









JAVA爬虫豆瓣搜索页 解析 window.__DATA__ 策略
最近在用java做豆瓣爬虫,节目分类那块问题不大,就是做搜索获取内容的时候,获取不到返回的页面数据,经过搜索后,已解决。
解决思路
- 发送http搜索请求,获取返回值
- 解析返回值中 “window.DATA” 的值
- 解码获取数据
步骤
- 发送请求获取返回值,提取 “window.__DATA__” ,是一串加密字符串
private String getDoubanWindowData(String moviename, String pagestart) throws BusinessException, InterruptedException {
//网址
String url = String.format("https://search.douban.com/movie/subject_search?search_text=%s&cat=1002&start=%s", moviename, pagestart);
//返回值
String htmlData = JobHttpUtils.getHtmlData(url, 0, JobContanst.DOUBAN_HOST_SEARCH, HttpType.DETAIL, false);
//正则获取指定内容
Pattern pp = Pattern.compile("window\\.__DATA__ = \"([^\"]+)\"");
Matcher m = pp.matcher(htmlData);
if (m.find()) {
return m.group(1);
}
return "";
}
-
解码获取数据
解码的话有一位大神已经处理出一个JS文件,只需要调用方法可获得搜索数据
这是我看到原博客地址:原博客地址(感谢大哥!)
JS文件链接: JS文件 提取码:redz
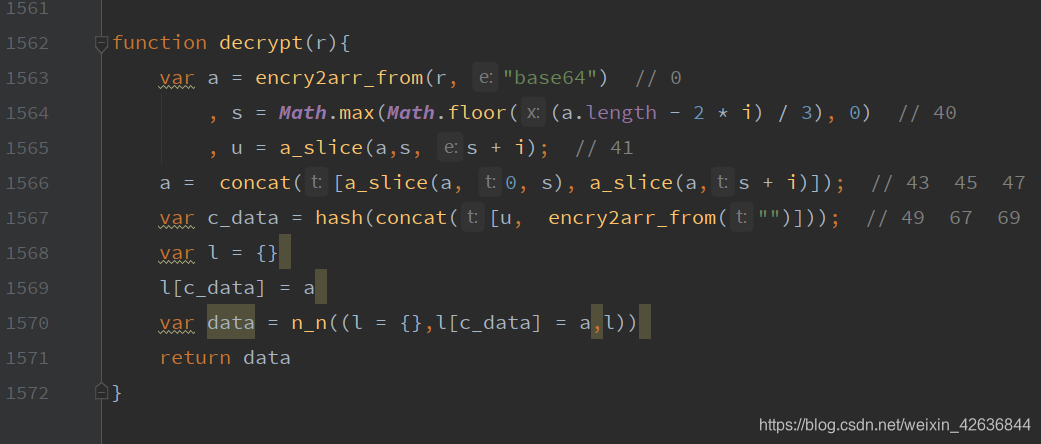 这个方法,传入加密字符串,返回一个Object
这个方法,传入加密字符串,返回一个Object
实例: decrypt(‘加密字符串’).payload.items,返回值为数据数组
最后说一句
我本来计划用JAVA加载JS文件调用方法,在JAVA层面执行获取返回值,但是好像不太行,所以暂时用的方法是交给页面处理再传到后台。
如果有哪位兄弟可以后台直接调,麻烦留言告知一下,谢谢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









