







 介绍遗传算法原理,探讨其在旅行商问题(TSP)中的应用,包括编码、交叉、变异等核心设计,分享完整程序源码。
介绍遗传算法原理,探讨其在旅行商问题(TSP)中的应用,包括编码、交叉、变异等核心设计,分享完整程序源码。
TSP问题——GA(遗传算法)解法
1、遗传算法简介
遗传算法(英语:genetic algorithm (GA) )是计算数学中用于解决最优化的搜索算法,是进化算法的一种。进化算法最初是借鉴了进化生物学中的一些现象而发展起来的,这些现象包括遗传、突变、自然选择以及杂交等。
在遗传算法里,优化问题的解被称为个体,它表示为一个变量序列,叫做染色体或者基因串。染色体一般被表达为简单的字符串或数字符串,不过也有其他的依赖于特殊问题的表示方法适用,这一过程称为编码。首先,算法随机生成一定数量的个体,有时候操作者也可以干预这个随机产生过程,以提高初始种群的质量。在每一代中,都会评价每一个体,并通过计算适应度函数得到适应度数值。按照适应度排序种群个体,适应度高的在前面。这里的“高”是相对于初始的种群的低适应度而言。
下一步是产生下一代个体并组成种群。这个过程是通过选择和繁殖完成,其中繁殖包括交配(crossover,在算法研究领域中我们称之为交叉操作)和突变(mutation)。选择则是根据新个体的适应度进行,但同时不意味着完全以适应度高低为导向,因为单纯选择适应度高的个体将可能导致算法快速收敛到局部最优解而非全局最优解,我们称之为早熟。作为折中,遗传算法依据原则:适应度越高,被选择的机会越高,而适应度低的,被选择的机会就低。初始的数据可以通过这样的选择过程组成一个相对优化的群体。之后,被选择的个体进入交配过程。一般的遗传算法都有一个交配概率(又称为交叉概率),范围一般是0.6~1,这个交配概率反映两个被选中的个体进行交配的概率。例如,交配概率为0.8,则80%的“夫妻”会生育后代。每两个个体通过交配产生两个新个体,代替原来的“老”个体,而不交配的个体则保持不变。交配父母的染色体相互交换,从而产生两个新的染色体,第一个个体前半段是父亲的染色体,后半段是母亲的,第二个个体则正好相反。不过这里的半段并不是真正的一半,这个位置叫做交配点,也是随机产生的,可以是染色体的任意位置。再下一步是突变,通过突变产生新的“子”个体。一般遗传算法都有一个固定的突变常数(又称为变异概率),通常是0.1或者更小,这代表变异发生的概率。根据这个概率,新个体的染色体随机的突变,通常就是改变染色体的一个字节(0变到1,或者1变到0)。
经过这一系列的过程(选择、交配和突变),产生的新一代个体不同于初始的一代,并一代一代向增加整体适应度的方向发展,因为总是更常选择最好的个体产生下一代,而适应度低的个体逐渐被淘汰掉。这样的过程不断的重复:评价每个个体,计算适应度,两两交配,然后突变,产生第三代。周而复始,直到终止条件满足为止。一般终止条件有以下几种:
进化次数限制;
(1)计算耗费的资源限制(例如计算时间、计算占用的内存等);
(2)一个个体已经满足最优值的条件,即最优值已经找到;
(3)适应度已经达到饱和,继续进化不会产生适应度更好的个体;
(4)人为干预;
(5)以及以上两种或更多种的组合。
2、遗传算法在TSP问题中的核心设计
利用遗传算法解TSP问题的整个流程如下:
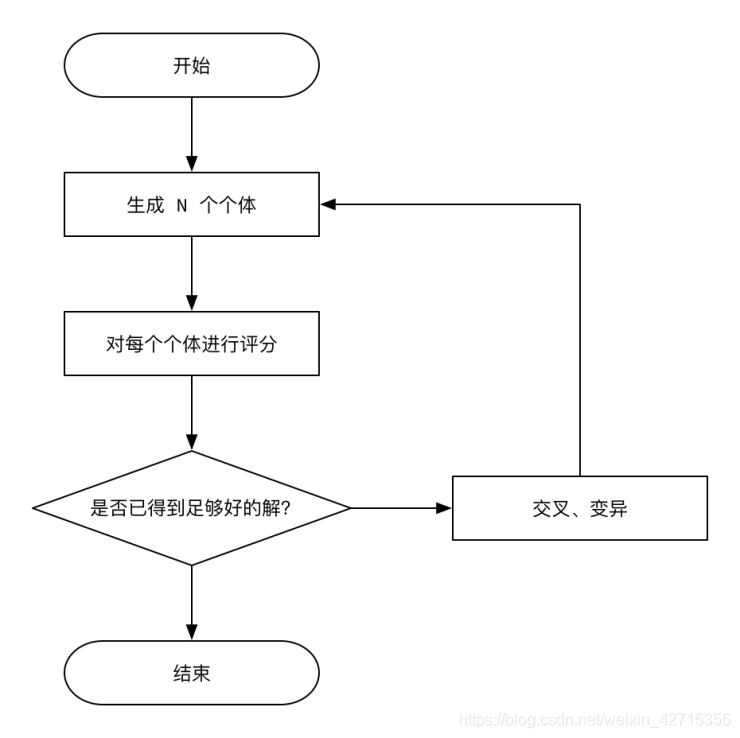
(1)染色体及编码设计:在旅行商问题中,本文采取的是一条染色体就是一条完整的TSP路径,即通过城市号对路径进行编码。
(2)交叉方式:进行交叉时采用的策略是,将parent2的基因段tempGene保存下来,然后对基因1所有序列号g依次进行判断,如果g在tempGene内,则舍去,否则就保存下来,并在第index1的位置插入tempGene。
例如:对以下两个基因进行交叉
parent1=(1,2,3,4,5,6,7,8)
parent2=(5,6,7,8,4,3,2,1)
若随机选择的交叉基因片段 起始地址为:index1=3,结束地址为:index2=5,即parent2对应的基因段tempGene为(8,4,3),将其加入到子基因块的对应位置,此时子基因块为:(x,x,x,8,4,3,x,x)。
然后对parent1的所有基因(1,2,3,4,5,6,7,8)舍去tempGene内的基因后,依次加入到子基因序列中,得到的子基因如下:(1,2,5,8,4,3,6,7)
(3)变异方式:直接在在自身染色体中随机挑选两个基因,然后互换位置。
3、程序源码
程序源码GitHub地址:点击下载
1、GA包:主要封装遗传算法种群信息的GAList类和包含单个个体对象单个个体对象的信息GAUnit类
# -*- coding: utf-8 -*-
"""
遗传算法GA包
Author: Greatpan
Date: 2018.11.13
"""
import random
class GAList(object):
"""
类名:GAList
类说明: 遗传算法类,一个GA类包含了一个种群,及其种群内的信息
"""
def __init__(self, aCrossRate, aMutationRage, aUnitCount, aGeneLenght, aMatchFun=lambda : 1):
""" 构造函数 """
self.crossRate = aCrossRate # 交叉概率 #
self.mutationRate = aMutationRage # 突变概率 #
self.unitCount = aUnitCount # 个体数 #
self.geneLenght = aGeneLenght # 基因长度 #
self.matchFun = aMatchFun # 适配函数
self.population = [] # 种群
self.best = None # 保存这一代中最好的个体
self.generation = 1 # 第几代 #
self.crossCount = 0 # 交叉数量 #
self.mutationCount = 0 # 突变个数 #
self.bounds = 0.0 # 适配值之和,用于选择时计算概率
self.initPopulation() # 初始化种群 #
def initPopulation(self):
"""
函数名:initPopulation(self)
函数功能: 随机初始化得到一个种群
输入 1 self:类自身
输出 1 无
其他说明:无
"""
self.population = []
unitCount = self.unitCount
while unitCount>0:
gene = [x for x in range(self.geneLenght)]
random.shuffle(gene) # 随机洗牌 #
unit = GAUnit(gene)
self.population.append(unit)
unitCount-=1
def judge(self):
"""
函数名:judge(self)
函数功能: 重新计算每一个个体单元的适配值
输入 1 self:类自身
输出 1 无
其他说明:无
"""
self.bounds = 0.0
self.best = self.population[0]
for unit in self.population:
unit.value = self.matchFun(unit)
self.bounds += unit.value
if self.best.value < unit.value: # score为距离的倒数 所以越小越好 #
self.best = unit
def cross(self, parent1, parent2):
"""
函数名:cross(self, parent1, parent2)
函数功能: 根据parent1和parent2基于序列,随机选取长度为n的片段进行交换(n=index2-index1)
输入 1 self:类自身
2 parent1: 进行交叉的双亲1
3 parent2: 进行交叉的双亲2
输出 1 newGene: 通过交叉后的一个新的遗传个体的基因序列号
其他说明:进行交叉时采用的策略是,将parent2的基因段tempGene保存下来,然后对基因1所有序列号g依次进行判断,
如果g在tempGene内,则舍去,否则就保存下来,并在第index1的位置插入tempGene
"""
index1 = random.randint(0, self.geneLenght - 1) # 随机生成突变起始位置 #
index2 = random.randint(index1, self.geneLenght - 1) # 随机生成突变终止位置 #
tempGene = parent2.gene[index1:index2] # 交叉的基因片段
newGene = []
p1len = 0
for g in parent1.gene:
if p1len == index1:
newGene.extend(tempGene) # 插入基因片段
p1len += 1
if g not in tempGene:
newGene.append(g)
p1len += 1
self.crossCount += 1
return newGene
def mutation(self, gene):
"""
函数名:mutation(self, gene)
函数功能: 对输入的gene个体进行变异,也就是随机交换两个位置的基因号
输入 1 self:类自身
2 gene: 进行变异的个体基因序列号
输出 1 newGene: 通过交叉后的一个新的遗传个体的基因序列
其他说明:无
"""
index1 = random.randint(0, self.geneLenght - 1)
index2 = random.randint(0, self.geneLenght - 1)
# 随机选择两个位置的基因交换--变异
newGene = gene[:] # 产生一个新的基因序列,以免变异的时候影响父种群
newGene[index1], newGene[index2] = newGene[index2], newGene[index1]
self.mutationCount += 1
return newGene
def getOneUnit(self):
"""
函数名:getOneUnit(self)
函数功能: 通过轮盘赌法,依据个体适应度大小,随机选择一个个体
输入 1 self:类自身
输出 1 unit:所选择的个体
其他说明:无
"""
r = random.uniform(0, self.bounds)
for unit in self.population:
r -= unit.value
if r <= 0:
return unit
raise Exception("选择错误", self.bounds)
def newChild(self):
"""
函数名:newChild(self)
函数功能: 按照预定的概率进行交叉与变异后产生新的后代
输入 1 self:类自身
输出 1 GAUnit(gene):所产生的后代
其他说明:无
"""
parent1 = self.getOneUnit()
rate = random.random()
# 按概率交叉
if rate < self.crossRate: # 交叉
parent2 = self.getOneUnit()
gene = self.cross(parent1, parent2)
else: # 不交叉
gene = parent1.gene
# 按概率突变
rate = random.random()
if rate < self.mutationRate:
gene = self.mutation(gene)
return GAUnit(gene)
def nextGeneration(self):
"""
函数名:nextGeneration(self)
函数功能: 产生下一代
输入 1 self:类自身
输出 1 无
其他说明:无
"""
self.judge()
newPopulation = [] # 新种群
newPopulation.append(self.best) # 把最好的个体加入下一代 #
while len(newPopulation) < self.unitCount:
newPopulation.append(self.newChild())
self.population = newPopulation
self.generation += 1
class GAUnit(object):
"""
类名:GAUnit
类说明: 遗传算法个体类
"""
def __init__(self, aGene = None,SCORE_NONE = -1):
""" 构造函数 """
self.gene = aGene # 个体的基因序列
self.value = SCORE_NONE # 初始化适配值
2、TSP类:该类封装了利用GA算法进行对TSP问题求解的过程
# -*- encoding: utf-8 -*-
"""
TSP问题GA求解包
Author: Greatpan
Date: 2018.11.13
"""
from GA import GAList
from MyFuncTool import GetData,ResultShow,draw
class TSP(object):
def __init__(self,Position,Dist,CityNum):
""" 构造函数 """
self.citys=Position # 城市坐标
self.dist=Dist # 城市距离矩阵
self.citynum=CityNum # 城市数量
self.ga =GAList(aCrossRate=0.7, # 交叉率
aMutationRage=0.02, # 突变概率
aUnitCount=100, # 一个种群中的个体数
aGeneLenght=self.citynum, # 基因长度(城市数)
aMatchFun=self.matchFun()) # 适配函数
def distance(self, path):
"""
函数名:distance(self, path)
函数功能: 根据路径求出总路程
输入 1 self:类自身
输入 2 path:路径
输出 1 无
其他说明:无
"""
# 计算从初始城市到最后一个城市的路程
distance = sum([self.dist[city1][city2] for city1,city2 in
zip(path[:self.citynum], path[1:self.citynum+1])])
# 计算从初始城市到最后一个城市再回到初始城市所经历的总距离
distance += self.dist[path[-1]][0]
return distance
def matchFun(self):
"""
函数名:matchFun(self)
函数功能: 定义适配函数,并返回函数句柄
输入 1 self:类自身
输出 1 所定义的适配函数的函数句柄
其他说明:无
"""
return lambda life: 1.0 / self.distance(life.gene)
def run(self, generate=0):
"""
函数名:run(self, n=0)
函数功能: 遗传算法解旅行商问题的运行函数
输入 1 self:类自身
2 generate:种群迭代的代数
输出 1 distance:最小路程
2 self.ga.best.gene:最好路径
3 distance_list:每一代的最好路径列表
其他说明:无
"""
distance_list = []
while generate > 0:
self.ga.nextGeneration()
distance = self.distance(self.ga.best.gene)
distance_list.append(distance)
generate -= 1
return distance,self.ga.best.gene,distance_list
##############################程序入口#########################################
if __name__ == '__main__':
Position,CityNum,Dist = GetData("./data/TSP25cities.tsp")
tsp = TSP(Position,Dist,CityNum)
generate=100
Min_Path,BestPath,distance_list=tsp.run(generate)
# 结果打印
BestPath.append(BestPath[0])
ResultShow(Min_Path,BestPath,CityNum,"GA")
draw(BestPath,Position,"GA",True,range(generate), distance_list)
3、我的函数工具箱模块
# -*- coding: utf-8 -*-
"""
我的工具包模块
Author: Greatpan
Date: 2018.9.30
"""
import pandas
import numpy as np
import math
import matplotlib.pyplot as plt
class Node:
"""
类名:Node
函数功能: 从外界读取城市数据并处理
输入 无
输出 1 Position:各个城市的位置矩阵
2 CityNum:城市数量
3 Dist:城市间距离矩阵
其他说明:无
"""
def __init__(self,CityNum):
"""
函数名:GetData()
函数功能: 从外界读取城市数据并处理
输入 无
输出 1 Position:各个城市的位置矩阵
2 CityNum:城市数量
3 Dist:城市间距离矩阵
其他说明:无
"""
self.visited=[False]*CityNum #记录城市是否走过
self.start=0 #起点城市
self.end=0 #目标城市
self.current=0 #当前所处城市
self.num=0 #走过的城市数量
self.pathsum=0 #走过的总路程
self.lb=0 #当前结点的下界
self.listc=[] #记录依次走过的城市
def GetData(datapath):
"""
函数名:GetData()
函数功能: 从外界读取城市数据并处理
输入 无
输出 1 Position:各个城市的位置矩阵
2 CityNum:城市数量
3 Dist:城市间距离矩阵
其他说明:无
"""
dataframe = pandas.read_csv(datapath,sep=" ",header=None)
Cities = dataframe.iloc[:,1:3]
Position= np.array(Cities) #从城市A到B的距离矩阵
CityNum=Position.shape[0] #CityNum:代表城市数量
Dist = np.zeros((CityNum,CityNum)) #Dist(i,j):城市i与城市j间的距离
#计算距离矩阵
for i in range(CityNum):
for j in range(CityNum):
if i==j:
Dist[i,j] = math.inf
else:
Dist[i,j] = math.sqrt(np.sum((Position[i,:]-Position[j,:])**2))
return Position,CityNum,Dist
def ResultShow(Min_Path,BestPath,CityNum,string):
"""
函数名:GetData()
函数功能: 从外界读取城市数据并处理
输入 无
输出 1 Position:各个城市的位置矩阵
2 CityNum:城市数量
3 Dist:城市间距离矩阵
其他说明:无
"""
print("基于"+string+"求得的旅行商最短路径为:")
for m in range(CityNum):
print(str(BestPath[m])+"—>",end="")
print(BestPath[CityNum])
print("总路径长为:"+str(Min_Path))
print()
def draw(BestPath,Position,title,flag=False,generate=0, distance_list=[]):
"""
函数名:draw(BestPath,Position,title)
函数功能: 通过最优路径将旅行商依次经过的城市在图表上绘制出来
输入 1 BestPath:最优路径
2 Position:各个城市的位置矩阵
3 title:图表的标题
输出 无
其他说明:无
"""
plt.title(title)
plt.plot(Position[:,0],Position[:,1],'bo')
for i,city in enumerate(Position):
plt.text(city[0], city[1], str(i))
plt.plot(Position[BestPath, 0], Position[BestPath, 1], color='red')
plt.show()
if flag:
plt.plot(generate, distance_list)
plt.xlabel('generation')
plt.ylabel('distance')
plt.title('generation--distance')
plt.show()
PS补充:
遗传算法在解决优化问题过程中注意如下(来自维基百科):
(1)遗传算法在适应度函数选择不当的情况下有可能收敛于局部最优,而不能达到全局最优。
(2)初始种群的数量很重要,如果初始种群数量过多,算法会占用大量系统资源;如果初始种群数量过少,算法很可能忽略掉最优解。
(3)对于每个解,一般根据实际情况进行编码,这样有利于编写变异函数和适应度函数(Fitness Function)。
(4)在编码过的遗传算法中,每次变异的编码长度也影响到遗传算法的效率。如果变异代码长度过长,变异的多样性会受到限制;如果变异代码过短,变异的效率会非常低下,选择适当的变异长度是提高效率的关键。
(5)变异率也是一个重要的参数。
(6)对于动态数据,用遗传算法求最优解比较困难,因为染色体种群很可能过早地收敛,而对以后变化了的数据不再产生变化。对于这个问题,研究者提出了一些方法增加基因的多样性,从而防止过早的收敛。其中一种是所谓触发式超级变异,就是当染色体群体的质量下降(彼此的区别减少)时增加变异概率;另一种叫随机外来染色体,是偶尔加入一些全新的随机生成的染色体个体,从而增加染色体多样性。
(7)选择过程很重要,但交叉和变异的重要性存在争议。一种观点认为交叉比变异更重要,因为变异仅仅是保证不丢失某些可能的解;而另一种观点则认为交叉过程的作用只不过是在种群中推广变异过程所造成的更新,对于初期的种群来说,交叉几乎等效于一个非常大的变异率,而这么大的变异很可能影响进化过程。
(8)遗传算法很快就能找到良好的解,即使是在很复杂的解空间中。
(9)遗传算法并不一定总是最好的优化策略,优化问题要具体情况具体分析。所以在使用遗传算法的同时,也可以尝试其他算法,互相补充,甚至根本不用遗传算法。
(10)遗传算法不能解决那些“大海捞针”的问题,所谓“大海捞针”问题就是没有一个确切的适应度函数表征个体好坏的问题,使得算法的进化失去导向。
(11)对于任何一个具体的优化问题,调节遗传算法的参数可能会有利于更好更快收敛,这些参数包括个体数目、交叉率和变异率。例如太大的变异率会导致丢失最优解,而过小的变异率会导致算法过早的收敛于局部最优点。对于这些参数的选择,现在还没有实用的上下限。
(12)适应度函数对于算法的速度和效果也很重要。

















 1901
1901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









