









 本文介绍了基于pytest的接口自动化框架搭建过程,包括分层思想、公共方法封装(如requests、数据库操作、加密解密)、测试用例管理、日志记录、配置文件和测试报告生成。通过实例展示了如何组织代码结构,提高代码复用性和测试效率。
本文介绍了基于pytest的接口自动化框架搭建过程,包括分层思想、公共方法封装(如requests、数据库操作、加密解密)、测试用例管理、日志记录、配置文件和测试报告生成。通过实例展示了如何组织代码结构,提高代码复用性和测试效率。
文章目录
源码
源码链接在文章最后面!!!
前言
之前看过也接触过很多自动化的框架,但凡成形的框架无论是unittest还是pytest无一例外都使用分层模式,所以我结合工作项目的实际应用和以往的经验,我对接口自动化框架的结构组成和模式优劣做了一次总结,通过不同分层、不同模块进行一次全面详细的拆解分析,希望有助于大家的理解和应用。
概念
什么是分层思想?
为了提高脚本的维护性,稳定性,可读性、复用性,等等,我们就要把自动化脚本分层。
脚本分层的原理就是让不同的层去做不同类型的事情,专业的人做专业的事,让我们的代码结构更清晰,还有很多代码可以复用,很多东西都是重复使用的,所以我们会把代码分层。分层就像蛋糕一样由小到大,封装的东西可能会涉及到二次封装,三次封装甚至四次封装。
如何进行分层?
分层的方法有很多种,根据不同公司,不同产品会有不同的分层,但最常用的还是以下的分层结构:
公共层,接口层,数据层,配置层,用例层,日志层,报告层
公共层:
在做接口自动化的时候会涉及到很多接口,而且会发现这些接口其实都有很多共同的属性,比如:相同业务下的host,method,data,headers和params,还有后面涉及到对文件(yml,txt,excel等)的读取,对数据库的(增删改查)等操作。为了方便我们会将这些公共的方法封装处理,方便排查定位问题和调用,应对需求变化的属性比较灵活,提高维护代码的效率
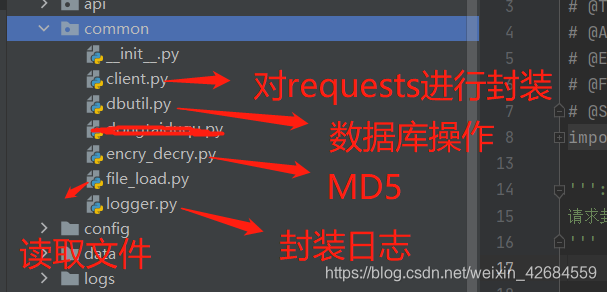
接口层:
由于测试中接口比较多,为了提高易用性和效率,在这里我把每个接口都做了一个封装,然后再根据不同的业务进行划分存放,最后都存放在了api这个大的封装包里,这样做有以下几点优势:
1、方便对状态码,返回值和提示信息分别做断言
2、方便定位问题
3、方便其他接口的调用
4、方便业务的区分
数据层:
在测试活动中我们会经常修改测试数据来覆盖不同的测试需求(长度,类型,为空,重复,敏感,特殊,NULL等),
为了方便维护测试数据我们把数据单独抽离出来,采用yml或者Excel的格式单独存在一个文件里,这样形成数据池层。然后通过公共层封装的读取文件的方法进行读取调用,方便我们维护测试数据
配置层:
配置层主要是用来封装数据库和环境入口的
接口测试肯定会涉及到数据库的读写操作,这里主要是连接数据库(线上数据库和测试数据库)和记录不同的测试环境(URL)等
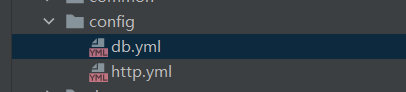
db.yml
test:
host: ""
port: 3306
user: "root"
pwd: ""
dev:
host:
port:
user:
pwd:
http.yml
baidu: www.baidu.com:7000
huohu: http://www.xxx.com:7002
yml基本语法规则:
大小写敏感;
使用缩进表示层级关系;
缩进时不允许使用Tab键,只允许使用空格;
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可;
#表示注释,从这个字符一直到行尾,都会被解析器忽略,这个和python的注释一样。
yaml支持的数据结构有三种:
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
纯量(scalars):单个的、不可再分的值。字符串、布尔值、整数、浮点数、Null、时间、日期
用例层:
顾名思义,用例层封装测试用例,其中包括:测试对象行为 和 断言
可以理解成每个接口的用例,因为前面我把每个接口封装在了api里,所以这里只需要调用那个接口,对接口的返回值做断言即可
自动化测试测试用例三大要素:前置条件、操作步骤、断言
测试用例的独立性:
用例之间没有必然业务联系,其他用例不能影响当前用例的运行。
若用例之间存在联系,不知道用例执行会在哪里失败,没办法保证接下来的用例一定是从自己想要的接口开始
测试用例分层关键在于独立测试用例数据
在测试过程中,对于测试用例,需要做到独立测试数据:
比如账号和密码发生了修改,这时我们代码中的数据,也要发生修改;
或者是环境切换 / 多环境共用的时候,例如测试dev环境、测试UAT环境和生产环境,测试数据不一致。
还有一些全局共享的网址、数据,也可以独立出来。
所以,独立测试数据,可以减少测试的工作量,测试数据发生修改,就不需要在测试用例中逐个修改测试数据。
测试数据的存储,可以用 csv / excel 表格的方式存储,可以用 python 文件方式存储,也可以用 yaml 文件存储,这些我都封装在data数据层了,可以通过调用读取文件的方法读取,然后返回给用例做断言
日志层:
用来记录执行生成的操作日志,以便排查问题
报告层:
存放allure报告HTML
生成HTML报告命令:
allure generate .\reports\xxx -o ./reports/html --clean
pytest框架结构
pytest框架采用了分层思想,对接口请求、api、数据等封装调用
下面我就由面到点的方式做一个解析吧
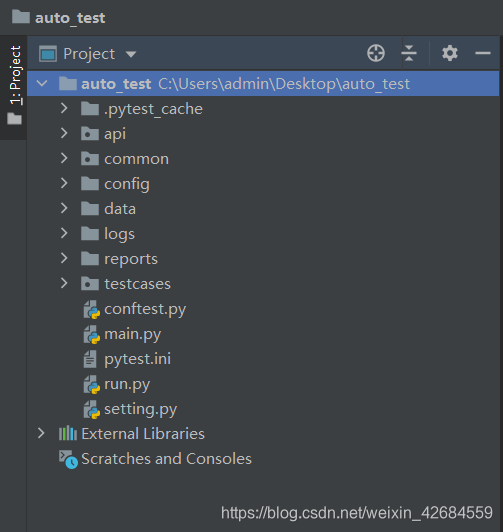
框架的大体分层结构如下:
【api】:封装测试过程中会用到的接口(即:存放单接口的定义脚本)
【common】:存放基础的公共方法,比如requests的封装、文件读取、日志处理、数据库操作、加密等
【config】:存放配置文件,比如数据库配置信息、接口域名管理(我直接写在yml文件里了,方便读取调用)
【data】: 存放allure的测试报告
【logs】:封装记录log方法,分为:debug、info、warning、error、critical
【reports】:存放allure的测试报告
【testcases】:存放测试用例脚本,测试用例是通过调用各个单接口来组装业务测试用 例脚本
【run.py】:整个项目的执行入口
【conftest.py】: 存放pytest的公共fixture以及钩子函数的
【pytest.ini】: pytest执行的相关配置
封装公共方法(common)
封装requests常见方法
首先对 Requests 库下一些常见的请求方法及请求参数进行了简单封装,以便调用起来更加方便
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/7/15 2:45 下午
# @File : client.py
# @Software: PyCharm
import jsonpath
import requests
from common.encry_decry import md5
''':cvar
请求封装的对象
'''
class RequestsClient():
# buyer_token = None
def __init__(self):
# 创建logger日志对象
self.logger = GetLogger.get_logger()
# 创建session对象
self.session = requests.session()
self.host = None
self.url = None
self.method = None
self.headers = None
self.params = None
self.data = None
self.json = None
self.files = None
def send(self, **kwargs):
''':cvar
发起请求
'''
if kwargs.get('url') is None:
kwargs['url'] = self.url
if kwargs.get('method') == None:
kwargs['method'] = self.method
if kwargs.get('headers') == None:
kwargs['headers'] = self.headers
if kwargs.get('params') == None:
kwargs['params'] = self.params
if kwargs.get('data') == None:
kwargs['data'] = self.data
if kwargs.get('json') == None:
kwargs['json'] = self.json
if kwargs.get('files') == None:
kwargs['files'] = self.files
resp = self.session.request(**kwargs)
return resp
if __name__ == '__main__':
# 卖家登陆
url = ''
params = {
'username': '',
# md5加密的方法
'password': md5(''),
# 验证码
'captcha': '1512',
# 用户ID
'uuid': '1234567890'
}
kargs = {
'url': url,
'method': 'get',
'params': params
}
client = RequestsClient()
resp = client.send(**kargs)
print(f'响应状态码是{resp.status_code}')
print(f'响应内容是{resp.text}')
封装加/解密方法
涉及到密码的地方,可能会有MD5的加密,MD5值不能够被反解密,只能够判断,主要用于与数据库中的MD5值比较,防止密码被盗
所以在这里对MD5的加密也单独做了一个封装,以便其他地方涉及到了可以进行调用
代码如下:
import hashlib
''':cvar
加密解密
'''
def md5(str):
return hashlib.md5(str.encode('UTF-8')).hexdigest()
以下部分只做了解:除了使用md5对密码加密之外,还延伸了:对称加密解密和非对称加密解密
import base64
import hashlib
from random import Random
from Crypto.Cipher import AES
from Crypto.Hash import SHA
from Crypto.PublicKey import RSA
''':cvar
加密解密
'''
# 对称加密:加密和解密的秘钥是一个
class AesEncrypt:
"""
AES加密
windows
pip install pycryptodome -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
找到site-package的包 然后把crypto 的c改成大写的即可
mac下 pip install pycrypto -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
"""
def __init__(self, key):
self.key = key # 初始化密钥 开发给的
self.length = AES.block_size # 初始化数据块大小
self.aes = AES.new(self.key.encode("utf8"), AES.MODE_ECB) # 初始化AES,ECB模式的实例
# 截断函数,去除填充的字符
self.unpad = lambda date: date[0:-ord(date[-1])]
def pad(self, text):
"""
填充函数,使被加密数据的字节码长度是block_size的整数倍
"""
count = len(text.encode('utf-8'))
add = self.length - (count % self.length)
entext = text + (chr(add) * add)
return entext
# 加密函数
def encrypt(self, encrData): # 加密函数
'''
:param encrData: 需要加密的数据
:return:
'''
res = self.aes.encrypt(self.pad(encrData).encode("utf8"))
msg = str(base64.b64encode(res), encoding="utf8")
return msg
# 解密函数
def decrypt(self, decrData): # 解密函数
res = base64.decodebytes(decrData.encode("utf8"))
msg = self.aes.decrypt(res).decode("utf8")
return self.unpad(msg)
class RsaEncrypt():
"""
初始化时必须传递公钥和私钥存储的文件路径
"""
def __init__(self, public_file, private_file):
self.public_file = public_file # 公钥 开发给的
self.private_file = private_file # 私钥 开发给的
def generate_key(self):
"""
这个方法是生成公钥和私钥的,在实际企业测试过程中,开发会提供公钥和私钥,我们不用自己生成
:return:
"""
random_generator = Random.new().read
rsa = RSA.generate(2048, random_generator)
# 生成私钥
private_key = rsa.exportKey()
# print(private_key.decode('utf-8'))
# 生成公钥
public_key = rsa.publickey().exportKey()
# print(public_key.decode('utf-8'))
with open(self.private_file, 'wb')as f:
f.write(private_key)
with open(self.public_file, 'wb')as f:
f.write(public_key)
print('生成')
# 从秘钥文件中获取密钥
def get_key(self, key_file):
with open(key_file) as f:
data = f.read()
key = RSA.importKey(data)
return key
# rsa 公钥加密数据
def encrypt_data(self, msg):
public_key = self.get_key(self.public_file)
cipher = PKCS1_cipher.new(public_key)
encrypt_text = base64.b64encode(cipher.encrypt(bytes(msg.encode("utf8"))))
return encrypt_text.decode('utf-8')
# rsa 私钥解密数据
def decrypt_data(self, encrypt_msg):
private_key = self.get_key(self.private_file)
cipher = PKCS1_cipher.new(private_key)
back_text = cipher.decrypt(base64.b64decode(encrypt_msg), 0)
return back_text.decode('utf-8')
# rsa 私钥签名数据
def rsa_private_sign(self, data):
private_key = self.get_key(self.private_file)
signer = PKCS1_signature.new(private_key)
digest = SHA.new()
digest.update(data.encode("utf8"))
sign = signer.sign(digest)
signature = base64.b64encode(sign)
signature = signature.decode('utf-8')
return signature
# rsa 公钥验证签名 sign也是开发给的
# 客户端-发起请求
def rsa_public_check_sign(self, text, sign):
publick_key = self.get_key(self.public_file)
verifier = PKCS1_signature.new(publick_key)
digest = SHA.new()
digest.update(text.encode("utf8"))
return verifier.verify(digest, base64.b64decode(sign))
if __name__ == '__main__':
##以下是aes的对称加密方法
# 重点:这个key必须是16位
# aes = AesEncrypt('abcdefghiaqwerty')
# # 加密方法
# aa = aes.encrypt('python自动化')
# print(aa)
# # 解密方法(验证)
# bb = aes.decrypt(aa)
# print(bb)
## 以下是rsa的非对称算法
# 两个参数是保存公钥和私钥的文件
rsa = RsaEncrypt('public_key.keystore', 'private_key.keystore')
## 生成公钥和私钥 并保存到两个文件中
rsa.generate_key() # 正常工作不需要调用这个方法
## 进行加密
aa = rsa.encrypt_data('python自动化')
print(aa)
## 进行解密
bb = rsa.decrypt_data(aa)
print(bb)
封装对数据库的(增删改查)操作
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/7/15 1:47 下午
# @File : dbutil.py
# @Software: PyCharm
import pymysql
from common.file_load import read_yaml
class DB():
def __init__(self,db_env):
self.dbinfo = read_yaml('/config/db.yml')[db_env]
#在测试用例文件内通过self.db = DB('test')来指定test数据库
#连接数据库
self.db = pymysql.connect(
host=self.dbinfo['host'],
port=self.dbinfo['port'],
user=self.dbinfo['user'],
password=self.dbinfo['pwd'],
charset="utf8mb4",
cursorclass=pymysql.cursors.DictCursor
)
# 查询
def select(self, sql):
cursor = self.db.cursor()
# 执行sql
cursor.execute(sql)
# 获取查询数据
data = cursor.fetchall()
# 提交(如果不提交多次查询可能会有问题)
self.db.commit()
cursor.close()
return data
# 更改
def updata(self, sql):
cursor = self.db.cursor()
# 执行sql
cursor.execute(sql)
# 提交(如果不提交多次查询可能会有问题)
self.db.commit()
cursor.close()
# 对数据库进行关闭
def close(self):
if self.db != None:
self.db.close()
封装动态读取文件的方法
Python的文件打开模式有如下几种:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/7/15 5:05 下午
# @File : file_load.py
# @Software: PyCharm
''':cvar
读取yaml,读取excel
'''
import json
import pandas
import yaml
from setting import DIR_NAME
# #绝对路径获取文件
# def read_yaml():
# with open('../data/mtxshop.yml','r',encoding='utf-8') as f:
# content = yaml.load(f,Loader=yaml.FullLoader)
# print(content)
# return content
#动态读取文件
def read_yaml(filename):
with open(DIR_NAME + filename, 'r', encoding='utf-8') as f:
content = yaml.load(f, Loader=yaml.FullLoader)
return content
def read_excel(filename, sheet_name):
pd = pandas.read_excel(DIR_NAME + filename,sheet_name=sheet_name,keep_default_na=False,engine='openpyxl')
#总行数(不包括第一行)
lines_count = pd.shape[0]
# 总列数
col_count = pd.columns.size # 获取总列数
# 获取单元格的方法的索引值是从0开始的
data = []
# 父循环控制行数
for row in range(lines_count): # 遍历行
line = [] # 存放同一行中不同列的数据
# 子循环控制列数
for col in range(col_count): # 遍历列
# 行和列组合交叉定位到一个单元格,可以拿到其内容
text = pd.iloc[row, col]
# 判断 如果列数==1的时候 请求参数 text正常读取是字符串 text转换成字典
if col == 1:
# 将json格式的字符串转换成字典
text = json.loads(text)
line.append(text)
data.append(line)
return data
if __name__ == '__main__':
read_yaml()
# print(read_yaml()['buynow'])
# print(read_yaml()['creattrade'])
data = read_excel('/data/buyer.xlsx', '立即购买')
print(data)
在pandas中,读取Excel非常简单,它只有一个方法:readExcel(),但是的参数非常多,后续我会再做详细讲解
文件打开模式(“mode=”) 描述
r : 以只读模式打开文件,并将文件指针指向文件头;如果文件不存在会报错
w : 以只写模式打开文件,并将文件指针指向文件头;如果文件存在则将其内容清空,如果文件不存在则创建
a : 以只追加可写模式打开文件,并将文件指针指向文件尾部;如果文件不存在则创建
r+ : 在r的基础上增加了可写功能
w+ : 在w的基础上增加了可读功能
a+ :在a的基础上增加了可读功能
b :读写二进制文件(默认是t,表示文本),需要与上面几种模式搭配使用,如wb, ab, ab+
Python中读取文件的相关方法:
read() : 一次读取文件所有内容,返回一个str;
read(size) : 每次最多读取指定长度的内容,返回一个str;
readlines(): 一次读取文件所有内容,按行返回一个list;
readline(): 每次只读取一行内容。
封装log,记录操作日志信息
日志的作用就是在测试、生产环境没有 Debug 调试工具时开发和测试人员定位问题的手段。日志打得好,就能根据日志的轨迹快速定位并解决线上问题,反之,日志输出不好,不仅无法辅助定位问题反而可能会影响到程序的运行性能和稳定性。
日志的普遍用途:
问题追踪:协助排查和定位问题,优化程序运行性能
状态监控:通过日志分析,可以监控系统的运行状态
安全审计:审计主要体现在安全上,可以发现非授权的操作
这里我记录日志封装log,目前只实现简单的排查定位问题,其他日志用途的实现后期优化
日志的基本格式:
日志的输出住要在文件中,应该包括以下内容:
1)日志时间
作为日志产生的日期和时间,这个数据非常重要,一般精确到毫秒。格式推荐:yyyy-MM-dd HH:mm:ss.SSS
2)日志级别
日志的输出都是分级别的,不同的设置不同的场合打印不同的日志
主要使用如下的四个级别:
2.1)DEBUG
主要输出调试性质的内容,该级别日志主要用于在开发、测试阶段输出。该级别的日志应尽可能地详尽,我们可以将各类详细信息记录到DEBUG里,起到调试的作用,包括参数信息,调试细节信息,返回值信息等等,便于在开发、测试阶段出现问题或者异常时,对其进行分析。
2.2)INFO
主要记录系统关键信息,在测试环境将日志级别调成 INFO,然后通过 INFO 级别的信息看看是否能了解这个应用的运用情况,如果出现问题后是否这些日志能否提供有用的排查问题的信息。
2.3)WARN
主要输出警告性质的内容,这些内容是可以预知且是有规划的,比如,某个方法入参为空或者该参数的值不满足运行该方法的条件时。在 WARN 级别的时应输出较为详尽的信息,以便于事后对日志进行分析
2.4)ERROR
主要针对于一些不可预知的信息,诸如:错误、异常等,比如,在 catch 块中抓获的网络通信、数据库连接等异常,若异常对系统的整个流程影响不大,可以使用 WARN 级别日志输出。在输出 ERROR 级别的日志时,尽量多地输出方法入参数、方法执行过程中产生的对象等数据,在带有错误、异常对象的数据时,需要将该对象一并输出
ERROR级别的日志打印通常伴随报警通知。ERROR的报出应该伴随着业务功能受损,即上面提到的系统中发生了非常严重的问题,必须有人马上处理。
2.5)CRITICAL(不常用)
致命的错误,特别糟糕的事情,如内存耗尽、磁盘空间为空,一般很少使用
3)线程名称
输出该日志的线程名称,一般在一个应用中一个同步请求由同一线程完成,输出线程名称可以在各个请求产生的日志中进行分类,便于分清当前请求上下文的日志。
4)日志记录器名称
日志记录器名称一般使用类名,日志文件中可以输出简单的类名即可,看实际情况是否需要使用包名和行号等信息。主要用于看到日志后到哪个类中去找这个日志输出,便于定位问题所在。
5)日志内容
代码如下:
import logging.handlers
from setting import DIR_NAME
class GetLogger:
'''
当已经创建了logger对象的时候,那么之后就不在创建了,也就是只创建一次对象
'''
# 把logger对象的初始值设置为None
logger = None
# 创建logger,并且返回这个logger
@classmethod
def get_logger(cls):
if cls.logger is None:
########创建日志器,控制他的创建次数
cls.logger = logging.getLogger('apiautotest') # 不是None
# 设置总的级别,debug/info/warning/error
# 只有比debug级别高的日志才会被显示出来
cls.logger.setLevel(logging.DEBUG)
# 2获取格式器
# 2.1 要给格式器设置要输出的样式
fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s:%(lineno)d] - %(message)s"
# 2.2创建格式器,并且给他设置样式
fm = logging.Formatter(fmt)
# 3.创建处理器 按照时间进行切割文件
tf = logging.handlers.TimedRotatingFileHandler(filename=DIR_NAME +'/logs/requests.log', # 原日志文件
when='H', # 间隔多长时间把日志存放到新的文件中
interval=1,
backupCount=3, # 除了原日志文件,还有3个备份
encoding='utf-8'
)
#这是在控制台上打印日志信息
logging.basicConfig(level=logging.DEBUG,format=fmt)
# 在处理器中添加格式器
#格式器可以初始化日志记录的内容格式,结合LogRecord对象提供的属性,可以设置不同的日志格式
#logging.Formatter(fmt=None, datefmt=None, style='%')
#fmt:日志格式参数,默认为None,如果不特别指定fmt,则使用’%(message)s’格式
#datafmt:时间格式参数,默认为None,如果不特别指定datafmt,则使用formatTime()文档中描述的格式
#style:风格参数,默认为’%’,也支持’$’,’{'格式
tf.setFormatter(fm)
# 在日志器中添加处理器
cls.logger.addHandler(tf)
# return cls.logger
return cls.logger
if __name__ == '__main__':
logger = GetLogger().get_logger()
print(id(logger))
logger1 = GetLogger().get_logger()
print(id(logger1))
logger.debug('调试') # 相当print小括号中的信息
logger.info('信息')
logger.warning('警告')
name = 'yaoyao'
logger.error('这个变量是{}'.format(name))
logger.critical('致命的')
logging库采用模块化方法,并提供了几类组件:记录器,处理程序,过滤器和格式化程序。
记录器(Logger):提供应用程序代码直接使用的接口。
处理器(Handler):将日志记录(由记录器创建)发送到适当的目的地。
筛选器(Filter):提供了更细粒度的功能,用于确定要输出的日志记录。
格式器(Formatter):程序在最终输出日志记录的内容格式。
logging的工作流程:
以记录器Logger为对象,设置合适的处理器Handler,辅助以筛选器Filter、格式器Formatter,设置日志级别以及常用的方法,最终输出理想的日志记录给到指定目标
一个Logger可以包含多个Handler;
每个Handler可以设置自己的Filter和Formatter;
logging模块提供很多个类型的处理器Handler,这里只用到了TimedRotatingFileHandler:日志记录到文件中,支持按时间间隔来更新日志
logging.handlers.TimedRotatingFileHandler(filename, when='h', interval=1, backupCount=0, encoding=None, delay=False, utc=False, atTime=None)
参数:
when:不同值对应不同时间类型,以字符串填入,不区分大小写
基于工作日的轮换时,将“ W0”指定为星期一,将“ W1”指定为星期二,依此类推,直到“ W6”指定为星期日。在这种情况下,不使用为interval传递的值
interval:时间长度,与when结合使用
backupCount:如果backupCount不为零,则最多将保留backupCount数的文件,并且如果发生翻转时将创建更多文件,则最早的文件将被删除。删除逻辑使用间隔来确定要删除的文件,因此更改间隔可能会留下旧文件。
utc:默认为False,使用本地时间;为True时,使用UTC时间
actime:默认为None,若非None时,必须是一个datetime.time实例,该实例指定发生翻转的一天中的时间,对于将翻转设置为“在午夜”或“在特定工作日”发生的情况。请注意,在这些情况下,atTime值可有效地用于计算初始 翻转,随后的翻转将通过正常间隔计算来计算。
其他的处理器后期做详解
logging库设定6个日志记录级别,我们可以通过设置日志级别,来决定哪些级别范围的日志记录可以输出
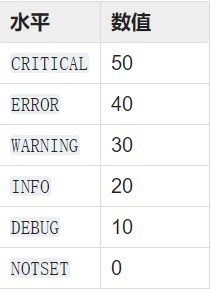
使用setLevel() 方法设置日志级别
若没有设置日志级别,日志器的日志级别默认为WARNING
封装测试用例(data)
一般情况来说,在测试的过程中,一个接口会对应N多个用例,如果每个用例写一个方法调用断言,工作量太大,不利于维护和排查问题,一旦接口有变化,就需要重新设计用例,维护成本太高,易用性太差。
基于此,我把用例放在了yml文件和Excel里,这样就可以通过读取文件去执行文件里的用例,相当于把一个接口的测试分成了三部分存储封装,即:接口(API)、用例(data)、断言(teatcases),当借口发生改变的时候只需要快速定位到API处修改接口和data即可。
同时减少了工作量,易于维护
下面我就以商城的立即购买为例在.yml中编写用例:
商品id:product_id,数量:num
buynow:
- ['正向用例',{'product_id': "123", 'num': "1" },200,'']
- [ 'num为0',{ 'product_id': '123','num': '0' },400,'加入购物车数量必须大于0' ]
test2:
- ['用例名称',{ '参数1': '值1','参数2': '值2',...},状态码,'响应内容']
读取文件:data = read_yaml(’/data/xxx.yml’)[‘buynow’]
封装登录接口获取token
在做某些接口测试或者场景测试时,一般都是以登录为前提,所以这里就需要对登录接口进行封装,从而获取登录状态下的token,转给其他接口使用
代码如下:
from common.client import RequestsClient
from common.encry_decry import md5
class BuyerLoginApi(RequestsClient):
def __init__(self):
super().__init__()
self.host = 'http://www.xxx.com:0000'
self.url = self.host + '/passport/login'
self.params = {
'username': '',
# md5加密的方法
'password': md5('密码'),
# 验证码
'captcha': '1234',
# 用户id
'uuid': '1234567890'
}
self.method = "post"
if __name__ == '__main__':
# 创建登录对象
buyerapi = BuyerLoginApi()
# 发起请求
resp = buyerapi.send().json()
print(resp)
运行结果:

封装basic_api
封装完登录接口后会发现能正常调通登录接口并获得返回值,返回值里也包含了我想要的token(access_token),此时就需要封装个基本api,去接受这个token,以便调用给其它接口
代码如下:
import jsonpath
from api.buyer_api.login import BuyerLoginApi
from common.client import RequestsClient
class BuyerBaseApi(RequestsClient):
buyer_token = None
def __init__(self):
RequestsClient.__init__(self)
self.host = 'http://www.mtxshop.com:7002'
self.headers = {
# access_token这个变量需要从登陆接口的返回值里面去提取
'Authorization': BuyerBaseApi.buyer_token
}
封装setting
python中的settings使用绝对路径
setting使用了的 Python 内部变量 file ,该变量被自动设置为代码所在的 Python 模块文件名。 os.path.dirname(file) 将会获取自身所在的文件,即settings.py 所在的目录,然后由os.path.join 这个方法将这目录与 templates 进行连接。
代码如下:
import os
DIR_NAME = os.path.dirname(os.path.abspath(__file__))
print(DIR_NAME)
conftest.py文件
一、conftest特点:
1、可以跨.py文件调用,有多个.py文件调用时,可让conftest.py只调用了一次fixture,或调用多次fixture
2、conftest.py与运行的用例要在同一个pakage下,并且有__init__.py文件
3、不需要import导入 conftest.py,pytest用例会自动识别该文件,放到项目的根目录下就可以全局目录调用了,如果放到某个package下,那就在改package内有效,可有多个conftest.py
4、conftest.py配置脚本名称是固定的,不能改名称
5、conftest.py文件不能被其他文件导入
6、所有同目录测试文件运行前都会执行conftest.py文件
类似于setup和teardown的用法
二、conftest用法:
conftest文件实际应用需要结合fixture来使用,fixture中参数scope也适用conftest中fixture的特性,这里再说明一下
1、fixture源码详解
fixture(scope=‘function’,params=None,autouse=False,ids=None,name=None):
fixture里面有个scope参数可以控制fixture的作用范围,scope:有四个级别参数"function"(默认),“class”,“module”,“session
params:一个可选的参数列表,它将导致多个参数调用fixture功能和所有测试使用它。
autouse:如果True,则为所有测试激活fixture func可以看到它。如果为False则显示需要参考来激活fixture
ids:每个字符串id的列表,每个字符串对应于params这样他们就是测试ID的一部分。如果没有提供ID它们将从params自动生成
name:fixture的名称。这默认为装饰函数的名称。如果fixture在定义它的统一模块中使用,夹具的功能名称将被请求夹具的功能arg遮蔽,解决这个问题的一种方法时将装饰函数命令"fixture_“然后使用”@pytest.fixture(name=’’)”。
2、fixture的作用范围
fixture里面有个scope参数可以控制fixture的作用范围:session>module>class>function
-function:每一个函数或方法都会调用
-class:每一个类调用一次,一个类中可以有多个方法
-module:每一个.py文件调用一次,该文件内又有多个function和class
-session:是多个文件调用一次,可以跨.py文件调用,每个.py文件就是module
function默认模式@pytest.fixture(scope=‘function’)或 @pytest.fixture()
3、conftest结合fixture的使用
conftest中fixture的scope参数为session,所有测试.py文件执行前执行一次
conftest中fixture的scope参数为module,每一个测试.py文件执行前都会执行一次conftest文件中的fixture
conftest中fixture的scope参数为class,每一个测试文件中的测试类执行前都会执行一次conftest文件中的fixture
conftest中fixture的scope参数为function,所有文件的测试用例执行前都会执行一次conftest文件中的fixture
三、conftest应用场景
1、每个接口需共用到的token
2、每个接口需共用到的测试用例数据
3、每个接口需共用到的配置信息
代码如下:
import jsonpath
import pytest
# hook函数
from api.base_api import BuyerBaseApi, SellerBaseApi
from api.buyer.login_api import BuyerLoginApi
from api.seller.login_api import SellerLoginApi
def pytest_collection_modifyitems(items):
# item表示每个测试用例,解决用例名称中文显示问题
for item in items:
item.name = item.name.encode("utf-8").decode("unicode-escape")
item._nodeid = item._nodeid.encode("utf-8").decode("unicode-escape")
'''
fixture函数可以实现setup的功能,在测试用例之前执行内容,初始化
功能更强大,可以随便取名字
@pytest.fixture(scope="",autouse=False)
默认autouse是False,需要手动引用
True,自动引用
session:pytest发起请求到结束 只会执行一次
function:函数级别的测试用例和方法级别的测试用例都用这个范围
class:你引用fixture函数的class类,就会执行一次
module: 你引用fixture函数的python文件,就会执行一次
引用:
把fixture装饰的函数的名字当做参数传递到测试用例当中就是调用了
'''
@pytest.fixture(scope='function',autouse=True)
def buyer_login():
# 依赖登录接口
buyerapi = BuyerLoginApi()
# 发起请求
resp = buyerapi.send()
# 生成token
BuyerBaseApi.buyer_token = jsonpath.jsonpath(resp.json(), '$.access_token')[0]
# print('=========buyer_login==============')
@pytest.fixture(scope='function',autouse=True)
def seller_login():
# 登录
sellerloginapi = SellerLoginApi()
sellerloginapi.send()
# 数据提取
SellerBaseApi.seller_token = sellerloginapi.extract_expr('$.access_token')
配置文件pytest.ini
pytest配置文件可以改变pytest的运行方式,它是一个固定的文件pytest.ini文件,读取配置信息,按指定的方式去运行,pytest.ini的位置一般放在项目工程的根目录(即当前项目的顶级文件夹下)
可以通过cmd下使用 pytest -h 命令查看pytest.ini的设置选项
[pytest]
addopts = -sv --alluredir ./reports/xxx --clean-alluredir
testpaths = ./testcases
python_files = test_xxx.py
python_classes = Test*
python_functions = test_*
addopts:
addopts参数可以更改默认命令行选项,这个当我们在cmd输入一堆指令去执行用例的时候,就可以用该参数代替了,省去重复性的敲命令工作。
加了addopts之后,我们在cmd中只需要敲pytest就可以直接执行以下命令了:
pytest -sv --alluredir ./reports/shop --clean-alluredir
testpaths:
testpaths指示pytest去哪里访问。testpaths是一系列相对于根目录的路径,用于限定测试用例的搜索范围。只有在pytest未指定文件目录参数或测试用例标识符时,该选项才有作用
python_files:要执行的测试文件的文件名
python_classes:要执行的以 test_ 开头的类名
python_functions:要执行的以 test_ 开头的类里面的方法
除此之外还可以定义一些mark等
使用Pytest管理测试用例
在执行所有用例之前先执行登录接口,获取token。所以把登录接口的请求放在conftest.py文件中
conftest.py代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/7/15 4:42 下午
# @File : conftest.py
# @Software: PyCharm
import jsonpath
import pytest
# hook函数
from api.base_api import BuyerBaseApi, SellerBaseApi
from api.buyer.login_api import BuyerLoginApi
from api.seller.login import SellerLoginApi
def pytest_collection_modifyitems(items):
# item表示每个测试用例,解决用例名称中文显示问题
for item in items:
item.name = item.name.encode("utf-8").decode("unicode-escape")
item._nodeid = item._nodeid.encode("utf-8").decode("unicode-escape")
'''
fixture函数可以实现setup的功能,在测试用例之前执行内容,初始化
功能更强大,可以随便取名字
@pytest.fixture(scope="",autouse=False)
默认autouse是False,需要手动引用
True,自动引用
session:pytest发起请求到结束 只会执行一次
function:函数级别的测试用例和方法级别的测试用例都用这个范围
class:你引用fixture函数的class类,就会执行一次
module: 你引用fixture函数的python文件,就会执行一次
引用:
把fixture装饰的函数的名字当做参数传递到测试用例当中就是调用了
'''
@pytest.fixture(scope='function', autouse=True)
def buyer_login():
# 依赖登录接口
buyerapi = BuyerLoginApi()
# 发起请求
resp = buyerapi.send()
# 生成token
###########这个位置你既然写的是BUyerbaseapi里面有buyer——token那么你就得在这个类下面定义 否则没办法传递
BuyerBaseApi.buyer_token = jsonpath.jsonpath(resp.json(), '$.access_token')[0]
# print('=========buyer_login==============')
@pytest.fixture(scope='function',autouse=True)
def seller_login():
# 登录
sellerloginapi = SellerLoginApi()
sellerloginapi.send()
# 数据提取
SellerBaseApi.seller_token = sellerloginapi.extract_expr('$.access_token')
然后把每个功能模块封装成一个类,每个用例封装成一个方法
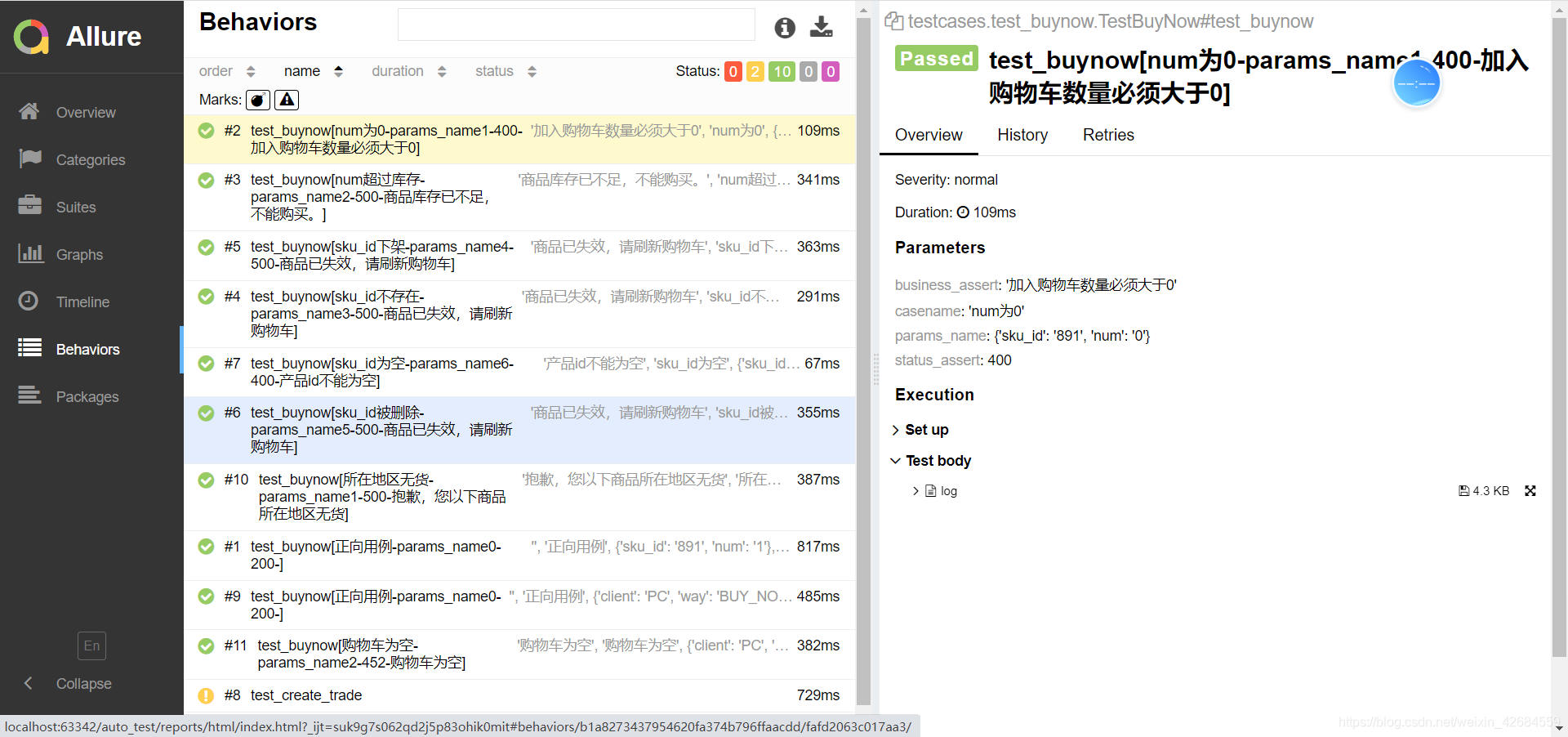
以立即购买为例举例代码如下:
import jsonpath
import pytest
from api.base_api import BuyerBaseApi
from api.buyer.buynow_api import BuyNowApi
from api.buyer.login_api import BuyerLoginApi
from common.dongtaiduqu import read_yaml
#
# data = [
# # 测试用例名字 参数 状态码断言 响应体内容断言
# ['正向用例',{'product_id': "123", 'num': "1" },200,''],
# ['num为0',{'product_id':'123','num':'0'},400,'加入购物车数量必须大于0'],
data = read_yaml('/data/xxx.yml')['buynow']
class TestBuyNow():
@pytest.mark.parametrize('casename,params_name,status_assert,business_assert', data)
def test_buynow(self, casename, params_name, status_assert, business_assert):
buynowapi = BuyNowApi()
# !!! 修改立即购买的参 ·
buynowapi.params = params_name
# headers调用token在底层已经调用了
resp = buynowapi.send()
# 调用立即购买
print(resp.status_code)
print(resp.text)
# 断言
pytest.assume(resp.status_code == status_assert)
if resp.status_code != 200:
pytest.assume(jsonpath.jsonpath(resp.json(), '$.message')[0] == business_assert)
创建一个执行的主入口(run)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/7/15 11:56 上午
# @File : run.py
# @Software: PyCharm
#把命令行输入的命令封装到脚本中
import os
import pytest
if __name__ == '__main__':
pytest.main()
os.system('allure generate .\\reports\\xxx -o ./reports/html --clean')
生成测试报告
1)安装pytest-html插件。也可以使用allure插件生成测试报告,但是如果pytest版本过高,就无法识别allure插件
2)添加“–self-contained-html”可以整合样式文件到html文档中,方便之后发送测试报告到邮箱
pytest.main(['-v', '--html=report/report.html', '--self-contained-html'])

源码:
接口自动化框架源码
后续更新中…



















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











