






前言
你好,我是一个前端切图仔。这是一篇切图仔学后端的学习笔记,今天我们盘的是缓存。本文实例搭建依赖的是 Node.js 。
缓存(
cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器。
而在广义意义上,同样是存储的结构,若前者比后者的访问速率快一个量级,则称前者为后者的缓存。比如cache比内存快,内存取值比硬盘快等。
缓存简介
一般缓存都有如下特征:
- 命中率:命中率=正确结果数/请求缓存次数。它是衡量缓存有效性的重要指标,命中率越高,表名缓存的使用率越高
- 最大空间:可以存放元素的最大数量,若超过这个值,那么会触发清空策略
- 清空策略:
FIFO(first in first out)先进先出策略,最先进入缓存的优先被清除掉。LFU(less frequently used)最少使用策略,无论是否过期,清除最少使用的元素LRU(least recently used)最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。
客户端缓存
打开 Chrome 的 Network 面板,我们可以看到如下信息:
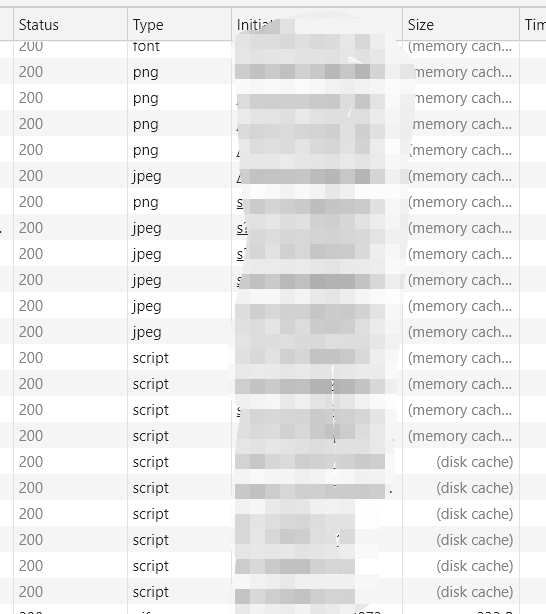
看到 Size 栏,我们可以看到这些资源部分是来自memory cache亦或是disk cache,还有 status 栏里面没有显示出来的 304 状态码。下面分别介绍这些。
加载资源顺序一般如下:
- 先去内存看,如果有,加载
- 内存没有,去硬盘看,如果有,加载
- 硬盘没有,则发起网络请求
- 加载到的资源根据规则缓存到硬盘和内存
memory cache & disk cache
-
内存缓存(
from memory cache):内存缓存具有两个特点,分别是快速读取和时效性: -
快速读取:内存缓存会将编译解析后的文件,直接存入该进程的内存中,占据该进程一定的内存资源,以方便下次运行使用时的快速读取。
-
时效性:一旦该进程关闭,则该进程的内存则会清空。
-
硬盘缓存(
from disk cache):硬盘缓存则是直接将缓存写入硬盘文件中,读取缓存需要对该缓存存放的硬盘文件进行I/O操作,然后重新解析该缓存内容,读取复杂,速度比内存缓存慢。
在浏览器中,浏览器会在js和图片等文件解析执行后直接存入内存缓存中,那么当刷新页面时只需直接从内存缓存中读取(from memory cache);而css文件则会存入硬盘文件中,所以每次渲染页面都需要从硬盘读取缓存(from disk cache)。
强缓存&协商缓存
在网络请求中,缓存一般分为强缓存和协商缓存,下面分别介绍:
强缓存
强制缓存就是向浏览器缓存查找该请求结果,并根据该结果的缓存规则来决定是否使用该缓存结果的过程,强制缓存的情况主要有三种(暂不分析协商缓存过程),如下:
-
不存在该缓存结果和缓存标识,强制缓存失效,则直接向服务器发起请求
-
存在该缓存结果和缓存标识,但该结果已失效,强制缓存失效,则使用协商缓存
-
存在该缓存结果和缓存标识,且该结果尚未失效,强制缓存生效,直接返回该结果
那么强制缓存的缓存规则是什么?
当浏览器向服务器发起请求时,服务器会将缓存规则放入HTTP响应报文的HTTP头中和请求结果一起返回给浏览器,控制强制缓存的字段分别是Expires和Cache-Control,其中Cache-Control优先级比Expires高。
Expires
Expires 是HTTP/1.0控制网页缓存的字段,其值为服务器返回该请求结果缓存的到期时间,即再次发起该请求时,如果客户端的时间小于Expires的值时,直接使用缓存结果。
Expires是HTTP/1.0的字段,但是现在浏览器默认使用的是HTTP/1.1,那么在HTTP/1.1中网页缓存还是否由Expires控制?
到了HTTP/1.1,Expire已经被Cache-Control替代,原因在于Expires控制缓存的原理是使用客户端的时间与服务端返回的时间做对比,那么如果客户端与服务端的时间因为某些原因(例如时区不同;客户端和服务端有一方的时间不准确)发生误差,那么强制缓存则会直接失效,这样的话强制缓存的存在则毫无意义,那么Cache-Control又是如何控制的呢?
Cache-Control
在 HTTP/1.1 中,Cache-Control是最重要的规则,主要用于控制网页缓存,主要取值为:
-
public:所有内容都将被缓存(客户端和代理服务器都可缓存) -
private:所有内容只有客户端可以缓存,Cache-Control的默认取值 -
no-cache:客户端缓存内容,但是是否使用缓存则需要经过协商缓存来验证决定 -
no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存 -
max-age=xxx:缓存内容将在xxx秒后失效
协商缓存
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程,主要有以下两种情况:
-
协商缓存生效,返回
304 -
协商缓存失效,返回
200和请求结果结果
同样,协商缓存的标识也是在响应报文的HTTP头中和请求结果一起返回给浏览器的,控制协商缓存的字段分别有:Last-Modified / If-Modified-Since和Etag / If-None-Match,其中Etag / If-None-Match的优先级比Last-Modified / If-Modified-Since高。
Last-Modified / If-Modified-Since
Last-Modified是服务器响应请求时,返回该资源文件在服务器最后被修改的时间,如下。
If-Modified-Since则是客户端再次发起该请求时,携带上次请求返回的Last-Modified值,通过此字段值告诉服务器该资源上次请求返回的最后被修改时间。服务器收到该请求,发现请求头含有If-Modified-Since字段,则会根据If-Modified-Since的字段值与该资源在服务器的最后被修改时间做对比,若服务器的资源最后被修改时间大于If-Modified-Since的字段值,则重新返回资源,状态码为200;否则则返回304,代表资源无更新,可继续使用缓存文件。
Etag / If-None-Match
Etag是服务器响应请求时,返回当前资源文件的一个唯一标识
If-None-Match是客户端再次发起该请求时,携带上次请求返回的唯一标识Etag值,通过此字段值告诉服务器该资源上次请求返回的唯一标识值。服务器收到该请求后,发现该请求头中含有If-None-Match,则会根据If-None-Match的字段值与该资源在服务器的Etag值做对比,一致则返回304,代表资源无更新,继续使用缓存文件;不一致则重新返回资源文件,状态码为200。
注:Etag / If-None-Match优先级高于Last-Modified / If-Modified-Since,同时存在则只有Etag / If-None-Match生效。
小结
强制缓存优先于协商缓存进行,若强制缓存(Expires和Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since和Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回304,继续使用缓存。
Node实现
有了上面的理论知识支持之后,我们可以尝试用Node.js来添加缓存的支持。缓存配置文件如下:
ps:
source为资源信息,部分代码已省略
const cache = {
maxAge:3600,
expires:true,
cacheControl: true,
lastModified: true,
etag: true
}
module.exports = cache
接下来实现缓存判断的中间件逻辑
function refreshRes(stats, res) {
const {maxAge, expires, cacheControl, lastModified, etag} = cache;
if(expires) {
res.setHeader('Expires', (new Date(Date.now() + maxAge*1000)).toUTCString());
}
if(cacheControl) {
res.setHeader('Cache-Control', `public, max-age=${maxAge}`);
}
if(lastModified) {
res.setHeader('Last-Modified', stats.mtime.toUTCString());
}
if(etag) {
res.setHeader('ETag', generateETag(stats));
}
}
function isFresh(source){
refresh(source,res)
const lastModified = req.headers['if-modified-since'];
const etag = req.headers['if-none-match'];
if(!lastModified && !etag) {
return false;
}
if(lastModified && lastModified !== res.getHeader('Last-Modified')) {
return false;
}
if(etag && etag !== res.getHeader('ETag')) {
return false;
}
return true;
}
module.exports = isFresh
在返回资源时判断:
if(isFresh(resource, req, res)) {
res.statusCode = 304;
res.end();
return;
}
服务端缓存
在一些比较大流量的网站中,离不开缓存层。为的也是减轻数据库层面的负担,常用的缓存系统有 Memcached、Redis。我们先来手写一个简单的缓存类,来看看这类型的缓存是咋的一回事。
Cache.js
一开始我们希望Cache有如下特征:
- 键值对存储
- 增删查方法
- 过期机制
新建一个Cache.js,如下编码:
class Cache {
constructor(maxAge = 1000 * 60 * 30,max = 10) {
this.maxAge = maxAge
//保存缓存的 Map
this.cache = new Map()
//过期时间 Map
this.ttl = new Map()
this.max = max
}
getCache(key) {
let ttl = this.ttl.get(key)
if ((+new Date()) - ttl >= this.maxAge) {
//过期了则删除
this.deleteCache(key)
return null
} else {
return this.cache.get(key)
}
}
setCache(key, value) {
this.cache.set(key) = value
this.ttl.set(key) = +new Date()
}
deleteCache(key) {
this.cache.delete(key)
this.ttl.delete(key)
}
}
module.exports = Cache
- 写出缓存时同时写入当前时间戳
- 拿缓存时对比时间戳,过期则删除,返回空
LRU缓存淘汰
下面加入缓存淘汰机制,以当前用的最多的LRU机制为例。(貌似面试也很喜欢让手写这个)
-
set流程:
- 已经存在,提升
- 达到max,淘汰最后一个
- 更新过期时间
-
get流程:
- 不存在则返回空
- 过期则删除
- 提升数据,返回
-
delete流程:
- 不存在则直接返回
- 依次让key后面的元素覆盖
- 删除ttl的key
class Cache {
constructor(maxAge = 1000 * 60 * 30, max = 10) {
this.maxAge = maxAge
//保存缓存的object
this.cache = [];
this.max = max
//过期时间object
this.ttl = new Map()
}
getCache(key) {
let index = this.findIndex(key);
if (index === -1) {
return undefined;
}
if ((+new Date()) - this.ttl.get(key) >= this.maxAge) {
this.deleteCache(key)
return undefined
} else {
// 删除此元素后插入到数组第一项
let value = this.cache[index].value;
this.cache.splice(index, 1);
this.cache.unshift({
key,
value,
});
return value;
}
}
setCache(key, value) {
let index = this.findIndex(key);
// 已经存在,提升
if (index > -1) {
this.cache.splice(index, 1);
} else if (this.cache.length >= this.capacity) {
// 若已经到达最大限制,先淘汰一个最久没有使用的
this.cache.pop();
}
this.cache.unshift({
key,
value
});
this.ttl[key] = +new Date()
}
deleteCache(key) {
let index = this.cache.findIndex(key)
if(index == -1)return
//依次提升
for (let i = index; i < this.cache.length - 1; i++) {
this.cache[i] = this.cache[i + 1]
}
delete this.ttl[key]
}
findIndex(key) {
return this.cache.findIndex(item => key === item.key)
}
}
module.exports = Cache
Memcached
简介
随着互联网的发展,传统的关系型数据库开始出现瓶颈。例如:
- 对数据库的高并发读写,处理过程复杂耗时。
- 海量数据处理,对于关系型数据库查询海量数据效率会很低
Memcached是高性能的分布式缓存服务器,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度。
简单实例
在本地安装好Memcached后,安装node依赖:npm install memcached --save。再次简单封装一个Cache类如下:
const Memcached = require('memcached');
const memcached = new Memcached('localhost:11211');
class Cache {
get(key) {
return new Promise((resolve, reject) => {
memcached.get(key, (err, data) => {
if (err) {
reject(err)
} else {
resolve(data)
}
})
})
}
set(key, value, lifetime) {
return new Promise((resolve, reject) => {
memcached.set(key, value, lifetime, (err, data) => {
if (err) {
reject(err)
} else {
resolve(data)
}
})
})
}
}
const cache = new Cache()
async function test() {
var json = {
name: 'abc',
age: 12,
sa: 16
}
await cache.set('t', JSON.stringify(json), 0)
const res = await cache.get('t')
console.log(res)
}
test()
当一个请求过来时,比如要获取首页的文章,可先从缓存中取,若取不到则读取数据库然后加入缓存,下次来时可以直接从缓存返回。
ps:MySQL数据库操作:为Node.js加一个DB类
async getSubject(){
let sql = `SELECT * FROM subject`
let key = md5(sql)
let data = await cache.get(key)
let result
if(!data){
result = await db.table('subject').select()
cache.set(key,JSON.stringify(result))
}
return result
}
分布式布置方案
当1台不能满足我们的需求,需要布置多台时,怎么保证一个数据保存到哪台服务器上呢?有两种方案,一种是普通Hash分布,另一种是一致性Hash分布。下面分别介绍
普通Hash分布
普通Hash函数大概如下:
function hash($key) {
let md5Str = md5($key).substring(0, 8)
let seed = 31
let hash = 0
for (let i = 0; i < 8; i++) {
hash = hash * seed + md5Str[i].charCodeAt()
i++
}
return hash & 0x7FFFFFFF
}
- 用
md5把key处理成一个32位的字符串,取前8位 - 用
hash处理成一个整数返回
假设配置两台服务器,则可以如下映射:
let servers = [{
host: '192.168.1.12',
port: 6397
}, {
host: '192.168.1.20',
port: 6397
}]
let key = 'key'
let value = 'value'
let config = servers[hash(key) % 2]
const memcached = new Memcached(config)
一致性Hash分布
在服务器数量不发生变化时,普通Hash可以很好地运作。但是当服务器数量发生改变时,增加一台服务器,同一个key经过hash之后会跟增加之前的结果不一样,这会导致数据丢失。为了把丢失的数据减少到最少,可以使用一致性Hash算法。具体可参考一致性Hash原理与实现















 2126
2126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









