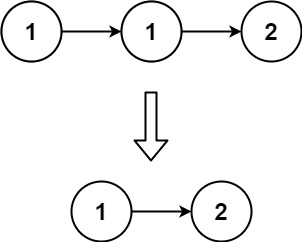
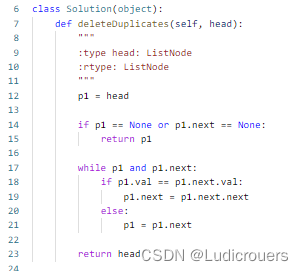
【链表Linked List】力扣-83 删除排序链表中的重复元素







于 2023-12-03 12:55:43 首次发布
 433
162
433
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言