







windows
一、最基本的使用:分表分库
1、下载
下载地址:http://dl.mycat.org.cn/
我选择的windows版Mycat-server-1.6.7.1-release-20200209222254-win.tar.gz

2、解压
3、安装(启动、安装都得以管理员权限进入)
cmd -----右键----- 管理员身份运行-----进入mycat的bin-----运行mycat install
安装完成后可在任务管理器查看:

使用命令 mycat start 启动服务,或在任务管理器右键手动开启
补充一些其他的命令:
4、库表准备
-
ip为193.168.1.241的计算机一台 ;安装了mysql5.6 ; 端口为3307 ; 用户名root ; 密码:w*******20;
ip为localhost的计算机一台; 安装了mysql5.6 ; 端口为3306 ; 用户名root ; 密码:root;
两台计算机使用局域网或内网穿透或云服务器可以互ping -
都安装了mycat
-
计算机ip 241、localhost的mysql数据库都有库 wssp_charging ; 有表 bus_customerchangelog;

5、配置mycat
-
mycat的conf目录下这几个文件依次配置


-
server.xml配置
其他配置全部不用动,找到下面的user标签

-
schema.xml配置

注意:

<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="MYCAT" checkSQLschema="false" sqlMaxLimit="100">
<table name="bus_customerchangelog" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="wssp_charging" />
<dataNode name="dn2" dataHost="localhost2" database="wssp_charging" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" password="root">
<readHost host="hostS2" url="localhost:3306" user="root" password="root" />
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="193.168.1.241:3307" user="root" password="wellsun_2020">
<readHost host="hostS2" url="193.168.1.241:3307" user="root" password="wellsun_2020" />
</writeHost>
</dataHost>
</mycat:schema>
- rule.xml配置
因为上面使用了rule="mod-long"且有两个节点,所以在rule.xml里找到function标签的mod-long,设置为2。mod-long规则,由于是两个节点来提供服务,这里我就将其设置为均分:比如插入时,一个一库,轮流进行

5.wrapper.conf配置指向jdk路径

6、连接使用MyCat
双击或cmd命令开启startup_nowrap.bat


241表里的数据:

lacal表数据

mycat表数据:

7、以上配置成功启动后,可以删除、修改、插入mycat,同时同步到两个mysql,操作单个mysql也可在mycat中同步但是当有自增字段比如主键id时,插入时不输入自增主键ID会出错的
解决:
- 修改server.xml配置文件,修改sequnceHandlerType参数的值为1,表示使用数据库方式生成sequence:
<property name="sequnceHandlerType">1</property>

- 选择一个数据节点(物理的数据库节点)创建MYCAT_SEQUENCE的表和相关函数,注意这里的MYCAT_SEQUENCE的表和相关函数需要存放在同一个节点上。本文选择本地mysql的wssp_charging库里(即节点dn1)来运行如下命令创建相关的数据表和函数
USE wssp_charging;-- -此处是你自己的库名,我选的是节点dn1,本地mysql的wssp_charging库-- ---
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE MYCAT_SEQUENCE ( name VARCHAR(50) NOT NULL, current_value INT NOT NULL, increment INT NOT NULL DEFAULT 100, PRIMARY KEY (name) ) ENGINE=InnoDB;
-- ----------------------------
-- Function structure for `mycat_seq_currval`
-- ----------------------------
DROP FUNCTION IF EXISTS `mycat_seq_currval`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` FUNCTION `mycat_seq_currval`(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET latin1
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT concat(CAST(current_value AS CHAR),",",CAST(increment AS CHAR) ) INTO retval FROM MYCAT_SEQUENCE WHERE name = seq_name;
RETURN retval ;
END
;;
DELIMITER ;
-- ----------------------------
-- Function structure for `mycat_seq_nextval`
-- ----------------------------
DROP FUNCTION IF EXISTS `mycat_seq_nextval`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` FUNCTION `mycat_seq_nextval`(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET latin1
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
-- ----------------------------
-- Function structure for `mycat_seq_setval`
-- ----------------------------
DROP FUNCTION IF EXISTS `mycat_seq_setval`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` FUNCTION `mycat_seq_setval`(seq_name VARCHAR(50), value INTEGER) RETURNS varchar(64) CHARSET latin1
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
- 插入测试表sequence生成数据到上述创建的表格中,相关命令如下:
INSERT INTO mycat_sequence (name, current_value, increment) VALUES ('BUS_CUSTOMERCHANGELOG', 100, 100);-- -注意:参数一是你的表名,参数二是自增的起始值,参数三是步长,可理解为mycat在数据库中一次读取多少个sequence. 当这些用完后, 下次再从数据库中读取.- ---

- 修改\mycat\conf下的sequence_db_conf.properties配置文件中的相关配置,增加sequence的节点配置信息,否则mycat是不知道sequence的表和函数在哪个节点上的。编辑该属性文件,增加如下值:
BUS_CUSTOMERCHANGELOG=dn1#注意,key是你的表名必须大写,value是你这个表的节点(MYCAT_SEQUENCE在哪个节点创建的就写哪个,我在dn1节点即本地mysql创建的MYCAT_SEQUENCE)
- 重启mycat
以管理员权限进入mycat的bin目录,执行mycat.bat restart - 测试,在mycat里执行一条插入bus_customerchangelog的语句,不带自增主键ID的。
INSERT INTO `bus_customerchangelog` (
`Customerid`,`OldName`,`OldMobile`,`OldIdcard`,`OldWechat`,
`NewName`,`NewMobile`,`NewIdcard`,`NewWechat`,`ElecValue`,
`WaterValue`,`Creator`,`OrganizationId`,`customerNum`
)
VALUES
(
'1','1','1','1','1',
'1','1','1','1','1',
'1','1','1','1'
)
成功:

失败的情况:
- The user specified as a definer (‘root’@’%’) does not exist
说明root账号一般是访问视图文件引起的(没有权限),解决:
- 进入cmd:mysql -uroot -p
- mysql>grant all privileges on *.* to root@"%" identified by ".";
Query OK, 0 rows affected (0.00 sec)
- mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
- mycat sequnce err.io.mycat.config.util.ConfigException: can’t find definition for sequence
解决:检查上面第四步,key是否是自己的表名 - op table not in schema----****
解决:检查上面第一步,是否sequnceHandlerType配置为1 - mycat sequnce err.java.lang.NumberFormatException: “null”
解决:检查上面第一步,是否sequnceHandlerType配置为1 - mycat sequnce err.java.lang.NumberFormatException: For input string: “null”
解决:检查上面第三步,key是否是自己表名
Linux
一、最基本的使用:分表分库
(1)下载–安装–配置–启动 和windows一样
二、主从复制
windows下修改my.ini

Linux下修改my.cnf
1、一主一从
(1)拓展:搭建主从复制,一个主机,一个从机






2、双主双从
准备虚拟机:主一、主二、从一、从二
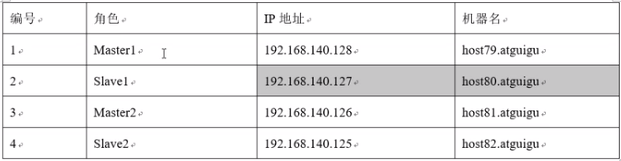
(1)修改主一配置文件,在my.cnf中,设置logbin格式的下面加上

(2)配置主二

(3)配置从一配置文件,和一主一从的从机配置一模一样,若已配置过,无需修改

(4)配置从二文件,id=4

(5)重启四台虚拟机的mysql服务,关闭所有虚拟机防火墙等

(6)两台主机都授权

(7)查看两台主机是否都授权成功

(8)查看并记录master状态的关键值,
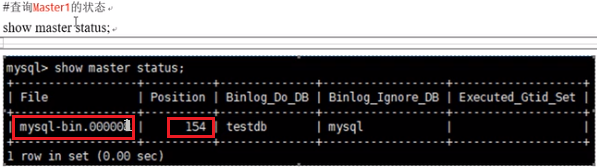
然后进入从一的mysql里面配置需要复制的主一,使用start slave;启动slave,使用show slave status\G;以列表的形式查看slave状态
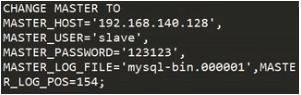

进入从二的mysql上配置需要复制的主二,使用start slave;启动slave,使用show slave status\G;以列表的形式查看slave状态
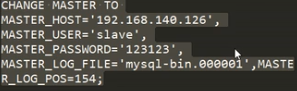
(9)两个主机也得互相复制。当主一在运行时,主二必须同步主一的数据(相当于一个从机三),因为当主一死机后,主二要升级为主一承担起主一的责任,此时若主一主二数据不一致会造成数据丢失;当主一再次重启后会退居二线充当主二备机的角色,主二不会退位让给主一直到主二死机
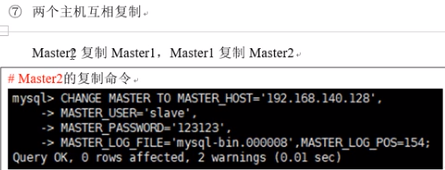
在主一上执行
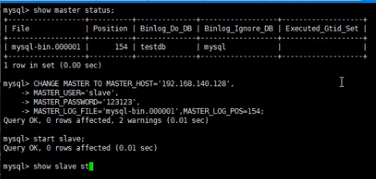
在主二上执行
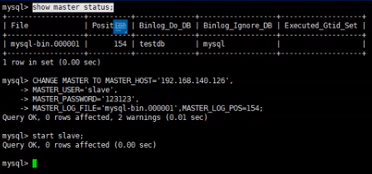
测试插入数据

3、双主双从的读写分离
(1)在主一的schema.xml里修改balance=“1”

(2)并在<dataHost></dataHost>中加上主二和从二的读写配置


(3)其他参数说明:

(4)启动mycat,验证读写分离

三、库表拆分
1、分库之垂直拆分


需求:
- 订单库orders
- 客户表customer
- 订单表
- 订单详情表
- 字典表
将上面的表分库,客户表放在虚拟机一(ip127,dn2)的订单库orders,其他全部放在虚拟机二(ip128,dn1)的订单库orders
(1)修改mycat的conf下的schema.xml文件


(2)在128、127上分别创建orders数据库


(3)启动mycat并创建第一步的所有表。
- 启动mycat:
./mycat - 登录mycat:
mysql -uEric -p123456 -h192.168.140.127 -P8066 - 进入mycat:
use MYCAT - 在mycat里创建以下表


2、分表之水平拆分
- 和最上面基本用法window分表分库是同一个东西,不同的是加了一个订单详情order_detail的子表
(1)order表水平分表

(2)子表order_detail的水平分表


(3)全局表。 比如订单表里面某个字段值对应的是字典表里的值,这时就要考虑字典表与子表的区别及特点:
- 多个表都需要字典表,而子表只有自己的主表需要
- 变动不频繁
- 数据总量变化不大
- 数据量不大,一般很少超过十万条记录


3、水平分表之常用分片规则
(1)分片枚举

(2)范围约定
- 提前规划好分片字段某个范围属于哪个分片
比如订单支付表中的订单编号在某个范围到dn1,某个范围到dn2

(3)时间日期
- 比如日志信息表中按日志记录的日期分表。
- sBeginDate:设置分片的开始日期,
sEndDate:设置分片的结束日期,
sPartionDay:设置每几天分一次表。
如上配置:从2019-01-01开始,每隔两天换一个节点存储,一直到2019-01-04 - 注意:一定要设置sEndDate结束日期,这样01、02在一号节点,03、04在二号节点,但凡过了结束日期发现当没有三号节点时,05、06会再次到一号节点,07、08到二号节点,以此类推。

四、分表扩展全局序列原理
1、主键自增之数据库生成方式
- 公司业务中一般使用的都是数据库生成方式。和上面Windows的分表分库中第七条一个东西,可直接去上面参考

五、Mycat的高可用
1、基于HA机制的mycat高可用
(1)原理

(2)准备

(3)HA搭建步骤

- 上面配置haproxy.conf的配置
## global配置中的参数为进程级别的参数,通常与其运行的操作系统有关
global
log 127.0.0.1 local0 ## 定义全局的syslog服务器,最多可以定义2个
### local0是日志设备,对应于/etc/rsyslog.conf中的配置,默认回收info的日志级别
#log 127.0.0.1 local1 info
chroot /usr/local/haproxy ## 修改HAProxy的工作目录至指定的目录并在放弃权限之前执行
### chroot() 操作,可以提升 haproxy 的安全级别
gid 99 #group haproxy ## 同gid,不过这里为指定的用户组名
uid 99 # user haproxy ## 同uid,但这里使用的为用户名
daemon ## 设置haproxy后台守护进程形式运行
# nbproc 1 ## 指定启动的haproxy进程个数,
### 只能用于守护进程模式的haproxy;默认为止启动1个进程,
### 一般只在单进程仅能打开少数文件描述符的场中中才使用多进程模式
maxconn 4096 ## 设定每个haproxy进程所接受的最大并发连接数,
### 其等同于命令行选项"-n","ulimit-n"自动计算的结果正式参照从参数设定的
pidfile /usr/data/haproxy/haproxy.pid ## 进程文件(默认路径 /var/run/haproxy.pid)
# node liuyazhuang135 ## 定义当前节点的名称,用于HA场景中多haproxy进程共享同一个IP地址时
# description liuyazhuang135 ## 当前实例的描述信息
## defaults:用于为所有其他配置段提供默认参数,这默认配置参数可由下一个"defaults"所重新设定
defaults
log global ## 继承global中log的定义
mode tcp ## mode:所处理的模式 (tcp:四层 , http:七层 , health:状态检查,只会返回OK)
### tcp: 实例运行于纯tcp模式,在客户端和服务器端之间将建立一个全双工的连接,
#### 且不会对7层报文做任何类型的检查,此为默认模式
### http:实例运行于http模式,客户端请求在转发至后端服务器之前将被深度分析,
#### 所有不与RFC模式兼容的请求都会被拒绝
### health:实例运行于health模式,其对入站请求仅响应“OK”信息并关闭连接,
#### 且不会记录任何日志信息 ,此模式将用于相应外部组件的监控状态检测请求
# option httplog #如果是mode http则使用这个
option abortonclose
retries 3
option redispatch ## serverId对应的服务器挂掉后,强制定向到其他健康的服务器
maxconn 2000 ## 前端的最大并发连接数(默认为2000)
### 其不能用于backend区段,对于大型站点来说,可以尽可能提高此值以便让haproxy管理连接队列,
### 从而避免无法应答用户请求。当然,此最大值不能超过“global”段中的定义。
### 此外,需要留心的是,haproxy会为每个连接维持两个缓冲,每个缓存的大小为8KB,
### 再加上其他的数据,每个连接将大约占用17KB的RAM空间,这意味着经过适当优化后 ,
### 有着1GB的可用RAM空间时将维护40000-50000并发连接。
### 如果指定了一个过大值,极端场景中,其最终所占据的空间可能会超过当前主机的可用内存,
### 这可能会带来意想不到的结果,因此,将其设定一个可接受值放为明智绝对,其默认为2000
timeout connect 5000ms ## 连接超时(默认是毫秒,单位可以设置us,ms,s,m,h,d)
timeout client 50000ms ## 客户端超时
timeout server 50000ms ## 服务器超时
## HAProxy的状态信息统计页面
listen proxy_status
bind :48066 ## 绑定端口
mode tcp
balance roundrobin ## 定义负载均衡算法,可用于"defaults"、"listen"和"backend"中,默认为轮询方式
server mycat_1 192.168.140.128:8066 check inter 10s
server mycat_2 192.168.140.127:8066 check inter 10s
frontend admin_stats
bind :7777 ## 绑定端口
mode http
stats enable ##统计页面
option httplog ## 启用日志记录HTTP请求
maxconn 10
stats refresh 30s
stats auth admin:123123 ## 设置统计页面认证的用户和密码,如果要设置多个,另起一行写入即可
stats hide-version
stats admin if TRUE
## listen: 用于定义通过关联“前端”和“后端”一个完整的代理,通常只对TCP流量有用
#listen mycat_servers
#bind :3307 ## 绑定端口
#mode tcp
#option tcplog ## 记录TCP请求日志
#option tcpka ## 是否允许向server和client发送keepalive
#option httpchk OPTIONS * HTTP/1.1\r\nHost:\ www ## 后端服务状态检测
### 向后端服务器的48700端口(端口值在后端服务器上通过xinetd配置)发送 OPTIONS 请求
### (原理请参考HTTP协议) ,HAProxy会根据返回内容来判断后端服务是否可用.
### 2xx 和 3xx 的响应码表示健康状态,其他响应码或无响应表示服务器故障。
#balance roundrobin ## 定义负载均衡算法,可用于"defaults"、"listen"和"backend"中,默认为轮询方式
#server mycat_01 192.168.209.133:8066 check port 48700 inter 2000ms rise 2 fall 3 weight 10
#server mycat_02 192.168.209.134:8066 check port 48700 inter 2000ms rise 2 fall 3 weight 10
## 格式:server <name> <address>[:[port]] [param*]
### serser 在后端声明一个server,只能用于listen和backend区段。
### <name>为此服务器指定的内部名称,其将会出现在日志及警告信息中
### <address>此服务器的IPv4地址,也支持使用可解析的主机名,但要在启动时需要解析主机名至响应的IPV4地址
### [:[port]]指定将客户端连接请求发往此服务器时的目标端口,此为可选项
### [param*]为此server设定的一系列参数,均为可选项,参数比较多,下面仅说明几个常用的参数:
#### weight:权重,默认为1,最大值为256,0表示不参与负载均衡
#### backup:设定为备用服务器,仅在负载均衡场景中的其他server均不可以启用此server
#### check:启动对此server执行监控状态检查,其可以借助于额外的其他参数完成更精细的设定
#### inter:设定监控状态检查的时间间隔,单位为毫秒,默认为2000,
##### 也可以使用fastinter和downinter来根据服务器端专题优化此事件延迟
#### rise:设置server从离线状态转换至正常状态需要检查的次数(不设置的情况下,默认值为2)
#### fall:设置server从正常状态转换至离线状态需要检查的次数(不设置的情况下,默认值为3)
#### cookie:为指定server设定cookie值,此处指定的值将会在请求入站时被检查,
##### 第一次为此值挑选的server将会被后续的请求所选中,其目的在于实现持久连接的功能
#### maxconn:指定此服务器接受的最大并发连接数,如果发往此服务器的连接数目高于此处指定的值,
#####其将被放置于请求队列,以等待其他连接被释放
- 登录验证

(4)keepalived搭建步骤















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









