






一、前言
上一篇博客讲到Linux的文本处理指令grep,其作用是按照一定的规则对于文件或文件夹进行筛选,本篇博客来讲一下文本处理指令 —— awk。
二、含义及用法
awk实际上是按照一定的规则对文本的每一行进行处理,下面来举一个例子:
首先来看文件的内容:
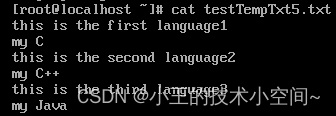
目前要实现的功能是:
提取每一行最后一个前缀为language的单词,并将其和下一行的计算机语言的单词合并并输出。
awk指令是:
cat testTempTxt5.txt | awk ‘/^this/{value=$5;next;}{print value “-” $0}’
cat testTempTxt5.txt | awk '/^this/{value=$5;next;}{print value "-" $0}'
首先看一下执行结果:

如上图所示,指令成功地实现了需求,下面的流程图解释了指令的执行步骤:
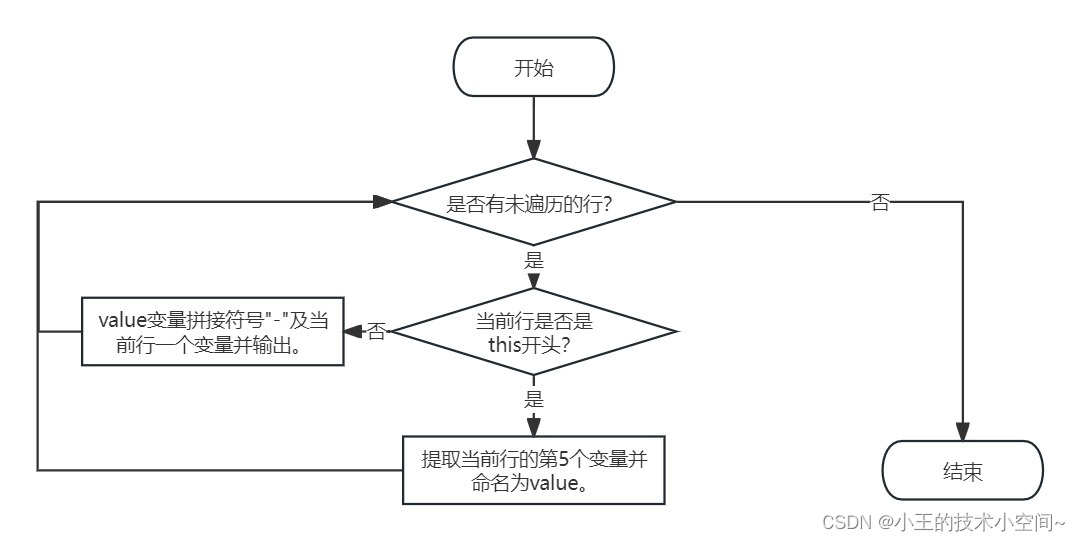
可以看出 指令的执行步骤类似于if else的作用。
二、整体模式
用法如下:
awk ‘BEGIN {commands} pattern {commands} END {commands}’
用法举例:
先看一下文本的内容:
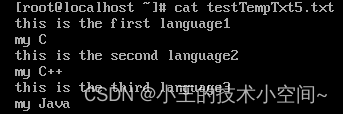
目前要实现的功能是:
文本输出之前打印BEGIN BLOCK关键字,文本结束打印END BLOCK关键字。
awk指令是:
cat testTempTxt5.txt | awk ‘BEGIN {print “BEGIN BLOCK”} {print $0} END{print “END BLOCK”}’
cat testTempTxt5.txt | awk ‘BEGIN {print "BEGIN BLOCK"} {print $0} END{print "END BLOCK"}’
首先看一下执行结果:

如上图所示,指令成功地实现了在文本之前打印BEGIN BLOCK 在本文之后打印 END BLOCK。
三、常用参数
NR > 5 —— 从第五行开始
$0 —— 整行的内容
OFS=“-” —— 输出内容以 - 为分隔符‘
用法示例:
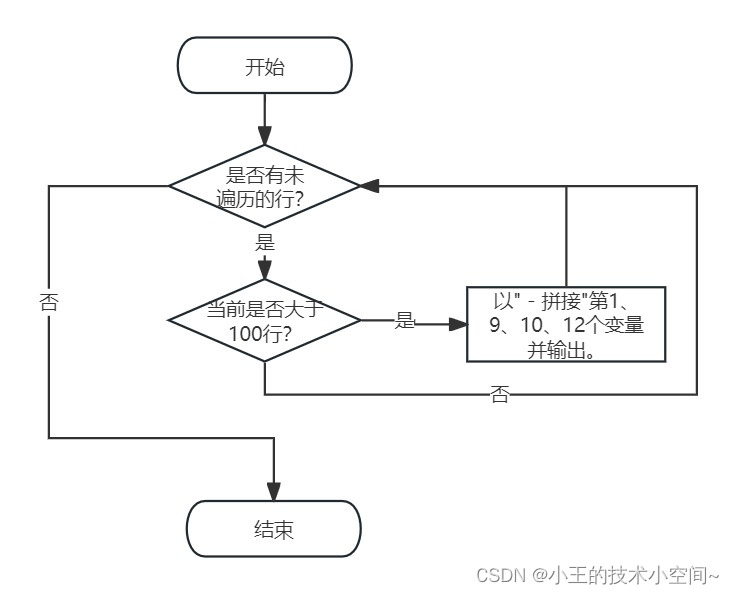
top -n 1 -b | awk ‘NR > 100’ | awk ‘{print $1, $9, $10, $12} OFS=" - "’
top -n 1 -b | awk 'NR > 100' | awk '{print $1, $9, $10, $12} OFS=" - "'
含义:
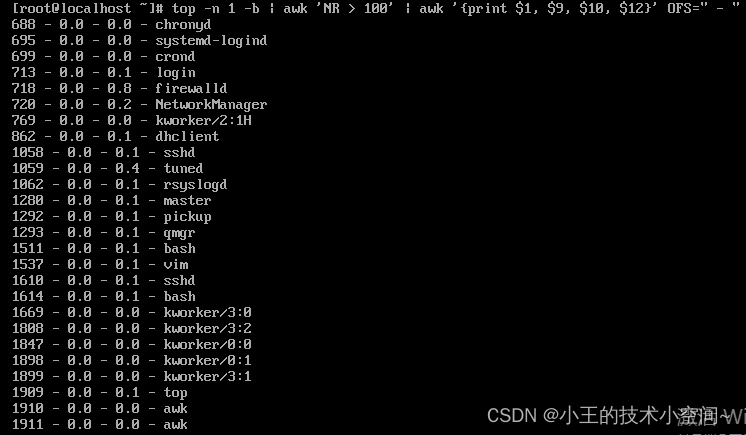
从top -n 1 -b输出的第101行开始,提取第1、9、10、12个变量,用" - "拼接,并打印到终端。
以下是指令的输出结果:
处理流程如下图所示:















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









