






 Transformer是一种深度学习模型,以自注意力机制为核心,处理序列数据。它包含多头注意力、前馈神经网络等组件,用于并行计算,特别适合长序列任务。Transformer在NLP和多种领域表现出色,如机器翻译和计算机视觉。
Transformer是一种深度学习模型,以自注意力机制为核心,处理序列数据。它包含多头注意力、前馈神经网络等组件,用于并行计算,特别适合长序列任务。Transformer在NLP和多种领域表现出色,如机器翻译和计算机视觉。
Transformer 架构是一种用于序列数据处理的深度学习模型架构,由Ashish Vaswani等人于2017年提出。它在机器翻译任务中取得了显著的成功,并且成为了自然语言处理领域中一种重要的模型结构。Transformer 的设计核心是自注意力机制(self-attention mechanism)。
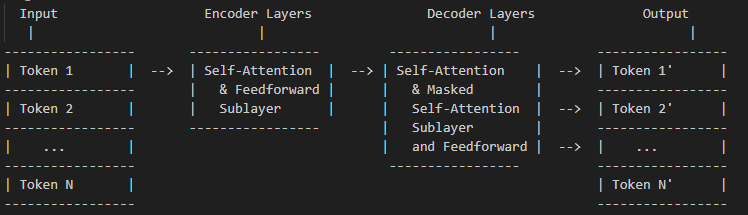
Transformer 架构的主要组成部分:
自注意力机制(Self-Attention Mechanism):自注意力机制允许模型在处理输入序列时将不同位置的信息赋予不同的权重。对于每个输入位置,自注意力机制通过计算与其他所有位置的注意力权重来聚合信息。这使得模型能够同时关注序列中的各个部分。

多头注意力(Multi-Head Attention):Transformer 模型包含多个自注意力头,每个头都学习不同的权重,从而提供多个子空间的表示。多头注意力的引入有助于模型更好地捕捉不同方面的关系和模式。
前馈神经网络(Feedforward Neural Network):在每个注意力层之后,都有一个前馈神经网络。它负责对注意力层的输出进行非线性变换。
残差连接(Residual Connections):在每个子层的输入和输出之间引入残差连接。这有助于防止训练中的梯度消失或梯度爆炸问题,并使得模型更容易训练。
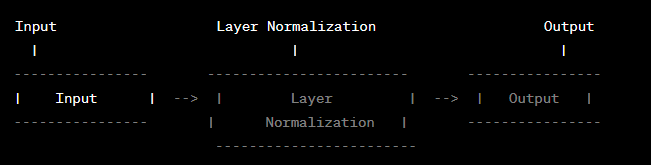
层归一化(Layer Normalization):在每个子层的输出上进行层归一化,以确保每个子层的输入保持一定的分布特性,提高模型训练的稳定性。
位置编码(Positional Encoding):Transformer 模型没有内建的位置信息。为了使模型能够理解输入序列中元素的顺序,位置编码被添加到输入的嵌入表示中,以提供关于位置的信息。
编码器和解码器结构:Transformer 架构通常用于序列到序列的任务,如机器翻译。在这种情况下,模型分为编码器和解码器两部分,每部分包含多个层。
Transformer 的优势在于其能够并行计算,使得训练速度更快,尤其适用于处理长序列的任务。由于其卓越的性能和灵活性,Transformer 不仅在自然语言处理领域得到广泛应用,还被用于计算机视觉、语音处理等多个领域。【智答专家】问答知识分享。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









