






运行平台:windows
Python版本:Python 3.7.0
用到的第三方库:requests ,Beautiful Soup,re
IDE:jupyter notebook
浏览器:Chrome浏览器
思路:
1.查看网页源代码
2.抓取单页内容
3.Beautiful Soup解析网页内容并提取有用信息
4.把全站有用信息写入文件
1.查看网页原代码
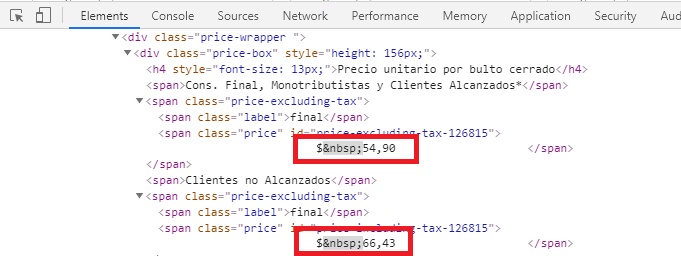
按F12查看网页源代码发现每一个商品的信息都在“
”标签之中。
点开之后信息如下
二.抓取单页内容并写入记事本
接下来通过以下代码获取网页内所需数据并写入记事本
1 #!usr/bin/env python3
2 #-*- coding:utf-8 -*-
3 from bs4 import BeautifulSoup #网页解析库
4 import requests #网页请求库
5 import re #正则表达式
6 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'}#添加请求头防止反爬
7 response = requests.get('http://www.maxiconsumo.com/sucursal_capital/comestibles/aceites/aceite-girasol.html',headers = headers) #使用网页请求库打开网页
8 soup = BeautifulSoup(response.text,"lxml") #使用BeautifulSoup解析网页
9 lis = soup.find('ul',class_='products-grid unstyled thubmnails products').find_all('li') #在解析的网页检测class元素为products-grid...下的li标签
10 msg = '{}\n商品名称:{}\n含税价格:{}\n免税价格:{}\n' #创建写入记事本内容
11 goods_list = [] #创建空列表
12 for li in lis: #遍历所有li标签内的内容
13 codigo = li.find('span',class_='sku').text.strip() #在遍历的内容内查找span标签下的sku的codigo进行去除头尾空格得到codigo
14 title = li.find('h2',class_='product-name').text.strip()#在遍历的内容内查找h2标签下的roduct-name进行去除头尾空格得到商品名称
15 price_so = li.find_all('span',class_='price')[:2] #在遍历的内容内查找span标签下的price进行切片保留头两个价格
16 price1,price2 = [p.text.strip() for p in price_so] #通过for循环和去出头尾空格分别获得免税价格和含税价格
17 info = msg.format(codigo,title,price1,price2) #内容添加进记事本内
18 goods_list.append(info) #信息加入空列表内
19 print(codigo,title,price1,price2) #输出到控制台
20 with open('maxiconsumo.txt','a',encoding = 'utf-8') as file: #创建一个叫maxiconsumo.txt的文件
21 file.write('\n',join(goods_list)) #把列表内容写入文件
现在单页内容已经获取完毕
三.抓取全站价格
通过对网页的分析可以发现官网对所有的商品进行分类并且可以通过首页进入任何商品网页
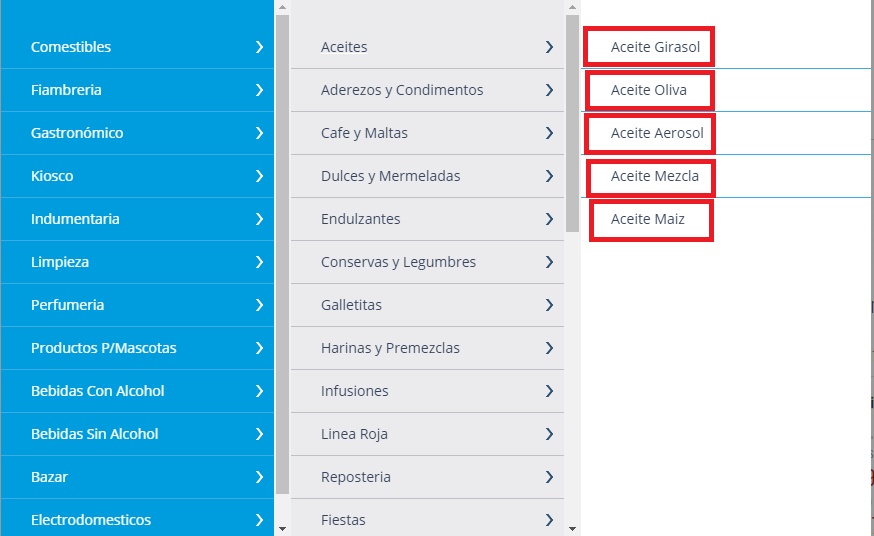
那么我只要抓取首页内商品分类的超链接就可以进入所有网页并收集信息代码如下
1 from bs4 import BeautifulSoup #网页解析库
2 import requests #网页请求库
3 importre4 res = requests.get('http://www.maxiconsumo.com',headers = headers) #打开首页
5 sou = BeautifulSoup(res.text,"lxml")#解析网页
6 pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') #创建收集链接的正则
7 index_lis = str(sou.find_all(class_="subcat")) #查找解析网页内subcat保存超链接的元素
8 product_url = re.findall(pattern,index_lis) #使用正则匹配获取subcat内超链接清洗获得超链接
9 for url in product_url: #for循环出来超链接
10 print(url) #控制台输出
通过代码输出得到以下内容

有了所有内容的网页链接后就可以开始封装了源代码如下
1 #!usr/bin/env python3
2 #-*- coding:utf-8 -*-
3 from bs4 import BeautifulSoup #网页解析库
4 import requests #网页请求库
5 import re #正则表达式
6 defget_one_page(url,headers):7 response = requests.get(url,headers = headers) #使用网页请求库打开网页
8 soup = BeautifulSoup(response.text,"lxml") #使用BeautifulSoup解析网页
9 try:10 lis = soup.find('ul',class_='products-grid unstyled thubmnails products').find_all('li') #在解析的网页检测class元素为products-grid...下的li标签
11 msg = '{}\n商品名称:{}\n含税价格:{}\n免税价格:{}\n' #创建写入记事本内容
12 goods_list = [] #创建空列表
13 for li in lis: #遍历所有li标签内的内容
14 codigo = li.find('span',class_='sku').text.strip() #在遍历的内容内查找span标签下的sku的codigo进行去除头尾空格得到codigo
15 title = li.find('h2',class_='product-name').text.strip()#在遍历的内容内查找h2标签下的roduct-name进行去除头尾空格得到商品名称
16 price_so = li.find_all('span',class_='price')[:2] #在遍历的内容内查找span标签下的price进行切片保留头两个价格
17 price1,price2 = [p.text.strip() for p in price_so] #通过for循环和去出头尾空格分别获得免税价格和含税价格
18 info = msg.format(codigo,title,price1,price2) #内容添加进记事本内
19 goods_list.append(info) #信息加入空列表内
20 print(codigo,title,price1,price2) #输出控制台
21 with open('maxiconsumo.txt','a',encoding = 'utf-8') as file: #创建一个叫maxiconsumo.txt的文件
22 file.write('\n',join(goods_list)) #把列表内容写入文件
23 except:24 pass
25
26 defget_one_page_url(index,headers):27 res = requests.get(index,headers = headers) #打开首页
28 sou = BeautifulSoup(res.text,"lxml")#解析网页
29 pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') #创建收集链接的正则
30 index_lis = str(sou.find_all(class_="subcat")) #查找解析网页内subcat保存超链接的元素
31 product_url = re.findall(pattern,index_lis) #使用正则匹配获取subcat内超链接清洗获得超链接
32 return product_url #返回链接
33
34 defmain():35 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'}#添加请求头防止反爬
36 index = 'http://www.maxiconsumo.com' #定义首页链接
37 page_url = get_one_page_url(index,headers) #传入参数
38 for i in page_url: #for 循环链接
39 url =i40 get_one_page(url,headers) #得到的链接传入需要爬的函数内
41
42 if __name__ == '__main__':43 main()
虽然代码不太严谨 但是基本功能都实现了
这里我就不把多进程的方式写出来 按目前代码大概爬取全网的数据也就十几分钟
不放多进程的原因就是不想给对方服务器造成过大的压力 ps:多进程任务相当于cc攻击
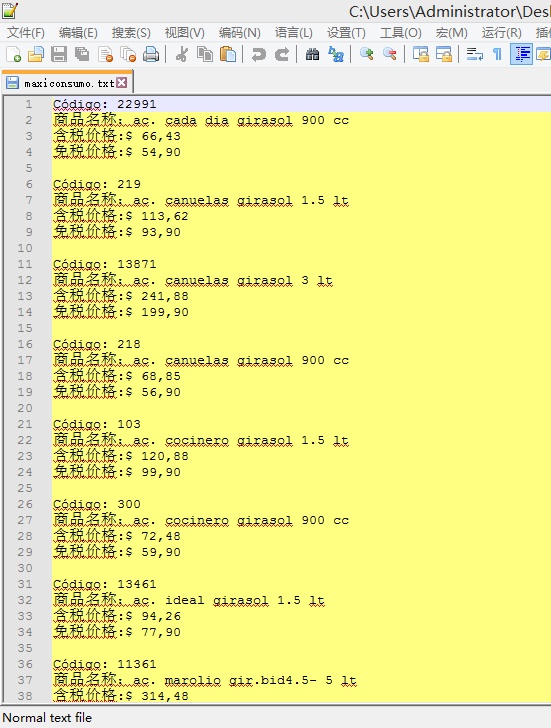
最后附上爬到大概内容图片















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









