







1. 什么是线程?线程和进程的区别?
-
线程:是进程的一个实体,是 cpu 调度和分派的基本单位,是比进程更小的可以独立运 行的基本单位。
-
进程:具有一定独立功能的程序关于某个数据集合上的一次运行活动,是操作系统进行资源分配和调度的一个独立单位。
特点:线程的划分尺度小于进程,这使多线程程序拥有高并发性,进程在运行时各自内存 单元相互独立,线程之间内存共享,这使多线程编程可以拥有更好的性能和用户体验
注意:多线程编程对于其它程序是不友好的,占据大量 cpu 资源。
2. 创建线程的4种方式
继承Thread类,实现Runnable接口,实现Callable接口,线程池,共4中方法.
2.1 继承Thread
Thread 类本质上是实现了 Runnable 接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过Thread 类的 start()实例方法。start()方法是一个 native 方法,它将启动一个新线程,并执行 run()方法
package com.acece.ThreadReview;
/**
* @author 啊策策
*/
//继承Thread类,创建线程
public class CreateThreadFirst extends Thread{
public void run(){
System.out.println("CreateThreadFirst.run()");
}
}
//测试线程
class ThreadTest{
public static void main(String[] args) {
CreateThreadFirst createThreadFirst = new CreateThreadFirst();
createThreadFirst.start();
}
}
2.2 实现Runnable接口
- 好处是,接口可以多实现,而继承Thread只能单继承
- 本质上也是调用run()方法.
package com.acece.ThreadReview;
/**
* @author 啊策策
*/
public class CreateThreadSecond implements Runnable{
public void run() {
System.out.println("CreateThreadSecond.run()...");
}
}
//测试线程
class ThreadTest{
public static void main(String[] args) {
//2. 测试第二种方法
CreateThreadSecond createThreadSecond = new CreateThreadSecond();
Thread thread = new Thread(createThreadSecond);
thread.start();
}
}
2.3 实现Callable接口
- Java 5.0 在 java.util.concurrent 提供了一个新的创建执行线程的方式:Callable 接口
- 相对于Runnable接口,Callable接口有返回值,而且也可以抛出经检测的异常.
- Callable 需要依赖FutureTask ,FutureTask 也可以用作闭锁。
具体步骤如下
- 实现Callable接口,实现其中的call方法。
- 新建实现Callable接口的对象。
- 新建FutureTask对象,其中参数是Callable接口对应的对象。
- 新建Thread对象,其中参数是FutureTask对象。
- 执行线程:Thread对象.start方法。
- FutureTask对象.get方法等待返回值。
- 在线程结果没有被get到的时候,它会阻塞后面的内容,也可以用于闭锁。
package com.acece.ThreadReview;
import java.util.concurrent.*;
/**
* @author 啊策策
*/
//1. 创建一个类实现Callable接口,实现call()方法,
public class CreateThreadFourth implements Callable<Integer>{
//新增返回值(接口的泛型上体现),新增了可抛出异常
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
System.out.println(i);
}
return sum;
}
}
//创建一个类,测试CreateThreadThird
class CreateThreadThirdTest{
public static void main(String[] args) {
long sum = 0;
//2. 新建实现Callable接口类的对象
CreateThreadThird createThreadThird = new CreateThreadThird();
//3. 新建FutureTask对象,其中参数是Callable接口对应的对象.
FutureTask<Integer> task = new FutureTask<Integer>(createThreadThird);
//4. 新建Thread对象,其中参数是FutureTask对象.
//5. 执行线程: Thread对象.start方法
new Thread(task).start();
//6.FutureTask对象.get方法等待返回值.
try {
sum = task.get();
} catch (Exception e) {
e.printStackTrace();
}
//7.在线程结果没有被get到的时候,它会阻塞后面的内容,也可以用于闭锁.
System.out.println("总和是: " + sum);
}
}
2.4 通过线程池创建线程
线程池就是事先将多个线程对象放到一个容器中,当使用的时候就不用 new 线程而是直接去池中拿线程即可,节省了开辟子线程的时间,提高的代码执行效率。 在 JDK 的 java.util.concurrent.Executors 中提供了生成多种线程池的静态方法.

然后再调用线城池的 execute 方法, 传递new Runnable()参数重写run()方法即可.
2.4.1 常见的线程池有几种?
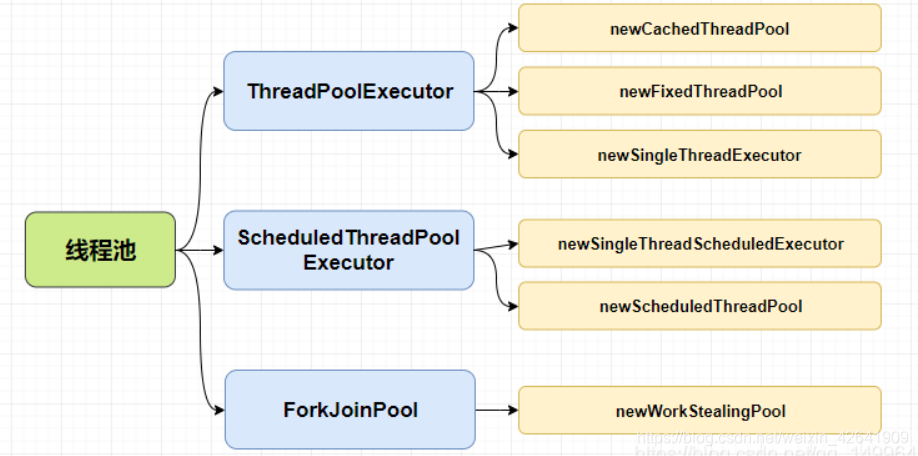
- newCachedThreadPool:创建一个可缓存的线程池,此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。
- newFixedThreadPool:创建固定大小的线程池,每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。
- newSingleThreadExecutor:创建一个单线程的线程池,此线程池保证所有任务的执行顺序 按照任务的提交顺序执行。
- newSingleThreadScheduleExecutor: 创建一个单线程执行程序,它可安排在给定延迟后运行命令或者定期执行.
- newScheduledThreadPool:创建一个线程池,它可安排在给定延迟后运行命令或者定期的执行, 线城池数量不固定.
- newWorkStealingPool: 创建一个带并行级别的线程池,并行级别决定了同一时刻最多有多少个线程在执行,如不传并行级别参数,将默认为当前系统的CPU个数.
2.5.2 线城池执行原理

- 用户提交任务
- 先判断当前线程数是否大于核心线程数
- 如果没有大于, 则直接利用核心线程执行任务
- 如果大于, 则可是往阻塞队列中放入任务.
- 如果阻塞队列没放满, 则随着核心线程完成老的任务之后, 就完成队列中的任务了.
- 如果阻塞队列放满了. 开始创建新线程执行任务
- 如果, 新线程数量+核心线程数量小于等于最大线程数, 利用新线程和核心线程分摊任务.
- 如果, 新线程数量+核心线程数量大于最大线程数, 则报错, 执行拒绝策略.
2.5.3 线程池核心参数
默认参数:
corePoolSize = 1
queueCapacity = Integer.MAX_VALUE
maxPoolSize = Integer.MAX_VALUE
keepAliveTime = 60秒
unit:秒,分钟
allowCoreThreadTimeout = false
ThreadFactory=Executors.defaultThreadFactory
rejectedExecutionHandler = AbortPolicy()
具体讲解:
- corePoolSize(核心线程数)
(1)核心线程会一直存在,即使没有任务执行;
(2)当线程数小于核心线程数的时候,即使有空闲线程,也会一直创建线程直到达到核心线程数;
(3)核心线程数代表我能够维护常用的线程开销. - maxPoolSize(最大线程数)
(1)线程池里允许存在的最大线程数量;
(2)线程池里允许存在的最大线程数量。当任务队列已满,且线程数量大于等于核心线程数时,会创建新的线程执行任务。 - queueCapacity(阻塞队列)
当核心线程都在运行,此时再有任务进来,会进入任务队列,排队等待线程执行。 - keepAliveTime(线程空闲时间)
(1)当线程空闲时间达到keepAliveTime时,线程会退出(关闭).
(2)如果allowCoreThreadTimeout=true,则线程会继续退出直到为0个。
(3)默认allowCoreThreadTimeout=false, 也就是说线程池中的线程退出, 直到=核心线程数. - unit: 和keepAliveTime配合使用, 时间单位, 可以为秒, 分钟.
- allowCoreThreadTimeout(允许核心线程超时, 默认为false, jdk1.6后加的新特性)
- ThreadFactory:
线程创建的工厂,新的线程都是由ThreadFactory创建的,系统默认使用的是
Executors.defaultThreadFactory创建的,用它创建出来的线程的优先级、组等都是一样
的,并且他都不是守护线程。我们也可以使用自定义的线程创建工厂,并对相关的值进
行修改 - rejectedExecutionHandler(任务拒绝处理器)
(1)当线程数量达到最大线程数,且任务队列已满时,会拒绝任务;
(2)调用线程池shutdown()方法后,会等待执行完线程池的任务之后,再shutdown()。如果在调用了shutdown()方法和线程池真正shutdown()之间提交任务,会拒绝新任务。
2.5.4 拒绝策略
线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列也已经排满了, 再也塞不下新任务了。这时候我们就需要拒绝策略机制合理的处理这个问题。
- ThreadPoolExecutor.AbortPolicy(系统默认): 丢弃任务并抛出RejectedExecutionException异常,让你感知到任务被拒绝了,我们可以根据业务逻辑选择重试或者放弃提交等策略
- ThreadPoolExecutor.DiscardPolicy: 也是丢弃任务,但是不抛出异常,相对而言存在一定的风险,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
- ThreadPoolExecutor.DiscardOldestPolicy: 丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程),通常是存活时间最长的任务,它也存在一定的数据丢失风险
- ThreadPoolExecutor.CallerRunsPolicy: 由调用线程处理该任务
2.5.5 使用线程池的好处?
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源, 还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控.
2.5.6 如果关闭线城池
- 刚才提过线城池核心参数, 设置时间, 会自动关闭
- shutdownNow():线程池拒接收新提交的任务,同时立马关闭线程池,线程池里的任务不再执行.
- showdown(): 线程池拒接收新提交的任务,同时等待线程池里的任务执行完毕后关闭线程池。














 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









