需求一.将数据显示到页面
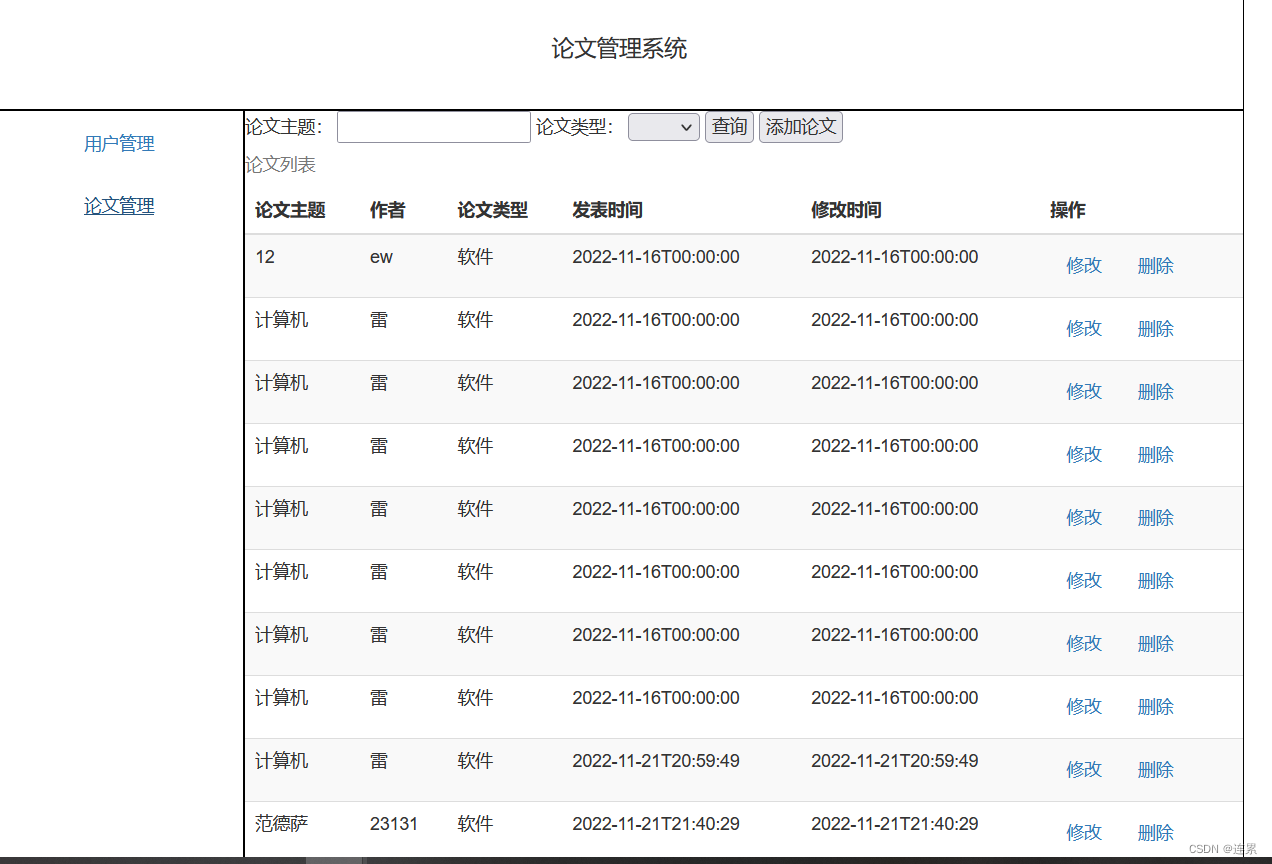
1.1 需求分解
第一步、在页面加载完成后通过axios发送请求
//页面加载完成后执行
created: function () {
_self = this;
//通过localStorage的getItem函数获取缓存的uid
var url = "http://localhost:8080/paper1/paper/list?pageIndex="+this.pageIndex+"&pageSize="+this.pageSize+"&uid="+localStorage.getItem("uid");
this.requestPapers(url); //调用请求论文列表的函数发送请求
}
});
//请求论文列表
requestPapers(url){
//通过axios发送请求get请求,then响应
axios.get(url).then(respones => {
console.log(respones.data);
this.papers = respones.data.data; //给论文列表赋值
this.pageTotle = respones.data.pageTotle; //给总条数赋值
//Math.ceril函数=》小数取整,向上取整
this.pageNum = Math.ceil(this.pageTotle / this.pageSize); //计算页数
});
},
第2步、在data属性中绑定数据
data: {
papers: null, //论文列表
第3步、通过v-for指令显示到页面上(在table上)








 该博客总结了前端开发中的几个关键需求:数据显示、分页显示、添加模板的显示与隐藏,以及修改页面的数据回显。首先,通过axios获取数据并在页面加载后绑定到data属性,使用v-for指令展示在表格上。接着,详细介绍了如何实现分页功能,包括计算页数和选中页。此外,展示了如何控制添加模板的显示和关闭,以及在修改页面时的数据回显策略。
该博客总结了前端开发中的几个关键需求:数据显示、分页显示、添加模板的显示与隐藏,以及修改页面的数据回显。首先,通过axios获取数据并在页面加载后绑定到data属性,使用v-for指令展示在表格上。接着,详细介绍了如何实现分页功能,包括计算页数和选中页。此外,展示了如何控制添加模板的显示和关闭,以及在修改页面时的数据回显策略。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









