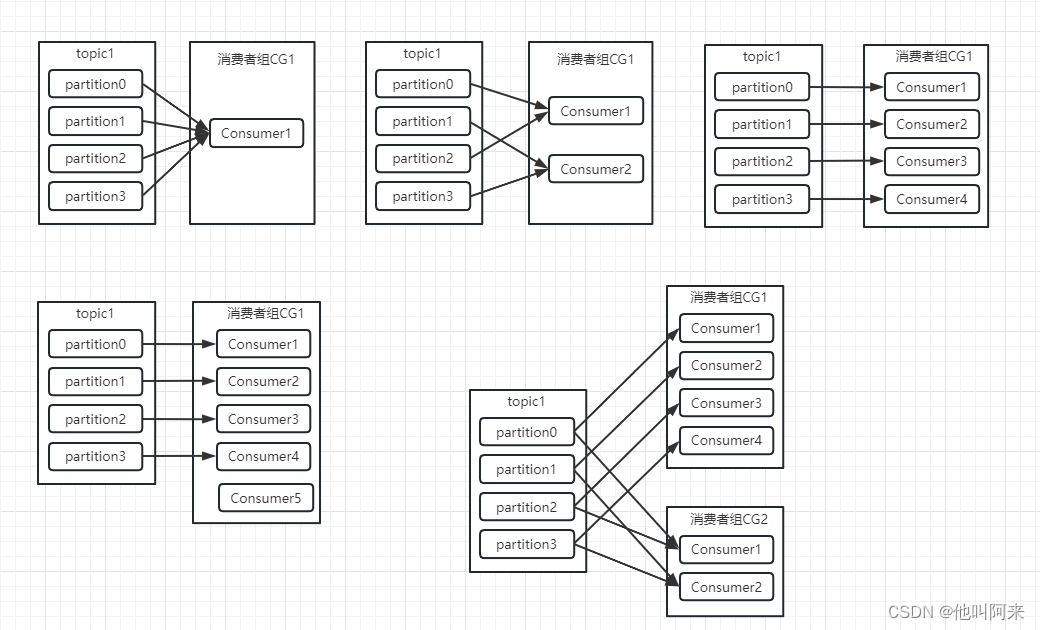
这里需要注意:
- 消费组均衡地给消费者分配分区,每个分区只由消费组中一个消费者消费
- 如果消费者比分区多,就会出现闲置的现象
- 组与组之间的消费互不影响
小结
本文主要从大方面总结了kafka各个主要概念;消费者如何消费,生产者发送消息流程是怎么样,位移是如何管理的,这些细节内容会在后面的文章中进行补充。















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









