






容器使用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TnjjEgRA-1627493724132)(http://note.youdao.com/yws/res/6965/WEBRESOURCE8fe819d5312dac53f836fd62466aa885)]](https://img-blog.csdnimg.cn/61a5bb582ca84b34ba1cc740419c55cc.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
collection:一个元素一个元素放入
Map:一对一对放入,entry对象
· Hashtable —> Concurrenthashmap
自带锁,老版本,基本不用
Vector/Hashtable(方法自带锁) ---> Hashmap ---> SynchionizedHashmap ---> Concurrenthashmap
Concurrenthashmap读取效率非常快
· Vector —> Queue
面试题:Queue和list的区别
1.Queue添加了许多对线程友好的API,offer,peek,poll;
2.BlockingQueue,又添加了两个put,take,实现阻塞,生产者消费者模型;
- Vector
1.线程安全的容器,自带锁的,但是size()和remove()之间是没加锁的,也会超卖;
2.解决方法:在两个原子操作之外,在加一个锁,包含两个原子操作,但是效率不高;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k3Ymsguh-1627493724134)(http://note.youdao.com/yws/res/7010/WEBRESOURCE646847ee468248bce67da2551a52faec)]](https://img-blog.csdnimg.cn/859f8e9b086b4c2da4dfc48e6fab3b5f.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
- ArrayList
线程不安全,会超卖
- Queue
1.多线程容器多考虑Queue;
2.元素可重复考虑Queue,元素不可重复可以考虑set中的concurrent类的集合;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GWf9XCO6-1627493724135)(http://note.youdao.com/yws/res/7022/WEBRESOURCEb555b91d4f04b0cf90211384e1088694)]](https://img-blog.csdnimg.cn/d7c7342b0d854dc9a86a9537483262eb.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
Queue.poll()源码:
1.从头部removes一个元素;
2.如果为空值,则返回null;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-co9BHS9a-1627493724136)(http://note.youdao.com/yws/res/7024/WEBRESOURCEe840c59154a12c816012a1cb526844a7)]](https://img-blog.csdnimg.cn/634cde6af8e44d2f99fefb9c4b8bed1f.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
3.实现是CAS代替无锁化,提高效率;
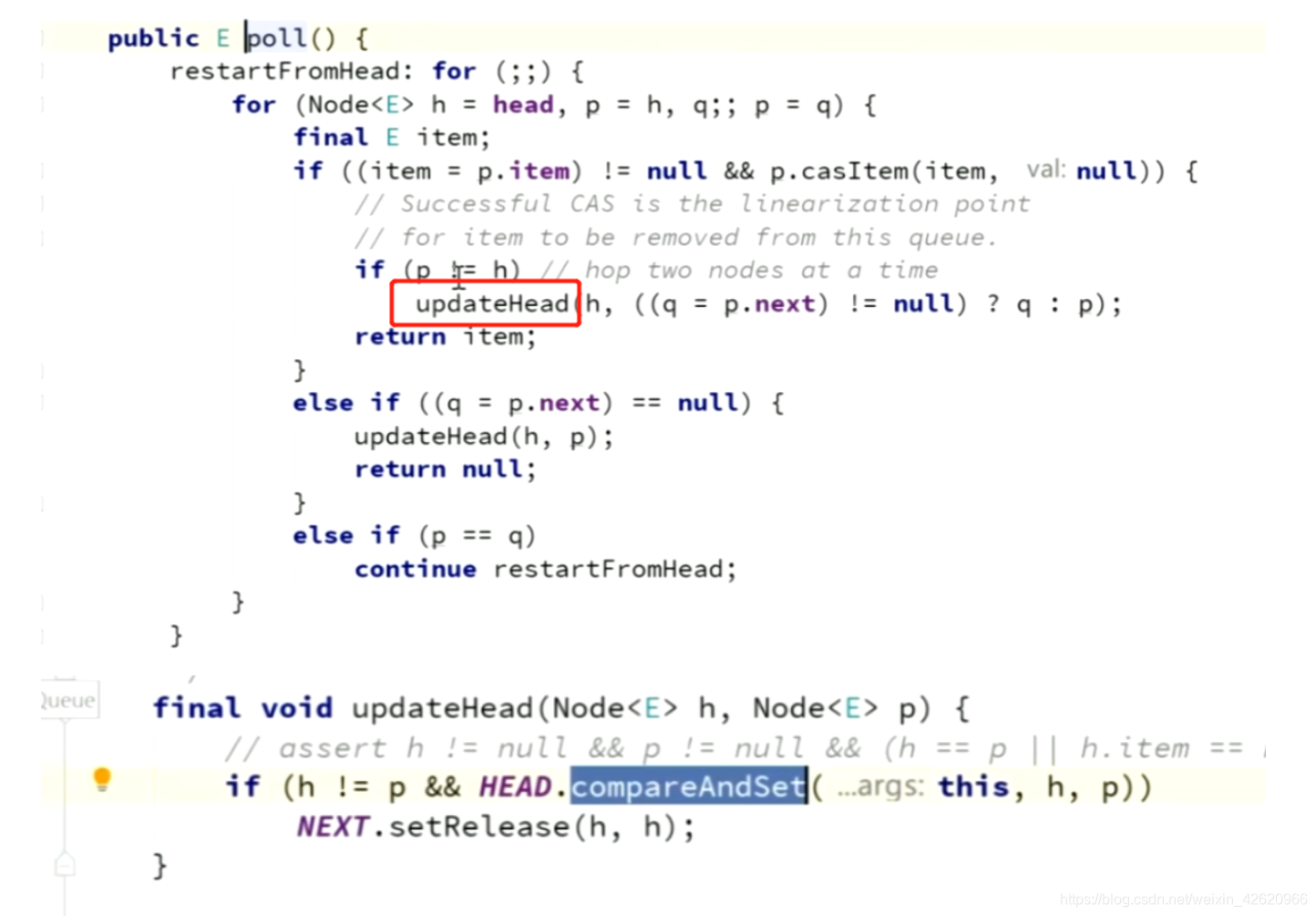
Q:CAS一定比Synchronized快吗?
A:
1.根据多线程数,单线程就可以用Hashmap,多线程就得用concurrentHashMap 和 concurrentQueue
2.线程执行不是特别长,可以用synchronized;
多线程常用的容器
- concurrentHashMap 、treeMap、concurrentSkipListMap
TreeMap:使用的是红黑树,排序的;
因为concurrentHashMap里面用的是CAS操作,CAS用在tree的树上实现太复杂,
但是又需要一个排好序的,所以就有了concurrentSkipListMap(跳表概念);
跳表实现原理:
1.底层是一个链表,
2.拿出链表的一些关键元素在上方在做一个链表,
3.如果数据量大,就在做一层,
4.从上往下查找,就快了很多;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SqJd1qID-1627493724138)(http://note.youdao.com/yws/res/7074/WEBRESOURCE14df068d25a5947abaa8801a6c62d317)]](https://img-blog.csdnimg.cn/474c0c3cdcb64cc3a3170b62c4bc02e5.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
- CopyOnWritedList 、CopyOnWritedSet
CopyOnWrited写时复制,
写的线程少,写的时候需要赋值一个新的容器,所以写的效率特别低;
读的线程特别多,没有锁,所以效率特别高;
常用于写少读多的场景;
CopyOnWrited 源码解析:
-
写:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0TvwJfWX-1627493724138)(http://note.youdao.com/yws/res/7090/WEBRESOURCE066932b07d3f089475d36d80ee88c186)]](https://img-blog.csdnimg.cn/98af40a5e6b1478fb6b2fdc78e5c5bb4.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
-
读(因为复制了,不需要加锁)
· BlockingQueue 阻塞队列
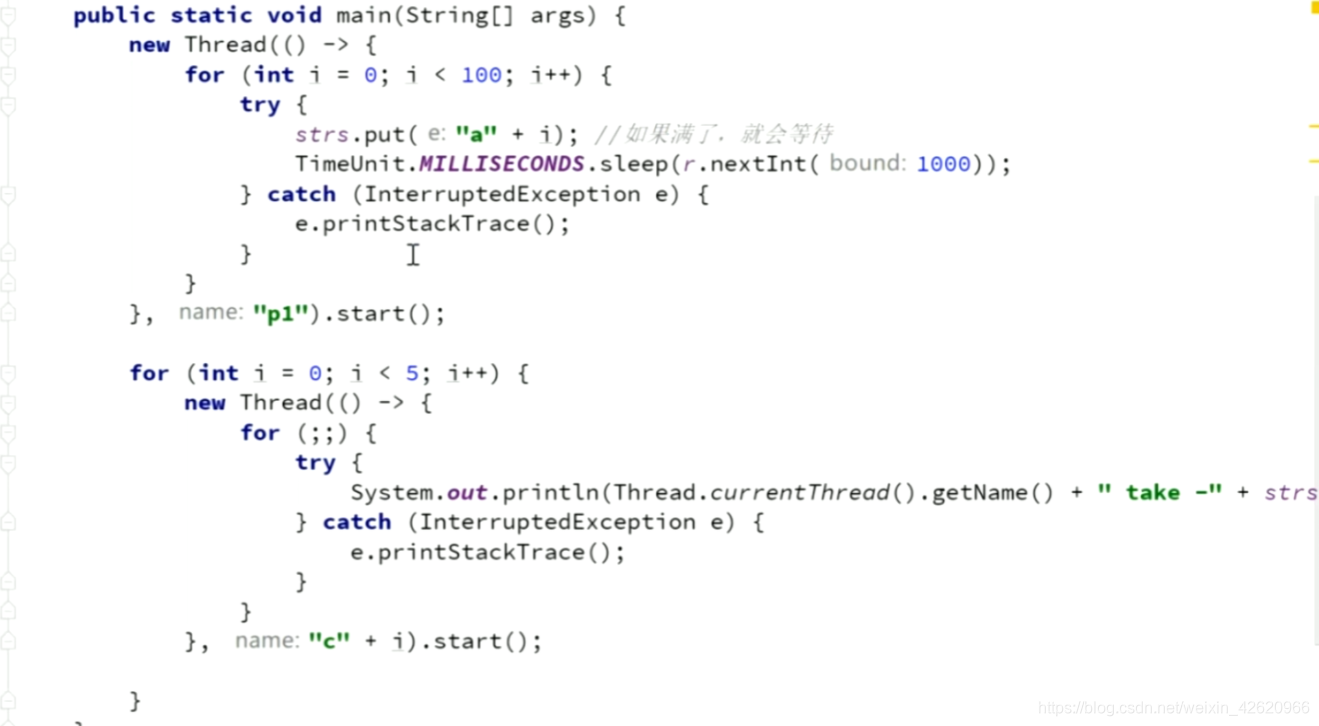
- LinkedBlockingQueue (无界的)
put();一直装,满了会阻塞;
take();一直取,空了会阻塞;
天生的生产者消费者模式;
- ArrayBlockQueue (有界的)
put();满了就会等待,程序阻塞;
add();满了就会抛异常,Queue full;
offer();满了就会等待,程序阻塞,但是有返回值boller;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M6GHac3H-1627493724139)(http://note.youdao.com/yws/res/7114/WEBRESOURCE17d6bf164a321094e9f7563e43b3d99a)]](https://img-blog.csdnimg.cn/d7f5b61c05ef46ffac3663d41a7d76d4.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
- DelayQueue
按照在队列等待的时间排序,越短越先执行;
场景:按时间进行任务调度;
- PriorityQueue
实现了排序;
内部是二叉树,小顶堆模式,小的在上和左;
- SynchronousQueue(容量为0)
功能:
1.不是为了装内容的,是线程之间的通讯的,和之前HUC的exchanger类似;
方法:
2.take:线程阻塞;
put:另外一条线程往进赋值;
两个线程直接交换位置;
前提必须有take阻塞,否则因为容量为0,就会异常:Queue full;
场景:
任务之间的调度;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gngMMgfL-1627493724140)(http://note.youdao.com/yws/res/7158/WEBRESOURCE6e937e2c03efd93d300c8805f9ec0942)]](https://img-blog.csdnimg.cn/3a8a8115a496499f81e53c6c8b897cf2.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjYyMDk2Ng==,size_16,color_FFFFFF,t_70)
- TransferQueue
方法:
transfer:添加,然后阻塞,等待其他线程取走,在开始执行自己的;
场景:
等待一个结果返回之后,在继续执行;














 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









