






概述

该篇文章主要解释Hadoop2.0三大组件HDFS+MapReduce+Yarn.其中HDFS负责存储,MapRduce负责计算,Yarn负责资源管理。
HDFS架构图
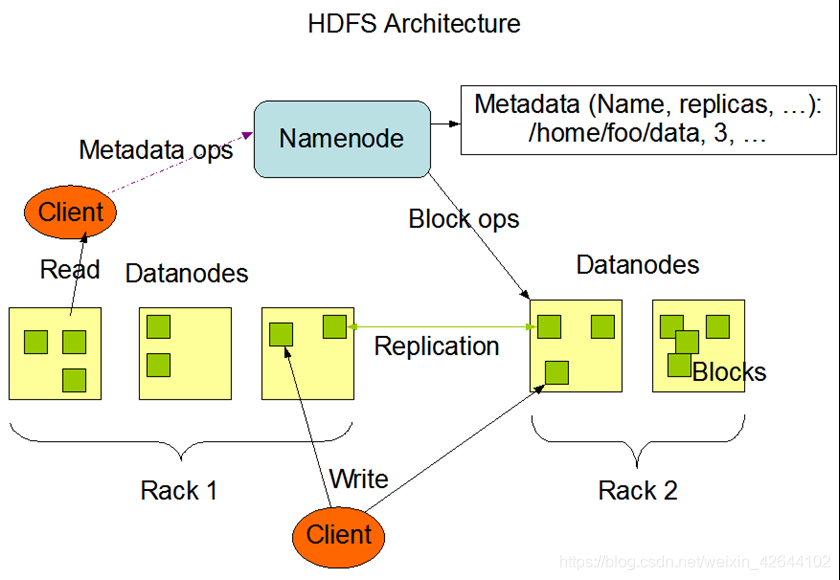
- namenode,名字节点,最主要管理HDFS的元数据信息
- datanode,数据节点,存储文件块、
- replication,文件块的副本,目的是确保数据存储的可靠性
- rack机器
- Client客户端。凡是通过指令或代码操作的一端都是客户端。
- Client的Read(从HDFS下载文件到本地)
- Client的Write(上传文件到HDFS上)
HDFS读取文件过程
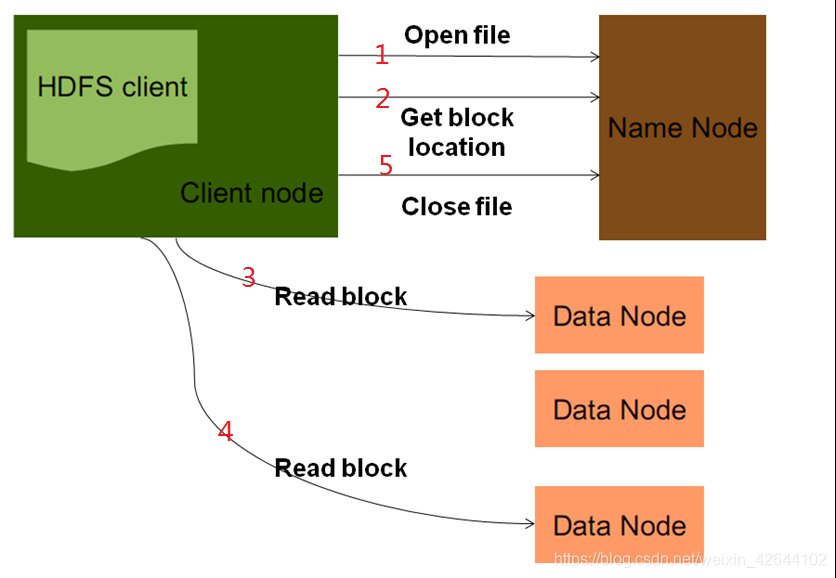
1.客户端向namenode发起Open File。目的是获取要下载的文件的输入流。
2.客户端在发起Open File的同时,还会调用GetBlockLocation.当第一步的检查通过以后namenode会将文件的块信息(元数据信息)封装到输入流,交给客户端。
3,4客户端用输入流,根据元数据信息,去指定的datanode读取文件块(按blockid顺序读取)
5.文件下载完后关闭。
BlockSender介绍
- 当用户向HDFS读取某一个文件时,客户端会根据数据所在的位置转向到具体的DataNode节点请求对应数据块的数据,此时DataNode节点会用BlockSender向该客户端发送数据;
- 当NameNode节点发现某个Block的副本不足时,它会要求某一个存储了该Block的DataNode节点向其他DataNode节点复制该Block,当然此时仍然会采用流水线的复制方式,只不过数据来源变成 了一个DataNode节点;
- HDFS开了一个调节DataNode负责均衡的工具Balancer,当它发现某一个DataNode节点存储的Block过多时,就会让这个DataNode节点转移一部分Blocks到新添加到集群的DataNode节点或者存储负载轻的DataNode节点上;
sh start-balancer.sh -t %10
百分数时磁盘使用变差率,一般调节的范围在10%~20%间。 - DataNode会定义利用BlockSender来检查一个Block的节点数据是否损坏。
HDFS写的过程
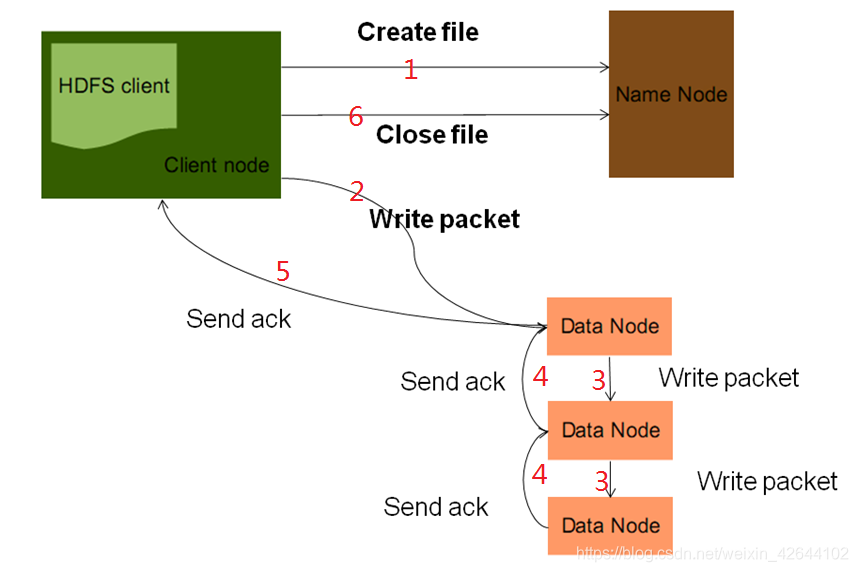
1.客户端发去CreeteFile,目的时获取HDFS文件的输出流,namenode收到请求后会检测路径的合法性,以及权限。原生Hadoop的权限管理不是很完善,工作中用的是CDH(商业版Hadoop)
如果检测通过,namenode会为这个文件生成块的元数据信息(比如:1为文件切块2分配块id3分配每个块存在那个datanode上),然后将原属信息封装到输出流中,返回给客户端。
2.3Client拿出输出流之后,采用PipeLine(数据流管道)机制做数据的上传发送,这样设计的目的在于利用每台服务的带宽,最小化推送数据的延时。
packet是一个64Kb大小的数据包,即客户端在发送文件块时,会在文件块变成一个一个的数据发送。
4.5. 每台datanode收到packet,会向上游datanode做ack确认,如果接受失败,会进行重发
6. 当一个文件上传完后,关流。
HDFS删文件流程
- 当客户端发起一个删除指令:Hadoop fs -rm /park01/.txt,这个指令会传给namenoe
- 当namenode收到指令后,做路径和权限检测,如果检测都通过,会将对应的文件信息从内存里删除,此时,文件数据并不是马上就从集群上被删除。
- datanode向namenode发送心跳时(默认时3s周期),会领取删除指令,然后从磁盘上将文件删除。
MapReduce
概述
MapReduce是一个分布式的计算框架(编程模型)。
MapReduce框架的节点组成结构
ResourceManager:任务调度者,管理多个
ResourceManager是hadoop2.0版本之后引入了yarn,有yarn来管理Hadoop.
NodeManager:任务执行者

MapReudce计算框架抽象出两个任务阶段,Map任务阶段和Reduce任务阶段。
由于集群工作过程中,需要用到RPC操作,所以MR处理的对象必须可以进行序列化/反序列操作。Hadoop利用的是avro实现的序列化和反序列化,并且在其基础上提供了便捷的API,要序列化对象必须实现相关的接口:Writable接口-WritableComparable。
partitioner分区操作
1.Hadoop默认的reduce数量是一个,即默认的分区是1个
2.假设有多个分区,Hadoop默认是用简单哈希散列算法,计算Mapper输出的key值,然后进行分区。这样能够确保同一个Key落到同一个分区。
3.有几个分区,就会有几个结果文件
4.先分区,然后再按key合并。
shuffle
其实说MR阶段最核心的也就是shuffle过程
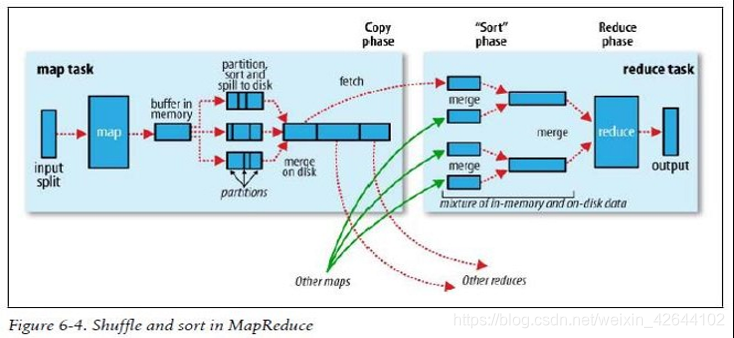
流程详解
上面的流程是整个mapreduce最全工作流程
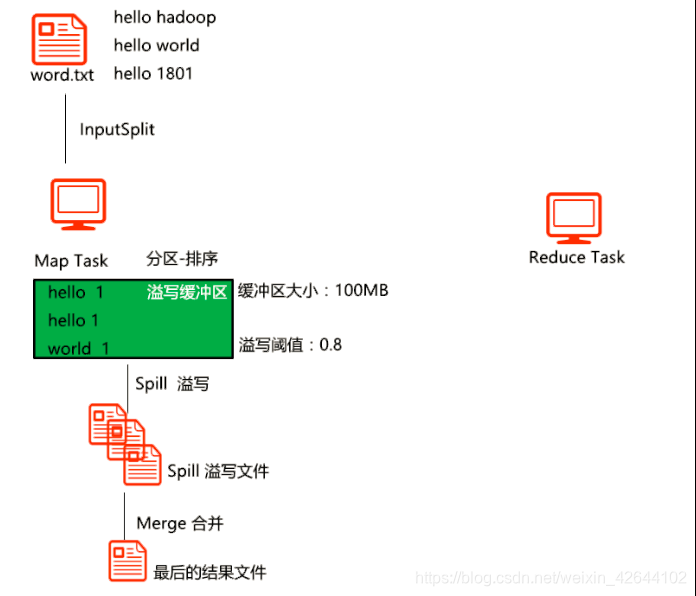
1)maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
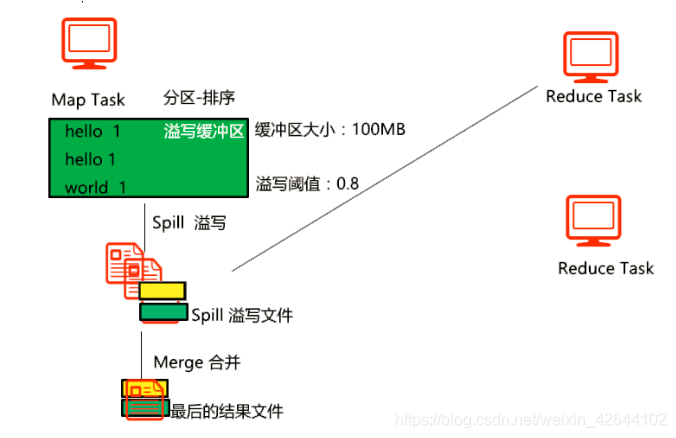
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)多个溢出文件会被合并成大的溢出文件
4)在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
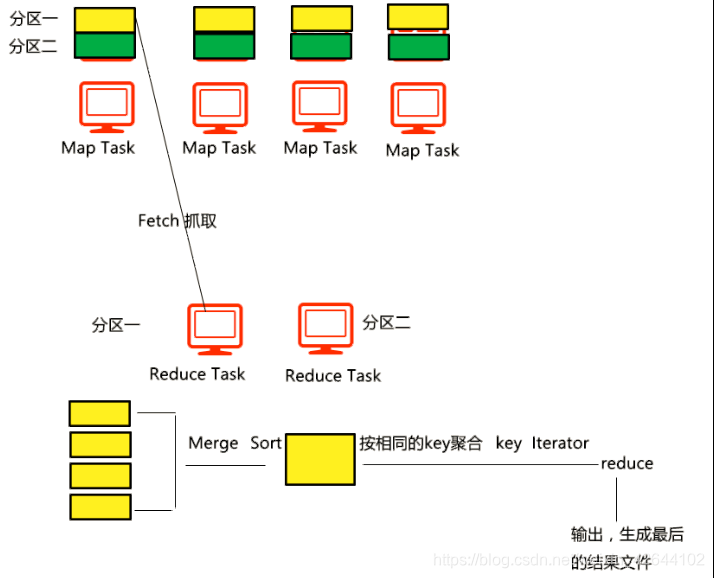
5)reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6)reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
7)合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)



Yarn
yarn是一种新的Hadoop资源管理器,它是一个通用管理原理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在资源利用率、资源同意管理和数据共享等方面带来的巨大的好处。
YARN的基本思想是将jobTracker的两个主要功能(资源管理和作业调度/监控)分离。
要了解yarn首先要了解yarn的核心思想
a.一个全局的资源管理器ResourceManager
b.ResourceManager的每个节点代理NodeManager
c.表示每个应用的ApplicationMaster
d.每一个ApplicationMaster拥有多个Container在NodeManager上运行。
yarn架构图
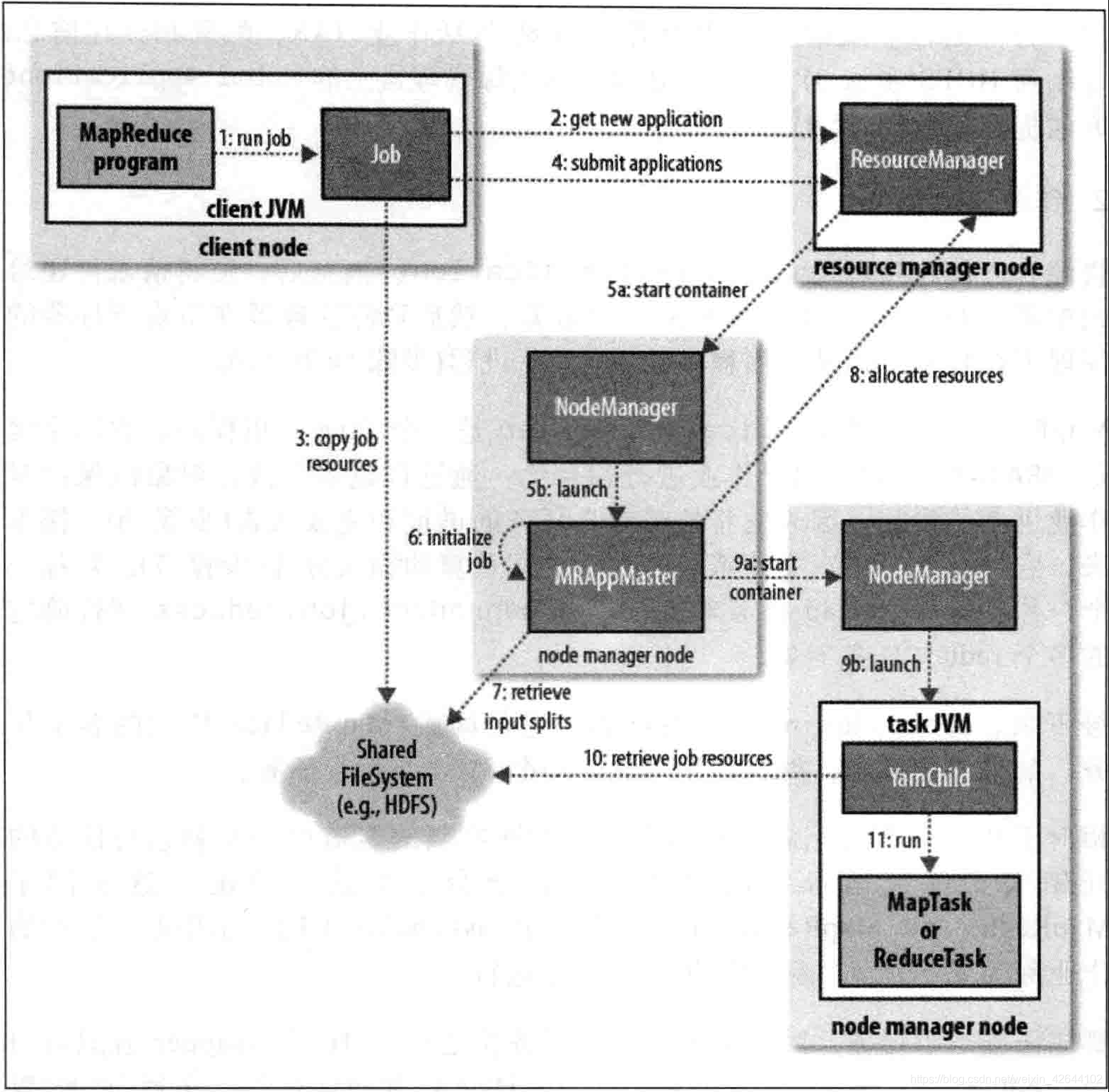
要想明白yarn架构可以通过执行MapReduce job来看Shared FileSystem(文件共享系统)以及ResouceManager、NodeManager、ApplicationMaster之间的关系。
1、 客户端通过提交MR的job.ResouceManager会会收集Job环境信息,比如输入路径、输出结果路径等信息,如果有错误就会抛出异常,并终止job的后续提交。
2、ResouceManager确认无误后会给Job返回一个new application。
3、4、job得到application的资源信息,会copy到共享文件系统,并且提交给ResourceManager。
5、 然后ResourceManager会开启一个资源容器告诉NodeManager,然后ResourceManager会开启一个资源容器通知到NodeManager,
6 、7 、8、 NodeManager询问applicationMaster这个job执行需要多少资源,ApplicationMaster初始化任务,向SharedFileSystem(文件共享系统)询问这个job所拥有的资源,并且得到的资源信息告诉nodeManager和ResouceManager。
9、10 、11、 NodeManager收到ApplicationMaster的资源信息后后开启一个子进程,根据共享文件系统给的资源执行对应的MapTask任务。














 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









