






时间函数
date_format
格式化时间
select date_format('2020-03-10 08:00:00','yyyy-MM-dd') day_format

date_add
对时间进行计算
select date_add('2020-03-11',-10) day

next_day
返回当前天的下星期几
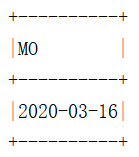
示例:寻找当前天的下星期一
select next_day('2020-03-10','MO') MO
unix_timestamp
传入date_time,返回以秒为单位的时间戳
select unix_timestamp("2020-03-1000:00:00") time1, unix_timestamp("2020-03-10 00:01:00") time2

判断函数
nvl
示例:
select nvl(pv,-1) from table;
当column不为null时,返回其值,否则返回-1
If
示例:
select if(id!=“null”,1,0) id from pv_tab;
如果id 不为空,返回1,否则返回0
跟nvl相比,if的功能更加强大,不仅限于判空操作
且可以通过if( id in (1,2,3), 1, 0 )做一个范围判断
Case when
示例:
select
case id
when '1' then 1
when '2' then 2
else 0
end id
from pv_tab
Case 比if 的功能更加强大,可范围判断,还可根据值的不同返回相应的值
Coalesce
示例:
select
coalesce(id, pv, create_time) as not_null
from pv_tab;
Coalesce可以对多个值进行判空处理,只会返回一个(最左边)不为空的值,
当所有参数都为null时,返回null
行列转换
(多)行转一列
collect_set(去重), collect_list(不去重)
案例:
select
id,
collect_set(column) new_column
from table
group by id
多行转多列
数据:

case when写法
select
name,
avg(case subject when '数学' then score else null end) math,
avg(case subject when '语文' then score else null end) chinese,
avg(case subject when '英语' then score else null end) english
from score
group by name;
聚合函数 + if写法
select
name,
avg(if(subject=‘数学’,score,null)) math,
avg(if(subject=‘语文’,score,null)) chinese,
avg(if(subject=‘英语’,score,null)) english
from score
group by name
在聚合函数中,计算具体字段时不会统计null值,但会统计0值
如下:2次数学共有30分,却除了总量6次

根据需求决定赋予null还是0值
列转行
Hive自带两个函数:
explode函数输入参数为数组或Map, split(column, ‘,’) 可对字符串分割,返回数组,还可自定义UDF, UDTF,UDAF函数。
窗口函数
解释
窗口函数可以数据进行分组,将数据按组分成一个个窗口。
利用窗口函数可以对窗口内的数据进行排序,聚合操作,还可以通过window子句让窗口上下滑动,非常灵活。
排序函数over()
三大排序函数
Row_number() 对每一行表记录生成不重复的序号,每次序号+1;
Rank() 对每一行生成序号,当n条表记录相同,序号相同,下次序号+n;
Dense_rank() 对每一行生成序号,当多条表记录相同,序号相同,下次序号+1;
排序函数常用于组内排序,每组前n名操作,排序函数+开窗需要添加order by
示例:
select
id, pv,
row_number() over(partition by id order by pv desc) row,
rank() over(partition by id order by pv desc) rank,
dense_rank() over(partition by id order by pv desc) drank
from pv_tab

聚合函数over()
不存在order by
select
id, create_time, pv,
sum(pv) over(partition by id) pv_sum
from pv_tab
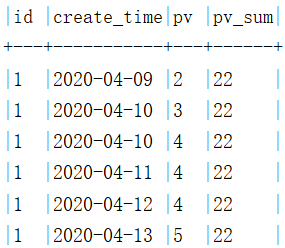
没有order by 的情况下,窗口的大小为首行到末行
存在order by
select
id, create_time, pv,
sum(pv) over(partition by id order by create_time) pv_sum
from pv_tab
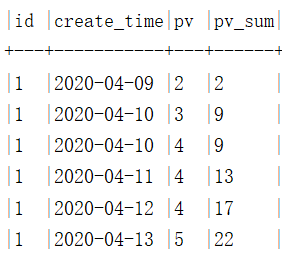
窗口大小为首行到当前行。
若order by 字段存在相同值,
则窗口大小为相同值的最后一行,因此聚合函数会包含所有相同值,
即使当前行还未到窗口最后一行。
Window子句
CURRENT ROW:当前行
n PRECEDING:当前行往前n行开始
n FOLLOWING:当前行往后n行结束
UNBOUNDED PRECEDING:从当前窗口的首行开始
UNBOUNDED FOLLOWING:一直到当前窗口的末行
示例:
select
id, create_time,pv,
-- 首行到当前行
sum(pv) over(partition by id order by create_time
rows between unbounded preceding and current row) pv1,
-- 从当前行往前1行到当前行
sum(pv) over(partition by id order by create_time
rows between 1 preceding and current row) pv2,
-- 当前行到当前行往后一行
sum(pv) over(partition by id order by create_time
rows between current row and 1 following) pv3,
-- 当前行往前1行到当前行往后一行
sum(pv) over(partition by id order by create_time
rows between 1 preceding and 1 following) pv4,
-- 当前行到末行
sum(pv) over(partition by id order by create_time
rows between current row and unbounded following) pv5
from pv_tab
即使order by中存在相同值,但因为current row的限制,聚合时并不会包含所有值,这是与聚合函数不加window子句的区别
使用要领:开窗之后,between … and …

LAG(字段,数值n) over()
也可以LAG(字段,数值n,default) over()
返回当前窗口当前行前面的第n行
select
name,
constellation,
lag(name,1) over(partition by constellation order by name) lag
from person_info;
LEAD(字段,数值n) over()
也可以LEAD(字段,数值n, default) over()
返回当前窗口当前行后面的第n行
select
name,
constellation,
lead(name,1) over(partition by constellation order by name) lead
from person_info;
first_value(字段) over()
返回当前窗口的第一行的值
select
name,
blood_type,
first_value(name) over(partition by blood_type order by name) first
from person_info
对于first_value来说,有无order by 可能会导致当前窗口取值不同
last_value(字段) over()
返回当前窗口末行
select
name,
blood_type,
last_value(name) over(partition by blood_type order by name) last
from person_info
















 9750
9750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











