






之前做过一个电商网站,因为前期涉及到的数据量比较小,并发也不是很高,所以只有一个主库。当然所有的小网站都是这么一步步发展过来的。
当总订单量达到300万的时候,我们就开始构思数据库的高并发高可用设计了。
1、数据库采用主从部署方式
这是目前最简单的高可用方式。主从部署,主写从读,读写分离。当读操作大于写操作的时候,这种方案带来的性能提升是很明显的。
主从复制:
几乎所有的主流数据库都支持复制,这是进行数据库简单扩展的基本手段。下面以Mysql为例来说明,它支持主从复制,配置也并不复杂,只需要开启主服务器上的二进制日志以及在主服务器和从服务器上分别进行简单的配置和授权。Mysql的主从复制是依据主服务器的二进制日志文件进行的,主服务器日志中记录的操作会在从服务器上重放,从而实现复制,所以主服务器必须开启二进制日志,自动记录所有对于主数据库的更新操作,从服务器再定时到主服务器取得二进制日志文件进行重放则完成了数据的复制。主从复制也用于自动备份。
读写分离:
为保证数据库数据的一致性,我们要求所有对于数据库的更新操作都是针对主数据库的,但是读操作是可以针对从数据库来进行。大多数站点的数据库读操作比写操作更加密集,而且查询条件相对复杂,数据库的大部分性能消耗在查询操作上了。 主从复制数据是异步完成的,这就导致主从数据库中的数据有一定的延迟,在读写分离的设计中必须要考虑这一点。以博客为例,用户登录后发表了一篇文章,他需要马上看到自己的文章,但是对于其它用户来讲可以允许延迟一段时间(1分钟/5分钟/30分钟),不会造成什么问题。这时对于当前用户就需要读主数据库,对于其他访问量更大的外部用户就可以读从数据库。
数据库反向代理:
在读写分离的方式使用主从部署方式的数据库的时候,会遇到一个问题,一个主数据库对应多台从服务器,对于写操作是针对主数据库的,数据库个数是唯一的,但是对于从服务器的读操作就需要使用适当的算法来分配请求啦,尤其对于多个从服务器的配置不一样的时候甚至需要读操作按照权重来分配。 对于上述问题可以使用数据库方向代理来实现。就像WEB反向代理服务器一样,Mysql Proxy同样可以在SQL语句转发到后端的Mysql服务器之前对它进行修改。
2、数据库垂直分割
上面那种情况是针对读操作远大写,且主库可以支撑写请求。如果单机数据库写请求已经很大,比如超过CPU消耗的50%以上,再去增加从服务器意义不是很大。因为数据在同步的时候,从服务器写请求也将达到50%以上,这时候剩余给查询的资源就会大大降低,整个读写架构的性能也会大幅度下降。
这时候,就非常有必要对整个数据库架构进行升级,也就是垂直分割,
最简单的做法就是将业务相对独立的模块进行独立分开部署,这主要是为了避免join无法操作,因为跨库将无法进行join。当根据业务模块对数据进行分库,之后在针对每个库进行主从同步,每个库只需要承担自己业务范围内的查询插入操作,大大提升了性能。
3、数据库水平分割
如果业务分库之后,性能还是有瓶颈,那就对同一个业务库进行多库部署,每个库都存放数据,比如1库中有user表,2库中也有user表,每个库的数据不一样。当要对用户进行增删改查操作时,要先进行路由计算,比如对userId进行路由计算,具体这个用户应该落到那个库中。
4、数据表的垂直和水平分割
4.1、对表进行垂直分割,大表变小表,例如一张表的字段达到100多个之后,其中只有部分的字段是经常用到,剩下部分的字段是比较少被查询到的,这时候就可以将一张表拆分成多张表,当然分开的表也要进行数据关联,比如用户表拆分成用户信息表1,信息表2,每张表中都要有userId用来保证相关性。这时候单张表的数据量下降了,单表查询的性能也随之而然上升
4.2、对表进行水平分割。当一张表的数据量达到1000万,或者几千万的时候,数据的查询写入性能会很差,这时候就需要对表进行水平分割。水平分割比较简单,一般根据一定的路由算法进行定位新的表,常用的就是对id进行取余操作,根据余数来确定数据是哪张表。
5、数据库的高可用
之前讲到数据库的高可用,就是部署主从服务,
5.1、当主服务器挂掉之后,手动切换到从服务器。总所周知,手动切换的速度比较慢,要进行配置文件的修改,然后重启web服务器。
5.2、从库中其中一台挂掉之后,部分读取这台从库的请求将会得不到响应。
自动化的思路就是从库检测到主库挂掉之后,自动顶替上去。以及从库部分挂掉之后,这些从库将收不到任何请求操作,请求只会去存活的从库上查询。
先来看从库高可用结构图:
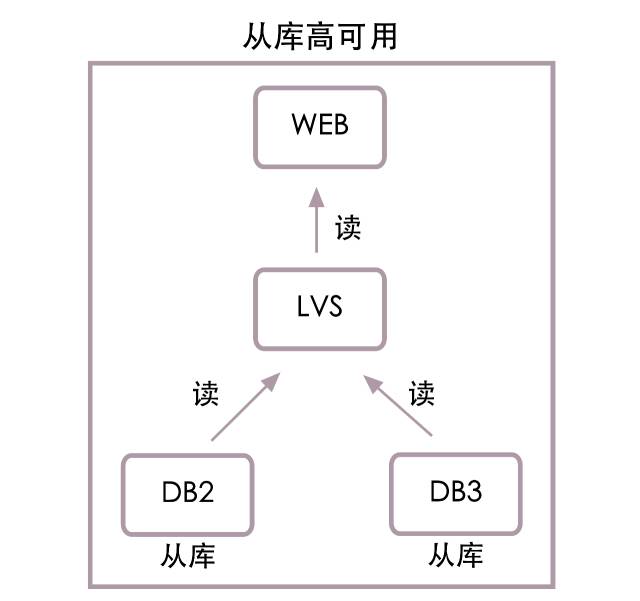
如上图所示,web服务器将不再直接连接从库DB2和DB3,而是连接LVS负载均衡,由LVS连接从库。这样做的好处是LVS能自动感知从库是否可用,从库DB2宕机后,LVS将不会把读数据请求再发向DB2。同时DBA需要增减从库节点时,只需独立操作LVS即可,不再需要项目组更新配置文件,重启服务器来配合。
再来看主库高可用结构图:
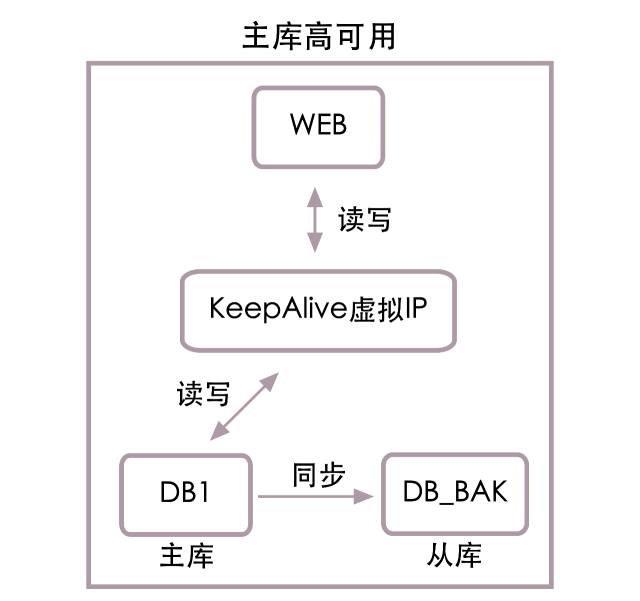
如上图所示,web服务器将不再直接连接主库DB1,而是连接KeepAlive虚拟出的一个虚拟ip,再将此虚拟ip映射到主库DB1上,同时添加DB_bak从库,实时同步DB1中的数据。正常情况下web还是在DB1中读写数据,当DB1宕机后,脚本会自动将DB_bak设置成主库,并将虚拟ip映射到DB_bak上,web服务将使用健康的DB_bak作为主库进行读写访问。这样只需几秒的时间,就能完成主数据库服务恢复。
组合上面的结构,得到主从高可用结构图:
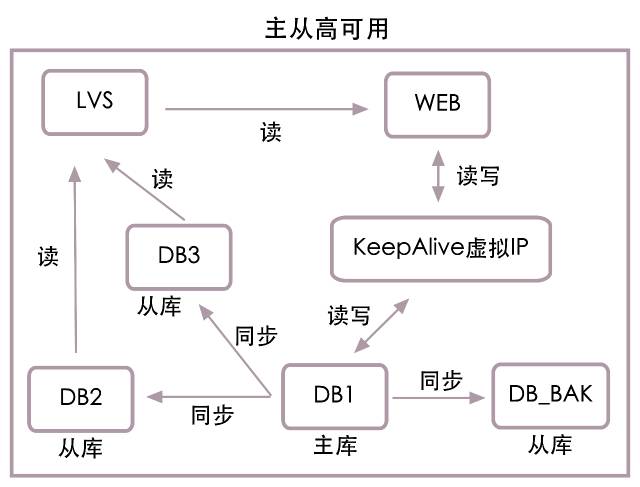
数据库高可用还包含数据修补,由于我们在操作核心数据时,都是先记录日志再执行更新,加上实现了近乎实时的快速恢复数据库服务,所以修补的数据量都不大,一个简单的恢复脚本就能快速完成数据修复。
6、数据分级
支付系统除了最核心的支付订单表与支付流水表外,还有一些配置信息表和一些用户相关信息表。如果所有的读操作都在数据库上完成,系统性能将大打折扣,所以我们引入了数据分级机制。
我们简单的将支付系统的数据划分成了3级:
第1级:订单数据和支付流水数据;这两块数据对实时性和精确性要求很高,所以不添加任何缓存,读写操作将直接操作数据库。
第2级:用户相关数据;这些数据和用户相关,具有读多写少的特征,所以我们使用redis进行缓存。
第3级:支付配置信息;这些数据和用户无关,具有数据量小,频繁读,几乎不修改的特征,所以我们使用本地内存进行缓存。
使用本地内存缓存有一个数据同步问题,因为配置信息缓存在内存中,而本地内存无法感知到配置信息在数据库的修改,这样会造成数据库中数据和本地内存中数据不一致的问题。
为了解决此问题,可以开发了一个高可用的消息推送平台,当配置信息被修改时,我们可以使用推送平台,给支付系统所有的服务器推送配置文件更新消息,服务器收到消息会自动更新配置信息,并给出成功反馈。















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









