







本文主要了解hadoop重要组件之一的资源管理框架YARN,了解其原理以及提交任务的流程。
Hadoop 1.0 没有把资源管理功能独立出来也就没有YARN这个组件,所以下面的介绍是基于Hadoop 2.0以后的版本。
一、YARN 简介
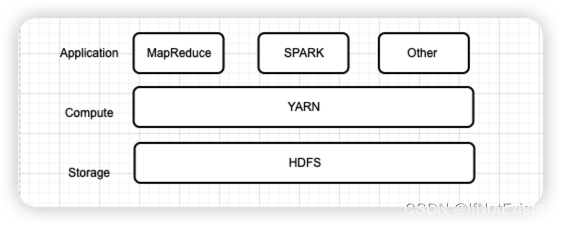
YARN是一种Hadoop的资源管理系统和调度平台,用户通过使用不同的数据处理方法(如图形处理、交互处理、流式处理、批处理来)、工具 等操作存储在HDFS上的数据。
二、YARN 原理
YARN架构
注:图片来源于网络
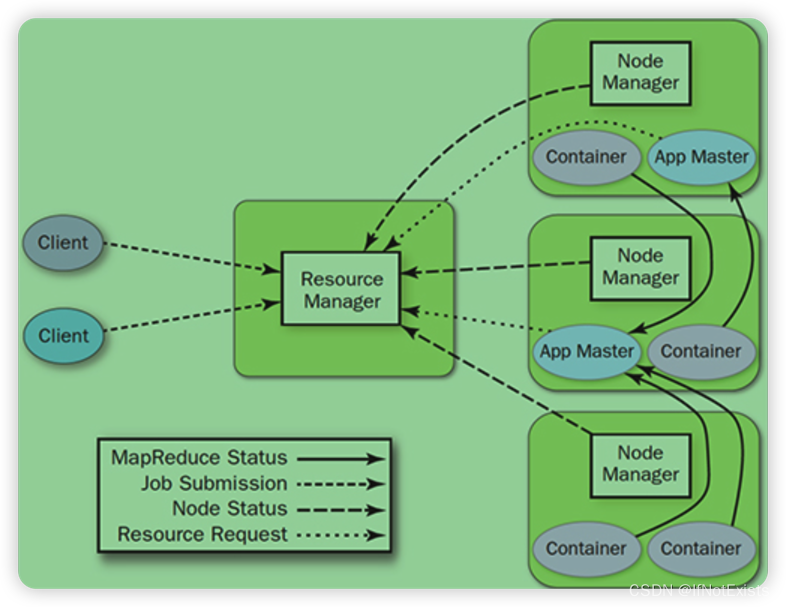
网上很多资料把YARN比作一个分布式的操作系统,MapReduce 是运行在系统上的应用程序,程序使用的系统资源如CPU、MEM由YARN提供管理。除了资源管理外,YARN还执行作业调度,用于执行客户端提交的各种操作。
YARN组成
YARN不需要单独的部署,前面部署HDFS时有提到YARN的启动。具体可参考:https://blog.csdn.net/weixin_42633805/article/details/129680965
通过进程查看发现执行完start-yarn.sh后,在NameNode启动了 ResourceManager进程,DataNode 上启动了 NodeManager 进程。其中 RM进程主要负责集群的资源调度,NM主要负责具体服务器上的资源和任务管理。
从上图看除了RM、NM外还有App Master 、Container 两个角色。App Master 主要是提交的单个作业。Container可以理解为系统资源的一种抽象和封装,便于YARN对资源的管理。
总结:
YARN包括以下组件:
ResourceManager:负责全局资源管理和任务调度
NodeManager:负责单个节点的资源管理和监控
ApplicationMaster:负责单个作业的资源管理和任务监控
Container:资源申请的单位和任务运行的容器
组件功能
3.1 ResourceManager
该组件主要负责处理客户端请求、监控NodeManager、启动和监控ApplicationMaster以及全局的资源管理和任务调度。包括两个主要组件:
ApplicationManager:应用程序管理器,负责接收工作提交,执行并管理特定的应用程序ApplicationMaster,当ApplicationMaster故障时负责重启该容器。
Scheduler:调度器,负责按照资源配置策略将资源分配给各种正在运行的Application。
调度器包括:
FIFO调度器:单队列,先进先出。集群中的应用程序按照提交的顺序执行,同时只能有一个作业运行。好处:单作业可以充分利用集群资源。缺点:很容易因为某个作业过大导致后续作业的阻塞。
容量调度器:Capacity Scheduler,Hadoop3.x 默认的调度器,用户可以自己分配调整资源队列。优点:多队列,多用户,用户通过设置最低资源使用和资源上限以及优先级灵活合理的分配资源和任务的执行顺序。
公平调度器:Fair Scheduler,队列资源分配方式,在整个时间线上,所有的作业平均获得资源,同队列中所有作业共享资源。适合多用户共享的大集群。
3.2 NodeManager
负责管理和处理Hadoop集群中各个节点上的作业,包括容器的生命周期和资源使用情况。同时负责向资源管理器注册并发送包含节点监控状态信息的心跳。
3.3 ApplicationMaster
应用程序是提交给计算框架的单个作业。ApplicationMaster 负责从资源管理器协商资源,与节点管理器一起执行、监控作业的状态和进度,并通过定期向资源管理器发送心跳以确认其健康状况和资源需求记录。
3.4 Container
一个任务运行环境的抽象,物理资源的集合,包含MEM、CPU等资源。当ApplicationMaster向ResouceManager申请资源时,RM为AM返回的资源就是Container。YARN为每一个任务分配一个Container。
4. YARN 工作机制
客户端提交作业;
ResourceManager(RM)选择一个NodeManager, 启动一个Container并运行ApplicationMaster(AM)实例;
AM向RM注册,并向RM申请资源;
AM通知NM 启动Container;
AM通过获取到的Contation资源执行分布式计算;
客户端连接RM获取Application 的状态;
AM向RM取消注册信息。
5. YARN的失败处理
5.1 Task失败
当任务(包括MapTask、ReduceTask)出现异常退出时会报告给ApplicationMaster;
ApplicationMaster会通过心跳判断任务是否失败;
失败的任务或作业都会被AM重新运行。
5.2 ApplicationMaster失败
AM会定时向RM 发送心跳信息,确定自己是正常的;
AM失败,RM会启动一个新的AM;
新的AM负责恢复之前失败的AM的状态;
客户端会定期向AM查询进度和状态,一旦发现其失败,则向RM询问新的AM。
5.3 NodeManager失败
NM会定时向RM发送心跳信息,确定自己是正常的;
RM超过预定时间没有收到心跳信息,会移除该NM;
任何运行在该NM上的任务、AM 都会在其他NM上恢复。
5.4 ResourceManager失败
通过ZK实现状态同步和失败自动切换。
三、工作流程
作业提交流程
注:图片来源于网络。
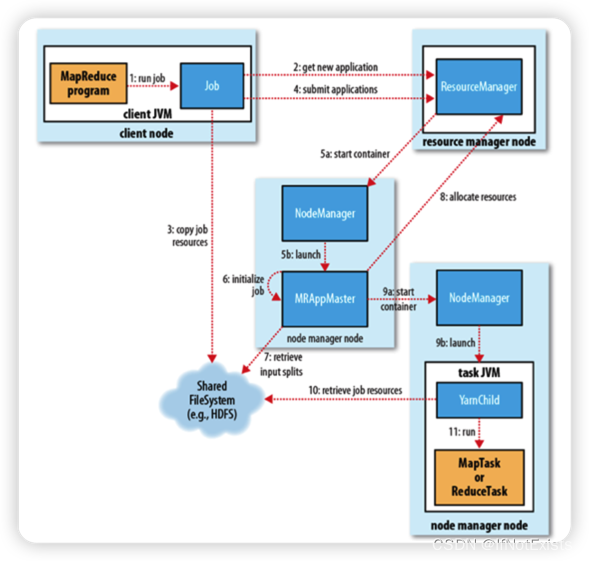
作业提交
客户端向集群提交MapReduce作业;
客户端向RM申请一个作业ID;
RM给客户端返回该作业的提交路径和ID;
客户端提交jar包、切片信息、配置文件到指定的资源路径;
客户端提交完资源后,向RM申请运行作业应用程序管理器。
作业初始化
当RM收到客户端请求后,将作业添加到容器中;
某一NodeManger领到该作业,创建容器,并产生MapReduce ApplicationMaster;
下载客户端提交的资源到本地。
任务分配
MapReduce ApplicationMaster向RM 申请运行多个MapTask 资源。
RM 将运行 MapTask 分配给多个NodeManager。这些NodeManager领取任务并创建容器。
任务运行
MapReduce 向这些NM 发送程序启动脚本,这些NM 启动MapTask,对数据分区排序。
MapReduce ApplicationMaster 等待所有的MapTask 运行完成,向RM 申请资源运行ReduceTask。
ReduceTask向MapTask获取相应的分区数据。
MapReduce 等待ReduceTask 运行完后,向RM申请注销自己。
进度和状态更新
YARN中的任务将其进度和状态返回给ApplicationManager.
客户端每1秒会向AM请求进度更新,并返回给用户。
作业完成
客户端每5秒检查作业是否完成。
AM 和 Container会清理工作状态,作业的信息会被作业历史服务器存储供后续查看。















 8675
8675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









