




 本文介绍了如何在Django中定义模型,进行数据库迁移,注册模型到管理页面,修改后台管理的名称和列表,添加查询功能,以及使用djangoshell进行数据操作和认证授权的基本设置。
本文介绍了如何在Django中定义模型,进行数据库迁移,注册模型到管理页面,修改后台管理的名称和列表,添加查询功能,以及使用djangoshell进行数据操作和认证授权的基本设置。
定义模型与管理页
定义模型[models.py]
模仿博客形式,模块暂定义【(标题、作者、时间、正文),(主题类型)】
from django.db import models
# Create your models here.
class topic(models.Model):
'''定义文稿的主题类型'''
text=models.CharField(max_length=200)
date_added=models.DateTimeField(auto_now_add=True)
class Meta:
verbose_name='主题类型' #数据库表的名称显示
verbose_name_plural='主题集合' #数据库表的名称集显示
def __str__(self):
return self.text
class documentes(models.Model):
'''定义文档的结构'''
topic=models.ForeignKey(topic,on_delete=models.CASCADE)
title=models.CharField(max_length=30)
date_added=models.DateTimeField(auto_now_add=True)
author=models.CharField(max_length=20)
text=models.TextField()
class Meta:
verbose_name='文档' #数据库表的名称显示
verbose_name_plural='文档集合' #数据库表的名称集显示
def __str__(self):
return self.title
对应后台显示:
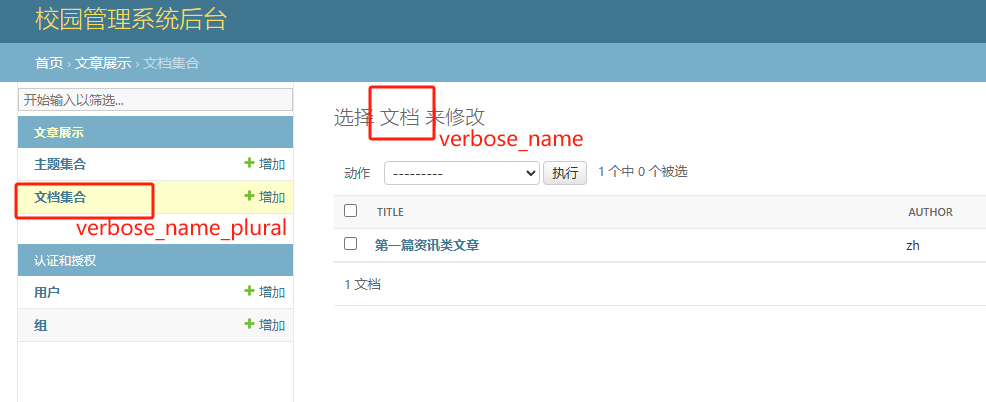
迁移模型
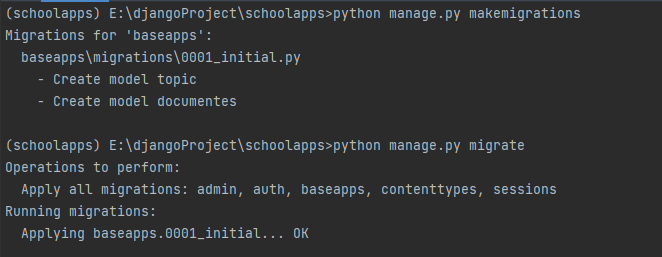
对 app_name调用makemigrations(执行Python manage.py makemigrations命令)
让django迁移项目migrate(执行Python manage.py migrate命令)
Python manage.py makemigrations
Python manage.py migrate
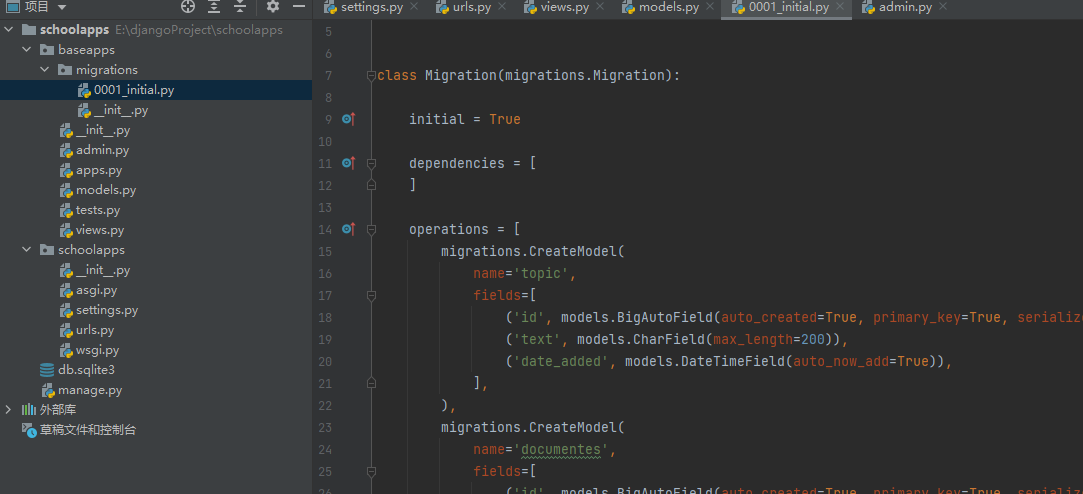
在生成的文件0001_initial.py中,可以看到数据库的修改
向管理注册模型[admin.py]
注册模型使用Admin.site.register(模型名)
from django.contrib import admin
from baseapps.models import topic,documentes
# Register your models here.
admin.site.register(topic)
admin.site.register(documentes)
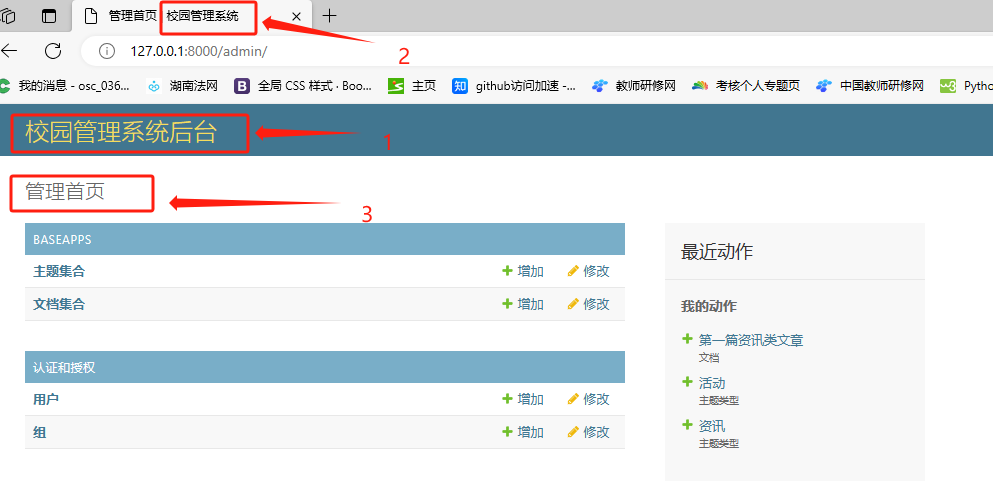
进入后台(http://127.0.0.1:8000/admin/),我们可以看到下图
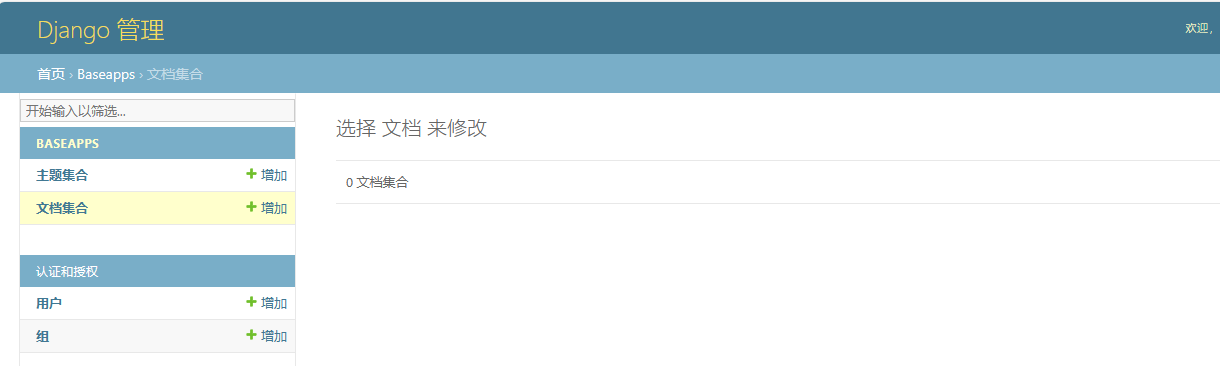
修改Django后台管理的名称
admin.site.site_header = '校园管理系统后台'
admin.site.site_title = '校园管理系统'
admin.site.index_title = '管理首页'
页面显示位置为:
定义管理列表页面
修改类docAdmin
class docAdmin(admin.ModelAdmin):
list_display = ('title','author','date_added',) # ModelAdmin列表页展示的字段名
admin.site.register(documentes,docAdmin) # docAdmin只有注册后才能使用
管理列表页变成:

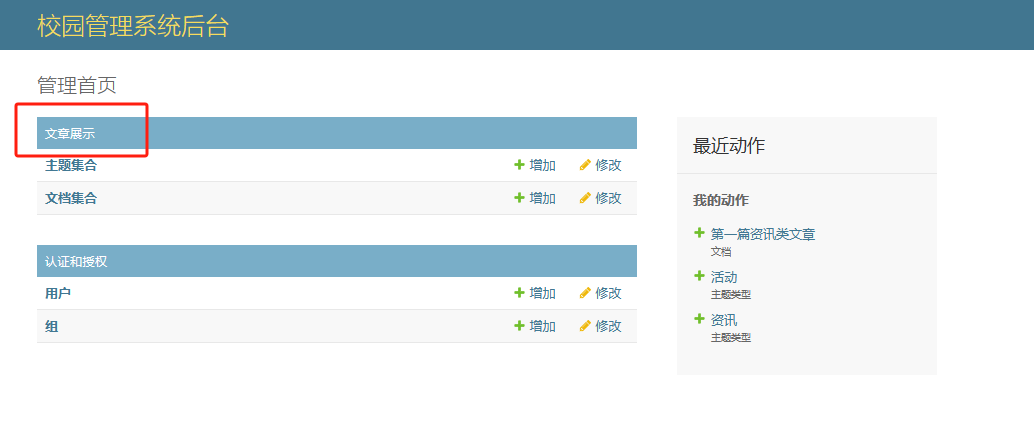
应用名称修改
- 修改apps.py文件,添加以下内容:verbose_name=u’名称’
verbose_name = u'文章展示' # 定义应用的名称
- 修改__init__.py文件,添加以下内容(也可不添加)
default_app_config = "baseapps.apps.BaseappsConfig"
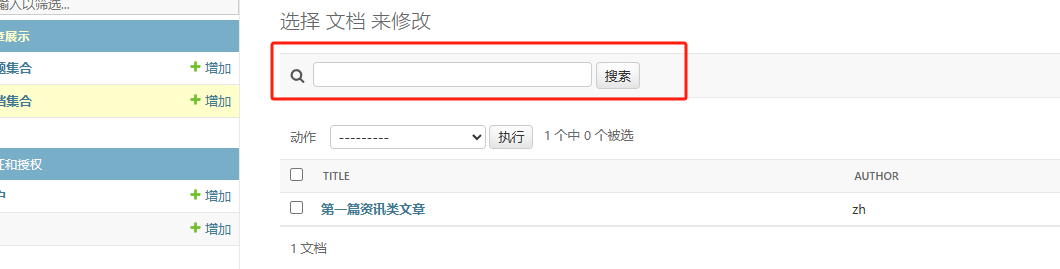
管理列表添加查询功能
在admin.py对应的类中,添加search_fields = (‘查询对应的字段名’,)
class docAdmin(admin.ModelAdmin):
list_display = ('title','author','date_added',) # ModelAdmin列表页展示的字段名
search_fields = ('title','author',) #添加“标题”与“作者”的查询
django shell
输入一些模拟数据,查看效果
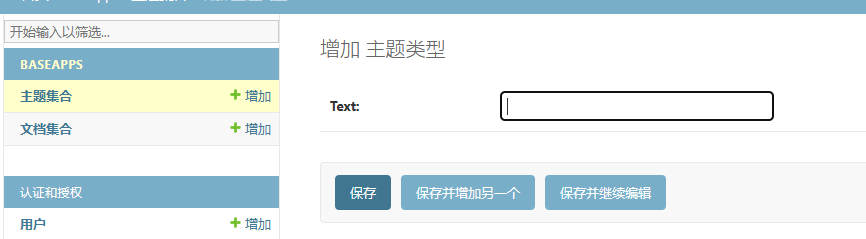
输入两条数据条目后,我们得到

交互式shell会话
python manage.py shell启动一个python解释器,通过它我们导入模型,使用object.all()来获取所有实例,返回的查询集(queryset)。
(schoolapps) E:\djangoProject\schoolapps>python manage.py shell
Python 3.11.0 (main, Oct 24 2022, 18:26:48) [MSC v.1933 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from baseapps.models import topic
>>> topic.objects.all()
<QuerySet [<topic: 资讯>, <topic: 活动>]>
>>> from baseapps.models import documentes
>>> documentes.objects.all()
<QuerySet [<documentes: 开放、选择、信任>, <documentes: 与创新者同行>]>
>>> n=topic.objects.get(id=1)
>>> n.text
'资讯'
>>> n.date_added
datetime.datetime(2023, 10, 19, 4, 15, 5, 840186, tzinfo=datetime.timezone.utc)
>>>
附:每次修改模型后,需要重启shell,才能看到修改的效果,退出快捷键“ctrl+Z”
认证和授权
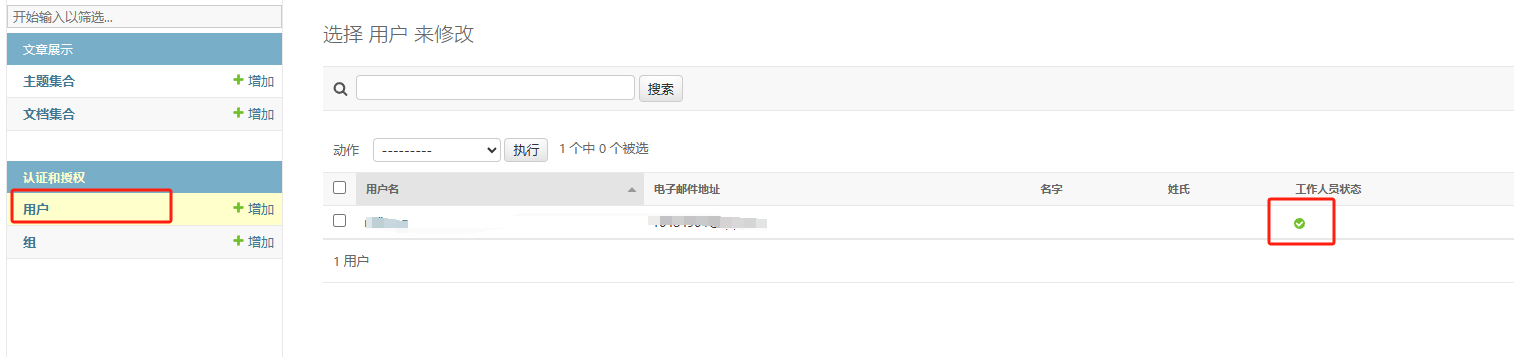
后台设置用户与组的权限,用户必须设置为工作人员状态才能登录

















 2955
2955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









