







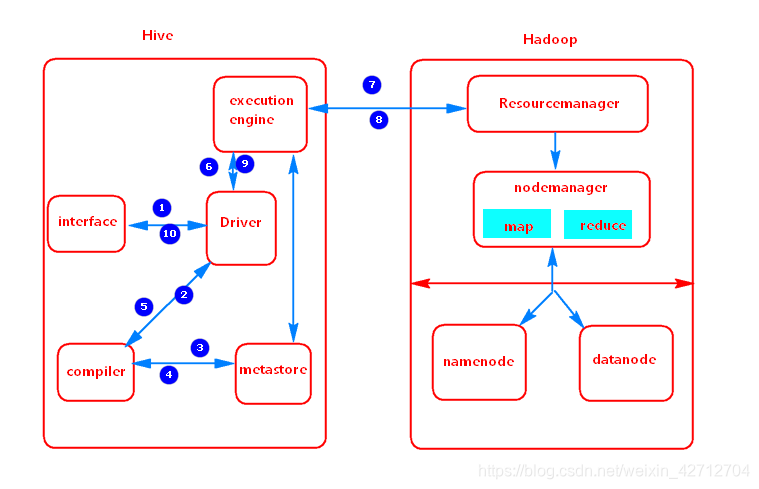
1、interface 指的是Hive的用户接口,也就是client
2、client将 hql提交到Hive的 Driver,Driver查询编译器,分析查询语法和查询计划或者查询要求,然后发送给compiler
3、compiler发送给元数据请求到metastore,查看需要的表,字段等是否存在。
4、metastore响应编译器的元数据请求,如果满足要求就返回结果给compiler,否则返回错误信息给用户接口
5、compiler重新检查要求,完全编译,然后发送执行计划给Driver。
6、Driver收到后发送执行计划给 execution engine
7、execution engine 会执行一个MR任务 执行时,有可能会通过metastore执行元数据操作
8、Driver端 接收数据节点的结果
9、Driver端 将结果值返回给client














12-23
 7619
7619
7619
04-25
09-03
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









