







 本文介绍了如何使用Python进行虎牙直播间的爬虫开发,包括创建项目、添加requests和lxml库、分析网页元素和JSON数据,以及解决爬取速度问题,最终实现多线程爬虫。
本文介绍了如何使用Python进行虎牙直播间的爬虫开发,包括创建项目、添加requests和lxml库、分析网页元素和JSON数据,以及解决爬取速度问题,最终实现多线程爬虫。
使用pycharm新建一个pyhton项目(python版本3.7)

将untitled修改成自己取得项目名称。
Location表示路径。
new environment using 表示新建一个项目依赖配置
会新建一个venv(virtualenv)目录,这里存放一个虚拟的python环境。这里所有的类库依赖都可以直接脱离系统安装的python独立运行
existing interpreter 选择一个已存在的项目依赖配置
首次操作选择一个新建的配置
利用pycharm添加依赖项
推荐一个不错的添加依赖项的教程链接
添加requests库
requests库是爬虫需要的最基本的库,向目标网站发送requests请求,并通过.text方法展现出来具体展现出来:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
#虎牙导航页面
r = requests.get('https://www.huya.com/g', headers=headers)
if r.status_code == 200:
print(r.text)
headers的作用:告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.。因为很多网页并不对爬虫并不感冒,想要爬取数据需要伪装一下。添加header可以伪装成浏览器反问网页。
获取header
打开任意浏览器,右键“审查元素”或者直接F12,。复制User-Agent里的这段。

添加lxml库
由于我使用的python版本为3.7.2,最新版的lxml对它的支持不是很好我安装的是lxml 4.2.5的版本。
关于lxml的语法参考链接
准备工作做完,接下来我们开始爬取虎牙的信息
审查虎牙的元素
观察导航跳转的变化
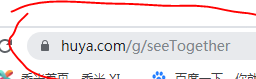
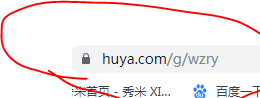
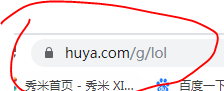
有类型名字的中文首字母拼写(王者荣耀->wzry),有英文翻译(一起看->seeTogether),还有不知道什么是的变化(英雄联盟->lol)。没找到什么规律
再次F12审查一下导航页面的元素
(Ctrl+Shift+C)点击要寻找的元素发现

这个gid每个分类对应一个貌似可以拿来试试
https://www.huya.com/g/1 ,https://www.huya.com/g/2336 ,https://www.huya.com/g/2135
居然真的可以访问,哦,Nice!
因此有了gid就可以访问所有虎牙分类的页面了。
import requests
from lxml import html
gidlist = []
r = requests.get('https://www.huya.com/g', headers=headers)
#百度来的lxml4.2.5在python3.7中的用法(最新的lxml在python3中没有etree用法)
selector = html.etree.HTML(r.text)
#获取页面上所有的gid存放在一个List之中
#l是一个xpath里的一个对象类似于迭代器还是放到List里面用的比较习惯
l = selector.xpath('//div[@class="box-bd"]/ul/li/@gid')
for i in range(len(l)):
gidlist.append(l[i])
print(gidlist)
但是还有个问题需要考虑,就是对于每一个直播分类来说,依旧存在页面跳转的问题
以英雄联盟为例,已经到了跳转到第二页了但是导航栏地址却没有变。说明虎牙到第二页的方式不是页面跳转而是类似ajax的方式来实现网页信息的改变。
依旧是F12审查元素,选择NetWork->XHR。进行同一类型(以英雄联盟为例)不同页面的跳转(第一页,第二页这种)。仔细观察新增加的文件,发现一个有趣的现象。
双击进入这三个任意一个地址
https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1&tagAll=0&page=1
发现里面是一个JSON格式的数据。使用经典道具,JSON.cn得到下图:
事情渐渐变得好起来了呀。
可以看到这个有了JSON格式的数据,可帮助我们从HTML的元素中解放出来了。
毕竟HTML里的元素各种各样的标签,但JSON里就是很舒服的数组,数据,Object三种。
虎牙的前端应该也是接受到这个JSON文件再用前端代码很好的展示出来(个人猜测)只要大概读懂了里面数据的格式就可以很轻松取得我们想要的信息。
直接上代码:
import json
#gidlist是上段代码的gidlist大家可自行拼接
gid  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1171
1171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









