







 本文是作者在风变编程学习爬虫的知识总结,涵盖了爬虫工作步骤、数据获取、解析、存储以及进阶技巧。从请求网页、解析HTML到使用BeautifulSoup提取数据,再到存储数据到Excel和CSV,还涉及了使用POST、cookies、session、Selenium等高级技术。文章最后介绍了Scrapy框架的基本使用和爬虫项目的组织结构。
本文是作者在风变编程学习爬虫的知识总结,涵盖了爬虫工作步骤、数据获取、解析、存储以及进阶技巧。从请求网页、解析HTML到使用BeautifulSoup提取数据,再到存储数据到Excel和CSV,还涉及了使用POST、cookies、session、Selenium等高级技术。文章最后介绍了Scrapy框架的基本使用和爬虫项目的组织结构。
概述
疫情期间在风变编程(https://www.pypypy.cn/#/)上学习了爬虫的相关知识,风变编程是一个交互式学习网站,目前开的模块还不是很多但是交互式在线教学实验的形式还是十分有趣,交互式的形式教一个读书顺序,督催一行一行读书,告诉什么时候应该动手,什么时候应该总结。
我们日常的数据来源可能通过爬虫、日志、业务数据库、智能硬件、第三方数据渠道、调研、实验、EXCEL采报等,爬虫作为数据获取的重要途经之一,作为数据分析人员也是必会的技能之一。
下面就网站的学习进行了简要的知识点记录。
爬虫工作步骤
Robots协议是互联网爬虫的一项公认的道德规范,在网站的域名后加上/robots.txt查看哪些页面是可以抓取的,哪些不可以
我们一般会选择用type()函数查看一下数据类型,因为Python是一门面向对象编程的语言,只有知道是什么对象,才能调用相关的对象属性和方法。
首先思考项目如何实现:
根据目标找方案,根据方案做执行,执行遇到问题就去学习、搜索
- 获取数据
根据提供的网址向服务器发出请求
需要什么数据,到哪去找数据(确定能不能取) - 解析数据
可以代替浏览器解析数据(解析计算机语言)
分析网页结构(html,网络请求)(先看第0个框架请求看所需要数据是否在HTML中找element,再找XHR动态刷新), - 提取数据
确定最小共同父级标签或者分别提取(搜索确定是否能精确定位,),先 小再大(query string parametre)地取数据,遇到问题再回头分析过程(network) - 储存数据
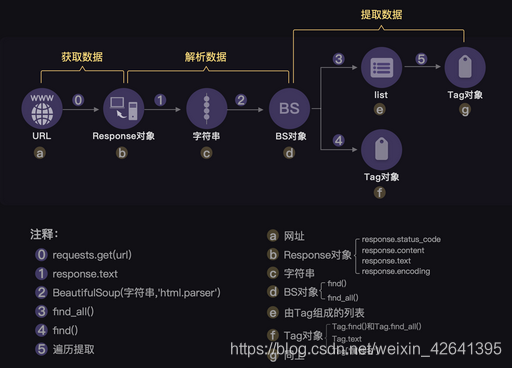
获取数据
request
下载网页源码,文本,图片,音频
pip install requests
| 属性 | 作用 |
|---|---|
| response.status_code | 检查请求是否成功 |
| response.content | 把response对象转换为二进制数据 |
| response.text | 把response对象转换为字符串数据 |
| response.encoding | 定义response对象的编码 |
- status_code
| 响应状态码 | 说明 | 举例 | 说明 |
|---|---|---|---|
| 1xx | 请求收到 | 100 | 继续提出请求 |
| 2xx | 请求成功 | 200 | 成功 |
| 3xx | 重定向 | 305 | 应使用代理访问 |
| 4xx | 客户端错误 | 403 | 禁止访问 |
| 5xx | 服务器端错误 | 503 | 服务不可用 |
- content
它能把Response对象的内容以二进制数据的形式返回,适用于图片、音频、视频的下载
# 引入requests库
import requests
# 发出请求,并把返回的结果放在变量res中
res = requests.get('https://res.pandateacher.com/2018-12-18-10-43-07.png')
# 把Reponse对象的内容以二进制数据的形式返回
pic = res.content
# 新建了一个文件ppt.jpg,这里的文件没加路径,它会被保存在程序运行的当前目录下。
# 图片内容需要以二进制wb读写。你在学习open()函数时接触过它。
photo = open('ppt.jpg','wb')
# 获取pic的二进制内容
photo.write(pic)
# 关闭文件
photo.close()
- text
可以把Response对象的内容以字符串的形式返回,适用于文字、网页源代码的下载。
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md')
#下载《三国演义》第一回,我们得到一个对象,它被命名为res
novel=res.text
#把Response对象的内容以字符串的形式返回
print(novel[:800])
#现在,可以打印小说了,但考虑到整章太长,只输出800字看看就好。在关于列表的知识那里,你学过[:800]的用法。
k = open('《三国演义》.txt','a+')
# 写进文件中
k.write(novel)
# 关闭文档
k.close()
数据解析,提取数据
BeautifulSoup解析网页
pip install BeautifulSoup4
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象
# 第1个参数用来标识解析器,我们要用的是一个Python内置库:html.parser。(它不是唯一的解析器,但是比较简单的)
虽然response.text和soup打印出的内容表面上看长得一模一样,却有着不同的内心,它们属于不同的类:<class ‘str’> 与<class ‘bs4.BeautifulSoup’>。前者是字符串,后者是已经被解析过的BeautifulSoup对象。之所以打印出来的是一样的文本,是因为BeautifulSoup对象在直接打印它的时候会调用该对象内的str方法,所以直接打印 bs 对象显示字符串是str的返回结果。
提取数据
| 方法 | 作用 | 用法 | 示例 |
|---|---|---|---|
| find() | 提取满足要求的首个数据 | BeautifulSoup对象.find(标签,属性) | soup.find(‘div’,class_=‘books’) |
| find_all() | 提取满足要求的所有数据 | BeautifulSoup对象.find_all(标签,属性) | soup.find_all(‘div’,class_=‘books’) |
- find
提出首个元素(tag对象)
soup = BeautifulSoup(res.text,'html.parser')
item = soup.find('div') #使用find()方法提取首个<div>元素,并放到变量item里
- find_all
ResultSet对象,是Tag对象以列表结构储存了起来
# 返回的知识列表
items = soup.find_all('div')
print(type(items))
print(items)
如果只用其中一个参数就可以准确定位,就只用一个参数检索,标签,属性(类,ID)
用什么参数去查找和定位(在浏览器中查找,观察,相同的属性是提取数据的关键)
- 从列表中提取值(包含了HTML标签)
for item in items:
print('想找的数据都包含在这里了:\n',item) # 打印item
tag(从包含了HTML标签的数据中提取出需要的数据值)
- find(),find_all()
Tag对象可以使用find()与find_all()来继续检索
当我们在用text获取纯文本时,获取的是该标签内的所有纯文本信息,不论是直接在这个标签内,还是在它的子标签内
text可以这样做,但如果是要提取属性的值,是不可以的。父标签只能提取它自身的属性值,不能提取子标签的属性值
for item in items:
kind = item.find('h2') # 在列表中的每个元素里,匹配标签<h2>提取出数据
title = item.find(class_='title') #在列表中的每个元素里,匹配属性class_='title'提取出数据
brief = item.find(class_='info') #在列表中的每个元素里,匹配属性class_='info'提取出数据
print(kind,'\n',title,'\n',brief) # 打印提取出的数据
print(type(kind),type(title),type(brief)) # 打印提取出的数据类型
- Tag.text,Tag[‘属性名’]
Tag.text提出Tag对象中的文字,用Tag[‘href’]提取出URL
print(kind.text,'\n',title.text,'\n',title['href'],'\n',brief.text) # 打印书籍的类型、名字、链接和简介的文字
在实践操作当中,其实常常会因为标签选取不当,或者网页本身的编写没做好板块区分,你可能会多打印出一些奇怪的东西
一般有两种处理方案:数量太多而无规律,我们会换个标签提取;数量不多而有规律,我们会对提取的结果进行筛选——只要列表中的若干个元素就好
确定最小共同父级标签
也有一些网页,直接把所有的关键信息都放在第0个请求里,尤其是一些比较老(或比较轻量)的网站,我们用requests和BeautifulSoup就能解决
请求解析json数据
- XHR
Ajax技术(技术本身和爬虫关系不大,在此不做展开,你可以通过搜索了解)。应用这种技术,好处是显而易见的——更新网页内容,而不用重新加载整个网页。
这种技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现,服务器和浏览器之间
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1899
1899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









