







注册中心Eureka
原理说明
-
Eureka是Netflix开源的用于微服务间注册发现的注册中心,用于实现服务的自动注册与发现,去中心化服务调用。ap模型
-
包含Eureka-server/client两部分,c/s架构。微服务通过eureka-client,与server保持心跳,client可以获取到server端的服务列表,server端可以监控client的是否正常
-
eureka采用定时任务和服务通信,是短连接;nacos使用netty与服务保持长连接
-
服务注册、服务续约、获取注册列表、服务下线、服务剔除过程:
- client启动时,会向server进行注册,server服务注册表会存储所有可用服务节点的信息(微服务的元信息,如ip、端口、运行状况url、主页等)。client具备一个内置的、使用轮询算法(round-robin)的负载均衡器,如果一个server注册失败,则会重试其他server。(defaultZone)
- client每隔一定时间(默认30s),会向server端发送一次心跳来续约。通过续约告知server端客户端正常运行,如果server在90s内没有收到client的续约请求,server会将客户端移除服务注册表。如果server开启的自我保护模式,短时间内有大量服务下线,则认为可能自身发生了网络分区,这是不再下线服务,但可以注册服务,恢复后会忒出自我保护模式,让eureka集群更健壮
- client获取server端的注册列表信息,缓存到本地,服务调用时,从本地缓存获取服务的调用信息。client定时(默认30s)从server同步最新的服务注册列表。默认情况下客户端通过压缩json格式获取注册列表信息
- client可以调用方法主动下线自己,server端将把client从服务注册列表中删除。一般微服务在程序停止时,向server发请求下线服务。服务下线不会自动完成,需要显示调用:DiscoveryManager.getInstance().shutdownComponent();
- 默认情况下,client在90s内没有向server端发送心跳,server会从服务注册表删除该服务,即服务剔除。默认情况下,client 30s与server发送一次心跳,90s没有收到心跳,则把client从服务注册表剔除,再有60s的清除间隔,把client下线,还不考虑客户端的缓存,约30+90+60约最长三分钟才能下线服务;nacos支持client心跳的方式上报server的状态,心跳默认5s,nacos会在超过15s将server置为不健康状态,可收到请求,30s将实例删除,不会收到请求。
-
eureka自我保护模式:
默认情况下,90s没有收到client心跳,server将下线服务。当server发生网络分区时,client 与server无法正常通信,但微服务本身是正常的,这时不应该注销服务。因此就有的自我保护模式,当短时间内丢失过多客户端,就会进入。该模式下server不会下线任何服务,网络恢复后(大部分客户端能有正常心跳),退出该模式 -
eureka集群:
- eureka server也是client,多个server间通过p2p复制的方式完成数据同步
- 集群版的eureka server通过defaultZone配置不包含本节点的其他server的url地址,多个以逗号分隔。并调整hostname,默认以hostname方式注册(可以调整为以ip方式注册)。client的defaultZone配置所有server端的地址,逗号分隔。采用轮询的方式访问,一个server访问失败,重试另一个。
- eureka间进行信息同步时,被同步信息不会同步回来。比如server1向server2同步后,server2同步该信息时,不会再向server1同步。消息同步时定时批量同步的。client注册服务只会选择一个server节点,server节点间通过数据批量同步,性能更高
-
eureka与zookeeper对比:
| 维度 | eureka | zookeeper |
|---|---|---|
| cap | ap | cp |
| 可用性 | 集群中有可用的节点就可以对外提供服务,但有可能提供的是过期的数据,需要客户端做容错处理,如重试、熔断降级等 | 可以保证任意时刻都能获取到一致的数据,但是不保证每次都能提供服务 |
| 算法 | 任意一个节点都可以提供读写服务,节点间数据批量定时同步 | zab算法(paxos),保证数据一致性,选主、leader-flower、投票 |
| 故障恢复 | 客户端自动切换到其他server节点,整个集群可用;server恢复后,加入到集群只需要从其他节点同步部分数据即可 | 恢复要通过投票选主,需要30s-120s |
常用配置
参考文章
包含client、instance、server三部分配置,下面是常用的配置项
- client:
# 客户端是否启用,默认true
enabled
# 更新实例信息的变化到Eureka服务端的间隔时间(s),默认30s
instance-info-replication-interval-seconds
# 与server服务的url列表,如果是client则为所有server列表,逗号分隔;如果是集群server,则是包含自己的其他server列表
serviceUrl.defaultZone
# 此实例是否注册到server以供其他服务发现,默认true
register-with-eureka
# 此实例是否从server获取注册信息,默认true
fetch-registry
- instance
# 注册到注册中心的应用名称,默认为unkown
appname
# 该服务实例向注册中心发送心跳间隔(s),默认30s
lease-renewal-interval-in-seconds
# 指示eureka服务器在删除此实例之前收到最后一次心跳之后等待的时间(s),默认90s
lease-expiration-duration-in-seconds
# 该服务实例在注册中心的唯一实例ID
instance-id
# 该服务实例所在主机名
hostname
# 是否优先使用服务实例的IP地址,相较于hostname,默认false;如果通过hostname不能访问(ping),则设置为true
prefer-ip-address
- server
# 启用自我保护机制,默认true
enable-self-preservation
# 清除无效服务实例的时间间隔(ms),默认60 000
eviction-interval-timer-in-ms
nacos
原理
nacos是阿里开源的,包含注册中心、配置中心的功能,动态DNS服务(权重路由、负载均衡、流量控制等)
- 整体架构
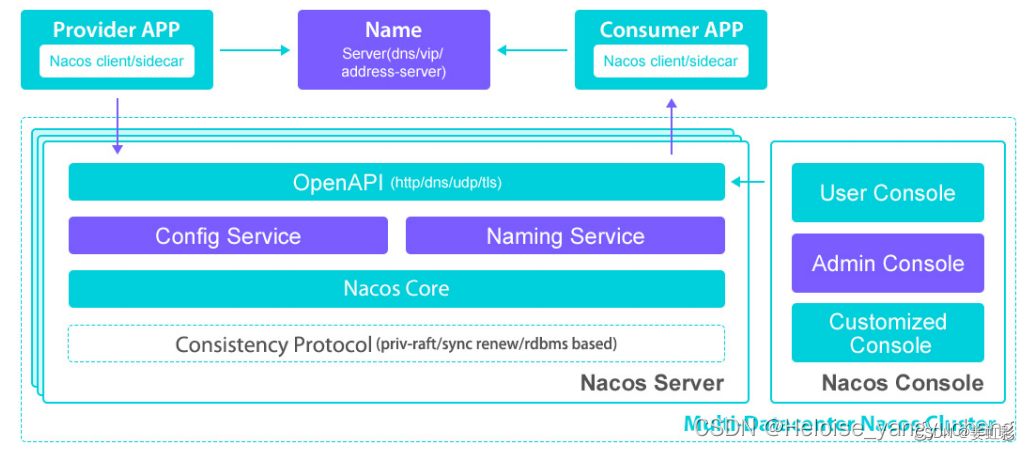
- Name Server:通过VIP(Virtual IP)或DNS的方式实现Nacos高可用集群的服务路由
- Nacos Server:Nacos服务提供者,里面包含的Open API是功能访问入口,Conig Service、Naming Service 是Nacos提供的配置服务、命名服务模块。Consitency Protocol是一致性协议,用来实现Nacos集群节点的数据同步,这里使用的是Raft算法(Etcd、Redis哨兵选举)
- Nacos Console:控制台
- Provider:服务提供者;consumer:服务消费者
- nacos信息同步的几种主要方式:
push (服务端主动push)
pull (客户端的轮询), 超时时间比较短
long pull (超时时间比较长)
- 配置中心
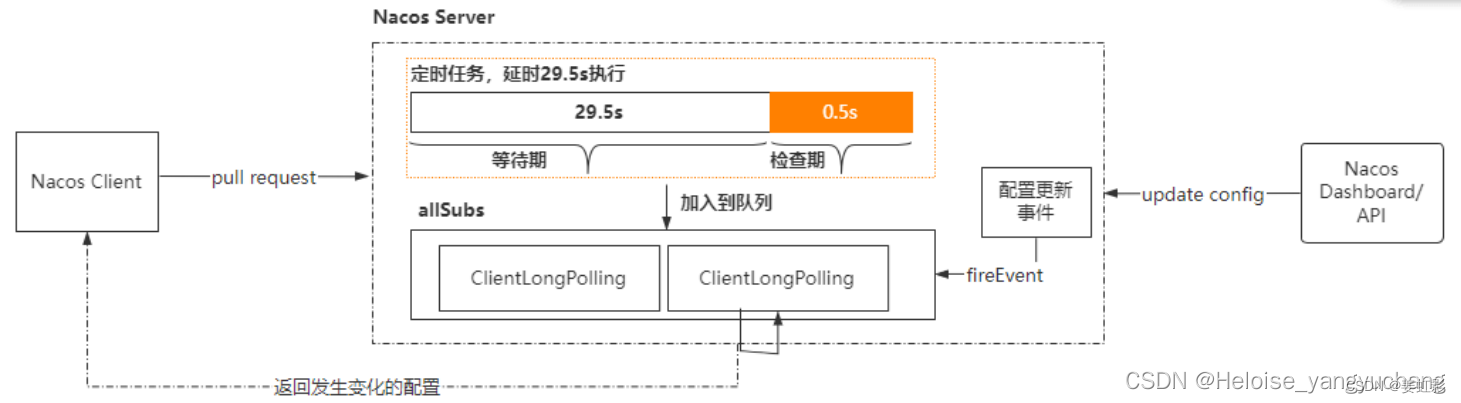
nacos 配置中心就是采用:客户端 long pull 的方式
- Nacos 客户端会循环请求服务端变更的数据,并且超时时间设置为30s,当配置发生变化时,请求的响应会立即返回,否则会一直等到 29.5s+ 之后再返回响应
- 客户端的请求到达服务端后,服务端将该请求加入到一个叫 allSubs 的队列中,等待配置发生变更时 DataChangeTask主动去触发,并将变更后的数据写入响应对象。
- 与此同时服务端也将该请求封装成一个调度任务去执行,等待调度的期间就是等DataChangeTask 主动触发的,如果延迟时间到了 DataChangeTask 还未触发的话,则调度任务开始执行数据变更的检查,然后将检查的结果写入响应对象(基于文件的MD5)
- 注册中心
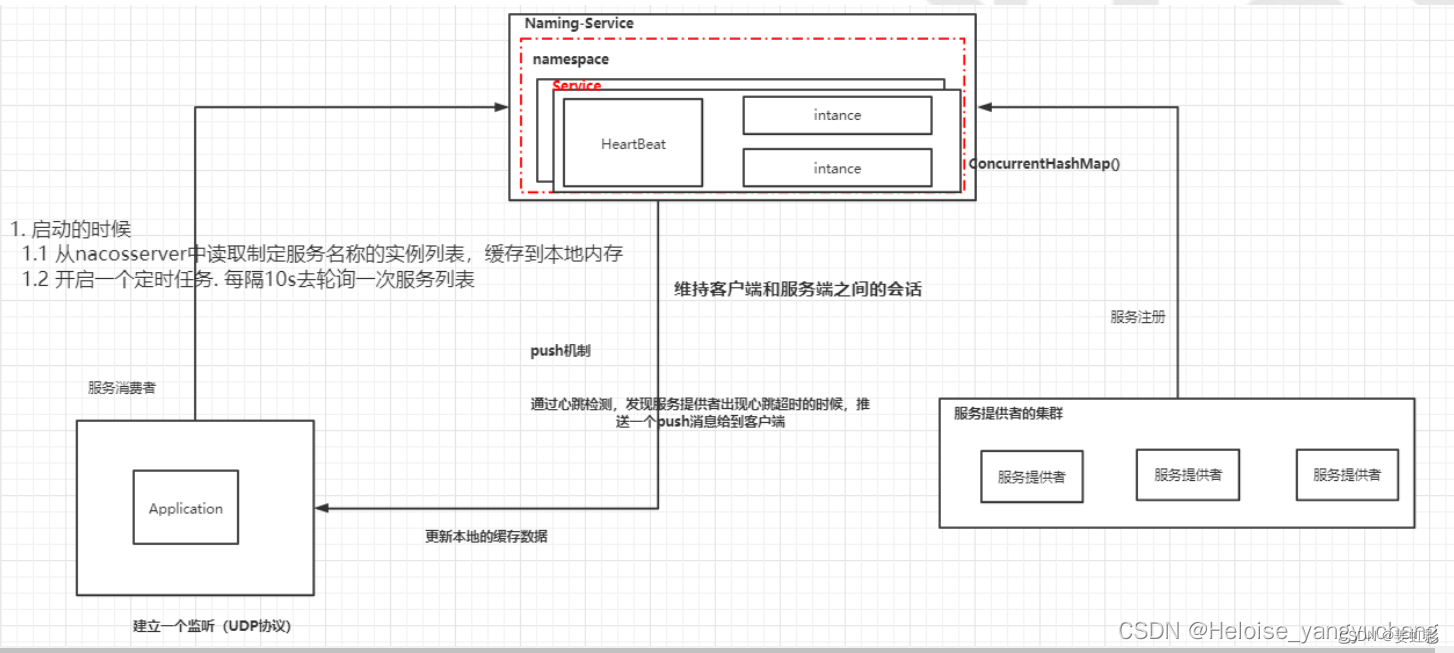
nacos注册中心采用pull (客户端的轮询)和push (服务端主动push)
- 客户端启动时会将当前服务的信息包含ip、端口号、服务名、集群名等信息封装为一个Instance对象,然后创建一个定时任务,每隔一段时间向Nacos服务器发送PUT请求并携带相关信息。
- nacos服务器端在接收到心跳请求后,会去检查当前服务列表中有没有该实例,如果没有的话将当前服务实例重新注册,注册完成后立即开启一个异步任务,更新客户端实例的最后心跳时间,如果当前实例是非健康状态则将其改为健康状态。
- 心跳定时任务创建完成后,通过POST请求将当前服务实例信息注册进nacos服务器。
- nacos服务器端在接收到注册实例请求后,会将请求携带的数据封装为一个Instance对象,然后为这个服务实例创建一个服务Service,一个Service下可能有多个服务实例,服务在Nacos保存到一个ConcurrentHashMap中Map(namespace,Map(group::serviceName, Service));。
- nacos将实例添加到对应服务列表中会根据AP和CP不同的模式,采用不同协议。
- CP模式就是基于Raft协议(通过leader节点将实例数据更新到内存和磁盘文件中,并且通过CountDownLatch实现了一个简单的raft写入数据的逻辑,必须集群半数以上节点写入成功才会给客户端返回成功)
- AP模式基于Distro协议(向任务阻塞队列添加一个本地服务实例改变任务,去更新本地服务列表,然后在遍历集群中所有节点,分别创建数据同步任务放进阻塞队列异步进行集群数据同步,不保证集群节点数据同步完成即可返回)
- nacos在将服务实例更新到服务注册表中时,为了防止并发读写冲突,采用的是写时复制的思想,将原注册表数据拷贝一份,添加完成之后再替换回真正的注册表。
- nacos在更新完成之后,通过发布服务变化事件,将服务变动通知给客户端,采用的是UDP通信,客户端接收到UDP消息后会返回一个ACK信号,如果一定时间内服务端没有收到ACK信号,还会尝试重发,当超出重发时间后就不在重发。
- 客户端通过定时任务定时从服务端拉取服务数据保存在本地缓存。
- 服务端在发生心跳检测、服务列表变更或者健康状态改变时会触发推送事件,在推送事件中会基于UDP通信将服务列表推送到客户端,虽然通过UDP通信不能保证消息的可靠抵达,但是由于Nacos客户端会开启定时任务,每隔一段时间更新客户端缓存的服务列表,通过定时轮询更新服务列表做兜底,所以不用担心数据不会更新的情况,这样既保证了实时性,又保证了数据更新的可靠性。
- nacos server与client(微服务)的心跳机制
-
服务的健康检查分为两种模式:客户端上报、服务端主动检测
- 客户端上报模式:客户端通过心跳上报的方式告知nacos 注册中心健康状态(默认心跳间隔5s,nacos将超过超过15s未收到心跳的实例设置为不健康,超过30s将实例删除)
- 服务端主动检测:nacos主动检查客户端的健康状态(默认时间间隔20s,健康检查失败后会设置为不健康,不会立即删除)
-
ap和cp模式
- nacos 的instance有一个ephemeral字段属性,该字段表示实例是否是临时实例还是持久化实例。如果是临时实例则不会在nacos中持久化,需要通过心跳上报,如果一段时间没有上报心跳,则会被nacos服务端删除。删除后如果又重新开始上报,则会重新实例注册。而持久化实例会被nacos服务端持久化,此时即使注册实例的进程不存在,这个实例也不会删除,只会将健康状态设置成不健康。
- nacos的client的节点注册时默认ephemeral=true,即ap模式,采用的是distro 协议,而ephemeral=false时就是CP采用的是raft协议实现。
#false为永久实例,true表⽰临时实例开启,注册为临时实例,默认是true
spring.cloud.nacos.discovery.ephemeral=true
* 对于临时实例,健康检查失败,则直接删除。这种特性适合于需要应对流量突增的场景,服务可以弹性扩容,当流量过去后,服务停掉即可自动注销。
* 对于持久化实例,健康检查失败,会设置为不健康状态。它的优点就是可以实时的监控到实例的健康状态,便于后续的告警和扩容等一系列处理。
- nacos自我保护机制防止网络分区和雪崩效应
- 针对某个service所有实例的自我保护机制:nacos也有自我保护机制(当前健康实例数/当前服务总实例数),值为0-1之间的浮点类型。正常情况下nacos 只会健康的实例。单在高并发场景,如果只返回健康实例的话,流量洪峰到来可能直接打垮剩下的健康实例,产生雪崩效应。
- 保护阈值存在的意义在于当服务A健康实例数/总实例数 < 保护阈值时,Nacos会把该服务所有的实例信息(健康的+不健康的)全部提供给消费者,消费者可能访问到不健康的实例,请求失败,但这样远比造成雪崩要好。牺牲了请求,保证了整个系统的可用。
- 如果所有的实例都是临时实例,当雪崩出现时,Nacos的阈值保护机制是不是就没有足够的(包含不健康实例)实例返回了,其实如果有部分实例是持久化实例,即便它们已经挂掉,状态为不健康,但当触发自我保护时,还是可以起到分流的作用。
- nacos集群
nacos集群与raft选主算法
nacos集群类似zookeeper,有leader和fllower两种角色,采用raft算法进行集群选主。部署nacos集群需要至少3个节点
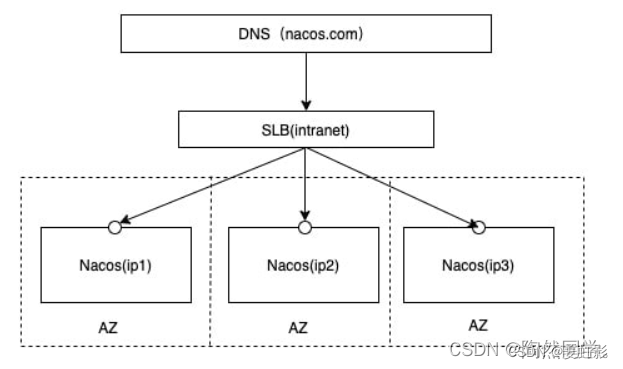
nacos集群部署参考文章
nacos与eureka对比
| 对比项 | nacos | eureka |
|---|---|---|
| cap | ap(默认)/cp(可选) | ap |
| 连接方式 | 长连接 | 短链接 |
| 服务异常剔除 | 15s未收到心跳标记为不健康状态可接收请求,30s删除实例不再接收请求 | 30s心跳,90s删注册表,60s清除间隔,客户端ribbion可能还缓存 |
| 服务实例管理 | nacos console可视化控制界面,上下限、权重等设置;提供配置中心对实例配置crud,版本管理 | 提供实例列表、实例状态信息,较为简单 |
| 自我保护 | 超过阈值都会自我保护。针对某个具体service,处于自我保护状态,将service健康和不健康的服务都返回给client,避免雪崩问题 | 针对所有实例,自我保护状态不会剔除服务,可以注册服务 |
| 集群部署 | 至少三台,raft选主 | 最低两台即可高可用,节点间数据p2p同步,有一个节点存活即可正常提供服务,数据有可能过期 |
常用配置
spring:
cloud:
nacos:
# Nacos 作为注册中心的配置项,对应 NacosDiscoveryProperties 配置类
discovery:
server-addr: 127.0.0.1:8848 # Nacos 服务器地址;集群情况下配负载均衡如nginx的地址;或者配置多台nacos地址以逗号分隔
service: ${spring.application.name} # 注册到 Nacos 的服务名。默认值为 ${spring.application.name}。
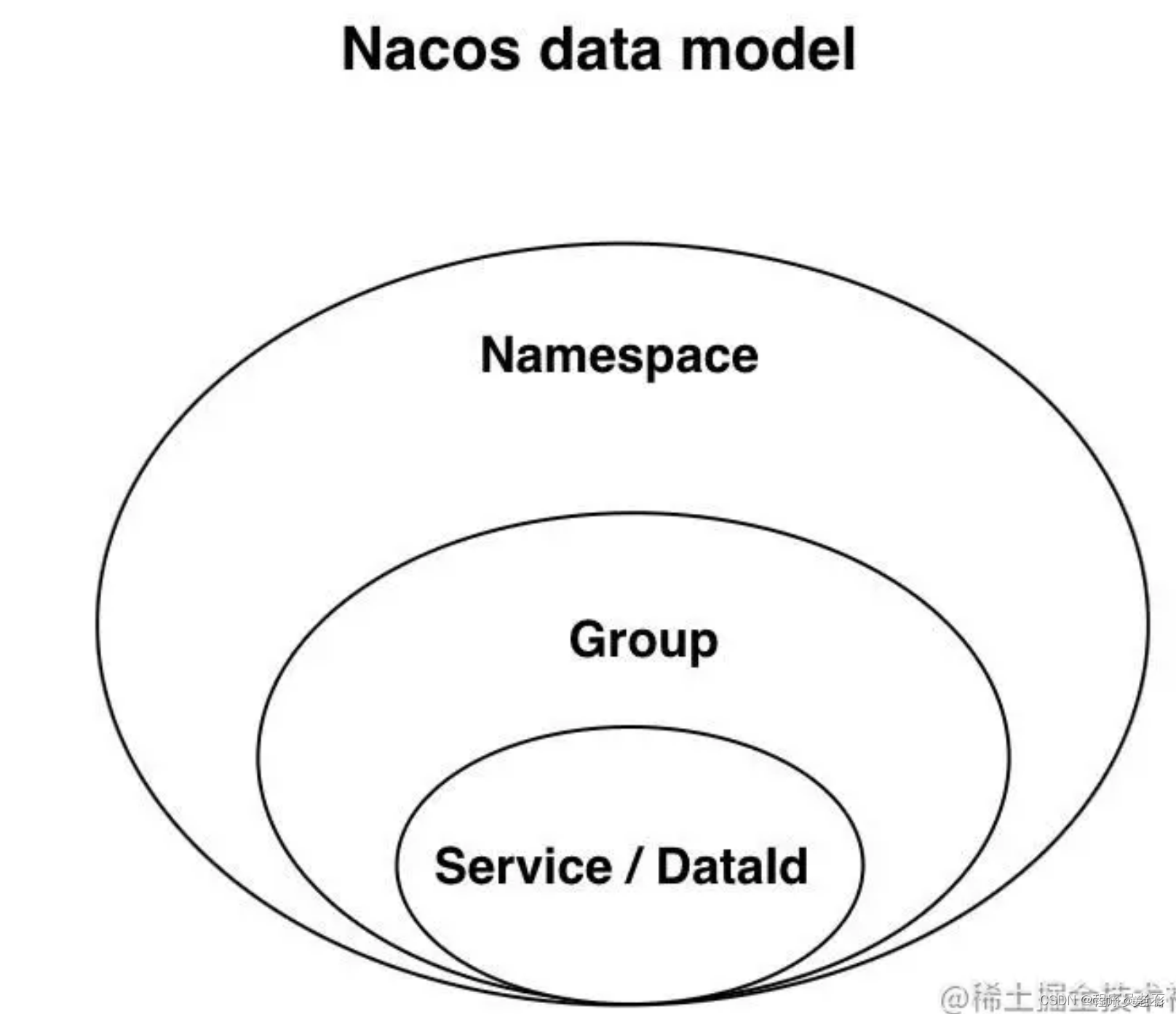
作为注册中心时,Namespace + Group + Service
作为配置中心时,Namespace + Group + DataId
Namespace: 租户隔离,常见用法是用来隔离不同环境
Group服务分组:不同的服务可以归类到统一分组。默认为DEFAULT_GROUP(默认分组)
Service服务:如用户服务、账户服务等
Feign & Ribbon & Hystrix
ribbon
原理
- ribbon是一个客户端负载均衡组件
- 默认支持其中负载均衡算法(可自定义扩展):
- RoundRobinRule:轮询
- RandomRule:随机
- AvailabilityFilteringRule:会先过滤掉由于多次访问故障而处于断路器状态的服务,还有并发的连接数量超过阈值的服务,然后对剩余的服务列表按照轮询策略进行访问
- WeightedResponseTimeRule:根据平均响应时间计算所有服务的权重,响应时间越快的服务权重越大被选中的概率越大。刚启动时如果统计信息不足,则使用RoundRobinRule(轮询)策略,等统计信息足够,会切换到WeightedResponseTimeRule
- RetryRule:先按照RoundRobinRule(轮询)策略获取服务,如果获取服务失败则在指定时间内进行重试,获取可用的服务
- BestAvailableRule:会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
- ZoneAvoidanceRule:复合判断Server所在区域的性能和Server的可用性选择服务器
- 原理:
ribbon可以基于restTemplate加@LoadBalance注解或者Feign默认集成ribbon,RibbonLoadBalancerClient每隔30s(eureka-client)从注册中心同步服务列表;并且内部启动线程池,定时通过ping的方式检测服务列表中服务状态,如果可用则维护进可用服务列表中。
ribbon维护两个服务列表:1. 从注册中心同步的服务列表A;2.经过定时ping任务检查可用的服务列表B
IPing机制
Iping是ribbon主动探测服务节点是否存活的机制,通过判断服务节点的状态,设置节点是否可用。
参考文章
Iping有以下几种实现:
- DummyPing:默认返回true,即认为所有节点都可用,这也是单独使用Ribbon时的默认模式
- NIWSDiscoveryPing:借助Eureka服务发现机制获取节点状态。节点状态是UP,则认为是可用状态
- PingUrl:主动向服务节点发起一次http调用,对方有响应则认为节点是可用状态
- NoOpPing:返回true
- PingConstant:返回设置的常量值
常用参数
- ribbon的参数配置包括通用配置(所有客户端的默认值),或针对于某个客户端的配置:
通用配置格式为:ribbon.=
配置某个具体客户端参数为:.ribbon.= - 下面是常用配置
# 超时时间(和feign的超时配置二选一,feign的配置优先,feign不配置时使用ribbin的,推荐使用ribbon)
#请求连接的超时时间,单位为毫秒,默认2秒
ribbon.ConnectTimeout=2000
# 请求处理的超时时间(即响应的超时时间),单位为毫秒,默认5秒
ribbon.ReadTimeout=5000
# 单个服务最大重试次数,不包含对单个服务的第一次请求,默认0
MaxAutoRetries: 3
# 服务切换次数,不包含最初的服务,如果服务注册列表小于 nextServer count 那么会循环请求 A > B > A,默认1
MaxAutoRetriesNextServer: 2
#是否所有操作都进行重试,默认只重试get请求,如果修改为true,则需注意post\put等接口幂等性
OkToRetryOnAllOperations: false
Hystrix
原理
-
hystrix是通过资源隔离实现服务熔断降级的组件,断路器。
-
hystrix既可以用于客户端(@FeignClient fallback属性),也可用于服务端(@controller @HystrixCommand fallbackMethod属性)
-
不是所有的请求都需要进行降级操作,也可以只做熔断
-
Hystrix处理过程:

流程说明:
- 构造一个 HystrixCommand或HystrixObservableCommand对象,用于封装请求,并在构造方法配置请求被执行需要的参数;
- 执行命令,Hystrix提供了4种执行命令的方法(下面详述)
- 判断是否使用缓存响应请求,若启用了缓存,且缓存可用,直接使用缓存响应请求。Hystrix支持请求缓存,但需要用户自定义启动;
- 判断熔断器是否打开,如果打开,跳到第8步;
- 判断线程池/队列/信号量是否已满,已满则跳到第8步;
- 执行HystrixObservableCommand.construct()或HystrixCommand.run(),如果执行失败或者超时,跳到第8步;否则,跳到第9步;
- 统计熔断器监控指标;这里至少需要知道两个指标,只有这两个指标同时达到阈值的时候,才会发生熔断:
1. 滚动窗口时间内请求量
2. 滚动窗口时间内发生错误的请求量 - 走Fallback备用逻辑
- 返回请求响应
- 资源隔离的两种方式:
- Hystrix线程池隔离:如果使用公共线程处理请求,某个接口的处理能力变慢,占用公用线程的时间变长,如果接口的并发量高,将导致整个服务的处理能力下降。hystrix可以为某个接口或者某几个接口设置独立的线程池,该线程池满后只影响该接口的服务而不影响整体的服务(默认模式)。分两个阶段:
- 请求command阶段,是应用请求的公共线程,可以设置超时时间
- 执行command阶段,独立的hystrix线程,可以有效的避免级联故障,当线程池或者请求队列饱和时,将拒绝服务,使得请求线程可以快速失败,避免级联故障
可以设置超时;增加了排队、线程上下文切换的开销;适用于网络请求
- 信号量隔离:可以为一个或几个接口设置独立的信号量,信号量满后该接口就走fallback的逻辑。该接口信号量满后只影响对应接口而不影响整个服务。同步请求,大量并发请求时只有信号量大小会真正请求,不能进行超时设置,只能等待服务器返回。轻量,没有线程上下文的切换;适合高并发,快速失败的情况,一般为内存调用、缓存请求的场景。
- 两种资源隔离方式对比
- Hystrix线程池隔离:如果使用公共线程处理请求,某个接口的处理能力变慢,占用公用线程的时间变长,如果接口的并发量高,将导致整个服务的处理能力下降。hystrix可以为某个接口或者某几个接口设置独立的线程池,该线程池满后只影响该接口的服务而不影响整体的服务(默认模式)。分两个阶段:
| 资源隔离模式 | 线程切换 | 支持异步 | 支持超时 | 支持熔断 | 限流 | 开销 |
|---|---|---|---|---|---|---|
| 信号量 | 否 | 否 | 否 | 是 | 是 | 小 |
| 线程池 | 是 | 是 | 是 | 是 | 是 | 大 |
- Hystrix四种执行命令的方法:
代码参考
参考文章- HystrixCommand同步执行,execute()
- HystrixCommand异步执行,返回Future,queue()
- HystrixObservableCommand异步执行,订阅时直接返回结果,observe
- HystrixObservableCommand同步执行,订阅时才开始执行,toObservable
(后两种方式HystrixCommand也支持,但是支持只支持返回一个结果,HystrixObservableCommand支持返回多个结果)
常用配置
可以配置全局默认的配置,也可以某个comandKey特殊配置
hystrix:
threadpool:
default:
coreSize: 500
command:
#全局默认配置,如果要配置具体command的,则可以参考defaut配置一套commandKey的
default:
#熔断器属性配置,达到下面两个阈值才会熔断
circuitBreaker:
requestVolumeThreshold: 20 #默认滑动窗口时间内,请求量达到20次,进行熔断
errorThresholdPercentage: 50 #默认滑动窗口时间内,错误请求量达到百分之50,进行熔断
metrics:
rollingStats:
timeInMilliseconds: 10000 #默认滑动窗口时间10s
#线程隔离相关
execution:
#是否给方法执行设置超时时间,默认为true。一般我们不要改。
timeout:
enabled: true
isolation:
#配置请求隔离的方式,这里是默认的线程池方式。还有一种信号量的方式semaphore。
strategy: THREAD
thread:
#方式执行的超时时间,默认为1000毫秒,在实际场景中需要根据情况设置
timeoutInMilliseconds: 10000
如果使用ribbon(或feign)的超时时间配置,则hystrix的超时时间应不小于ribbon(或feign)的总超时时间,否则会导致ribbin还没返回就被熔断返回,ribbon的重试机制可能就没用了。
ribbon总超时时间=(ConnectTimeout+ReadTimeout)(MaxAutoRetries+1)(MaxAutoRetriesNextServer+1);//(连接超时时间+响应超时时间)总重试次数(包含原节点的重试次数和重试新节点的次数);
若使用feign的超时时间(一般不用,不支持重试新节点),则Retryer.Default.maxAttempts(ConnectTimeout+ReadTimeout)
hystrix与sentinel对比
| 组件 | 资源隔离实现方式 | 性能 | 开源维护 |
|---|---|---|---|
| hystrix | 线程池、信号量 | 推荐使用线程池,有额外开销 | Netflix不再维护 |
| sentinel | 信号量 | 高 | 阿里团队一直迭代,活跃度高 |
Feign
原理
- feign是声明式的rest客户端工具,基于api做动态代理,简化远程服务的调用,可以像调用本地方法一样调用远程服务
- feign的服务调用流程:

常用配置
可以配置全局配置,也可以对某个client单独配置
feign:
# 是否启用hystrix
hystrix:
enabled: true
client:
config:
# 全局配置
default:
# 超时时间,不配置则使用ribbon的超时时间
connectTimeout: 5000
readTimeout: 5000
# 实例配置,feignName即@feignclient中的value,也就是服务名
feignName:
connectTimeout: 5000
readTimeout: 5000
















 1179
1179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









