






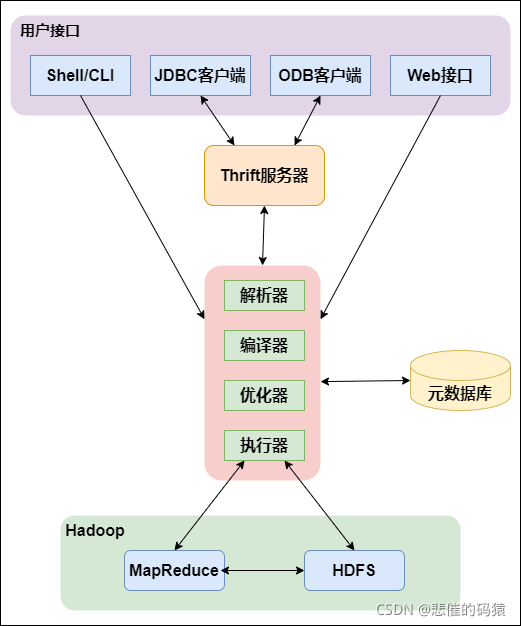
Hive的架构图
一、Hive表类型
1 Hive 数据类型
Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,TIMESTAMP和BINARY。
Hive的集合类型有:STRUCT,MAP和ARRAY。
表的元数据保存传统的数据库的表中,当前hive只支持Derby和MySQL数据库。
2 Hive 分区表
在Hive中,分区表的每一个分区都对应表下的一个目录,所有的分区的数据都存储在对应的目录中。
比如说,分区表partitinTable有包含nation(国家)、ds(日期)和city(城市)3个分区,其中nation = china,ds = 20130506,city = Shanghai则对应HDFS上的目录为:
/datawarehouse/partitinTable/nation=china/city=Shanghai/ds=20130506/。
分区中定义的变量名不能和表中的列相同。
创建分区表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE;
3. Hive 分桶表
桶表就是对指定列进行哈希(hash)计算,然后会根据hash值进行切分数据,将具有不同hash值的数据写到每个桶对应的文件中。
将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。
创建分桶表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级',score SMALLINT COMMOT '总分')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
CLUSTERED BY(user_no) SORTED BY(score) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE;
分桶优点:
- 提高join查询效率
- 提高抽样效率
开启hive的捅表功能
set hive.enforce.bucketing=true;
桶表的数据加载:只能通过insert overwrite 进行加载
所以把文件加载到桶表中,需要先创建普通表,并通过insert overwrite的方式将普通表的数据通过查询的方式加载到桶表当中去
insert overwrite table course select * from course_common cluster by(c_id); -- 最后指定桶字段
4. Hive 视图
与关系数据库不同的是,Hive视图并不存储数据或者实例化。一旦创建 HIve 视图,它的 schema 也会立刻确定下来。对底层表后续的更改视图是识别不到的。如果底层表被删除或者改变,之后对视图的查询将会 failed。
创建视图:
CREATE VIEW employee_skills
AS
SELECT name, skills_score['DB'] AS DB,
skills_score['Perl'] AS Perl,
skills_score['Python'] AS Python,
skills_score['Sales'] as Sales,
skills_score['HR'] as HR
FROM employee;
创建视图的时候是不会触发 MapReduce 的 Job,因为只存在元数据的改变。
但是,当对视图进行查询的时候依然会触发一个 MapReduce Job 进程
以下是对Hive 视图的 DDL操作:
更改视图的属性:
ALTER VIEW employee_skills
SET TBLPROPERTIES ('comment' = 'This is a view');
重新定义视图:
ALTER VIEW employee_skills AS
SELECT * from employee ;
删除视图:
DROP VIEW employee_skills;
二、Hive数据抽样
目前来说有三种方式来进行抽样:随机抽样,桶表抽样,和块抽样。
1 随机抽样
关键词:rand()函数。
使用rand()函数进行随机抽样,limit关键字限制抽样返回的数据,其中rand函数前的distribute和sort关键字可以保证数据在mapper和reducer阶段是随机分布的。
案例如下:
select * from table_name
where col=xxx
distribute by rand() sort by rand()
limit num;
2 块抽样
关键词:tablesample()函数。
tablesample(n percent) 根据hive表数据的大小按比例抽取数据,并保存到新的hive表中。如:抽取原hive表中10%的数据
注意:测试过程中发现,select语句不能带where条件且不支持子查询,可通过新建中间表或使用随机抽样解决。
select * from xxx tablesample(10 percent) 数字与percent之间要有空格
tablesample(nM) 指定抽样数据的大小,单位为M。
select * from xxx tablesample(20M) 数字与M之间不要有空格
tablesample(n rows) 指定抽样数据的行数,其中n代表每个map任务均取n行数据,map数量可通过hive表的简单查询语句确认(关键词:number of mappers: x)
select * from xxx tablesample(100 rows) 数字与rows之间要有空格
3 桶表抽样
关键词:tablesample (bucket x out of y [on colname])。
其中x是要抽样的桶编号,桶编号从1开始,colname表示抽样的列,y表示桶的数量。
例如:将表随机分成10组,抽取其中的第一个桶的数据:
select * from table_01
tablesample(bucket 1 out of 10 on rand())
三、存储与压缩
3.1Hive存储格式
Hive支持的存储数的格式主要有:TEXTFILE(行式存储) 、SEQUENCEFILE(行式存储)、ORC(列式存储)、PARQUET(列式存储)。
3.1.1 TEXTFILE
默认格式,数据不做压缩,磁盘开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压)。TEXTFILE存储格式,采用压缩,hive不会对数据进行切分,从而无法对数据进行并行操作。
3.1.2 ORC格式(也是列式存储)
ORC是在一定程度上扩展了RCFile,是对RCFile的优化。每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
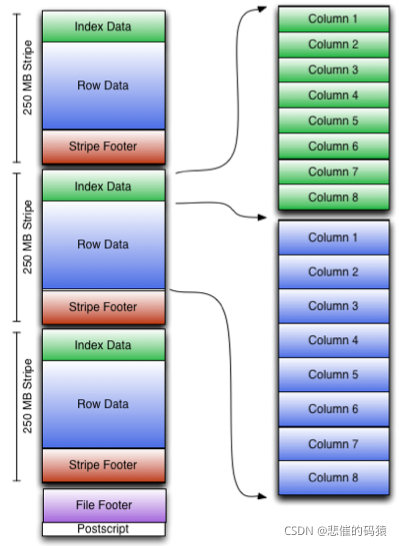
Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。
Stripe Footer:存的是各个stripe的元数据信息
每个文件包含多个stripe,每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
3.1.3 PARQUET格式
Parquet是面向分析型业务的列式存储格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
3.1.4 sequencefile
二进制文件,以<key,value>的形式序列化到文件中,SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
sequencefile 存储空间消耗最大。
3.1.45 RCFile(基本上用ORC取代RCFile)
是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
3.2 Hive压缩格式
3.2.1hadoop支持的解压缩的类:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
hive配置压缩的方式:
3.2.2hive开启map端的压缩方式:
1.1)开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
1.2)开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
1.3)设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
1.4)执行查询语句
select count(1) from score;
3.2.3开启reduce端的压缩方式
1)开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
2)开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3)设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
4)设置mapreduce最终数据输出压缩为块压缩
hive (default)>set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5)测试一下输出结果是否是压缩文件
insert overwrite local directory '/export/servers/snappy' select * from score dist
3.3 存储和压缩相结合(主要列举了Orc)
ORC存储方式的压缩:
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | 高级压缩(可选: NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | 每个压缩块中的字节数 |
| orc.stripe.size | 67,108,864 | 每条stripe中的字节数 |
| orc.row.index.stride | 10,000 | 索引条目之间的行数(必须是>= 1000) |
| orc.create.index | true | 是否创建行索引 |
| orc.bloom.filter.columns | “” | 逗号分隔的列名列表,应该为其创建bloom过滤器 |
| orc.bloom.filter.fpp | 0.05 | bloom过滤器的假阳性概率(必须是>0.0和<1.0) |
创建一个非压缩的ORC存储方式:
1)建表语句
create table log_orc_none(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc tblproperties ("orc.compress"="NONE");
2)插入数据
insert into table log_orc_none select * from log_text ;
3)查看插入后数据
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_none;
结果显示:
7.7 M /user/hive/warehouse/log_orc_none/123456_0
创建一个SNAPPY压缩的ORC存储方式:
1)建表语句
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc tblproperties ("orc.compress"="SNAPPY");
2)插入数据
insert into table log_orc_snappy select * from log_text ;
3)查看插入后数据
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_snappy ;
结果显示:
3.8 M /user/hive/warehouse/log_orc_snappy/123456_0
存储方式和压缩总结:
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy。
3.4 主流存储文件性能对比
数据压缩比结论:
ORC > Parquet > textFile
存储文件的查询效率比较:
ORC > TextFile > Parquet
Hive Sql 大全
四、Hive Sql 大全
4.1.对数据库的操作
创建数据库:
create database if not exists myhive;
说明:hive的表存放位置模式是由hive-site.xml当中的一个属性指定的 :hive.metastore.warehouse.dir
创建数据库并指定hdfs存储位置 :
create database myhive2 location '/myhive2';
修改数据库:
alter database myhive2 set dbproperties('createtime'='20210329');
说明:可以使用alter database 命令来修改数据库的一些属性。但是数据库的元数据信息是不可更改的,包括数据库的名称以及数据库所在的位置
查看数据库基本信息
hive (myhive)> desc database myhive2;
查看数据库更多详细信息
hive (myhive)> desc database extended myhive2;
删除数据库
删除一个空数据库,如果数据库下面有数据表,那么就会报错
drop database myhive2;
强制删除数据库,包含数据库下面的表一起删除
drop database myhive cascade;
4.2 对表的操作
hive建表时候的字段类型:
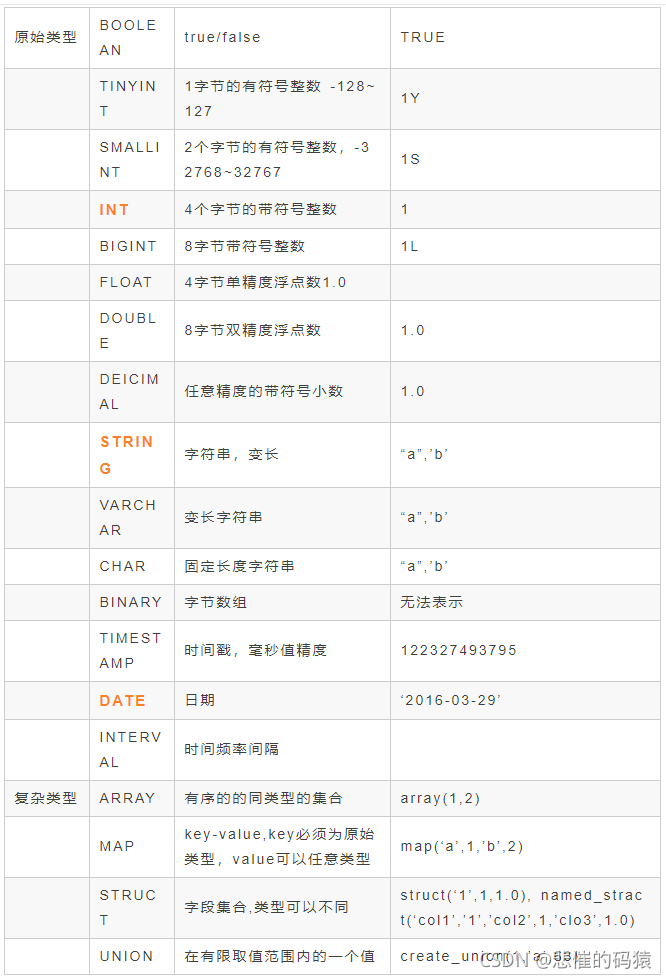
对decimal类型简单解释下:
用法:decimal(11,2) 代表最多有11位数字,其中后2位是小数,整数部分是9位;如果整数部分超过9位,则这个字段就会变成null;如果小数部分不足2位,则后面用0补齐两位,如果小数部分超过两位,则超出部分四舍五入
也可直接写 decimal,后面不指定位数,默认是 decimal(10,0) 整数10位,没有小数
根据查询结果创建表
create table stu3 as select * from stu2;
根据已经存在的表结构创建表
create table stu4 like stu2;
查询表的结构
只查询表内字段及属性
desc stu2;
详细查询
desc formatted stu2;
查询创建表的语句
show create table stu2;
查看分区
show partitions score;
添加分区
alter table score add partition(month='201804') partition(month = '201803');
删除分区
alter table score drop partition(month = '201806');
修改表和删除表
修改表名称
alter table old_table_name rename to new_table_name;
添加列
alter table score5 add columns (mycol string, mysco string);
更新列
alter table score5 change column mysco mysconew int;
删除表操作
drop table score5;
清空表操作
truncate table score6;
说明:只能清空管理表,也就是内部表;清空外部表,会产生错误
注意:truncate 和 drop:
如果 hdfs 开启了回收站,drop 删除的表数据是可以从回收站恢复的,表结构恢复不了,需要自己重新创建;truncate 清空的表是不进回收站的,所以无法恢复truncate清空的表
所以 truncate 一定慎用,一旦清空将无力回天
向hive表中加载数据
直接向分区表中插入数据
insert into table score partition(month ='201807') values ('001','002','100');
通过load方式加载数据
load data local inpath '/export/servers/hivedatas/score.csv' overwrite into table score partition(month='201806');
注意:
1.使用 load data local 表示从本地文件系统加载,文件会拷贝到hdfs上
2.使用 load data 表示从hdfs文件系统加载,文件会直接移动到hive相关目录下,注意不是拷贝过去,因为hive认为hdfs文件已经有3副本了,没必要再次拷贝了
3.如果表是分区表,load 时不指定分区会报错
4.当使用load data数据到分区表中的时候,使用:msck repair table score; 修复表结构
通过查询方式加载数据
insert overwrite table score2 partition(month = ‘201806’) select s_id,c_id,s_score from score1;
import 导入 hive表数据
import table techer2 from ‘/export/techer’;
hive表中数据导出
将查询的结果格式化导出到本地,导出到HDFS上(没有local)
insert overwrite local directory '/export/servers/exporthive' row format delimited fields terminated by '\t' select * from student;
hive shell 命令导出
hive -e "select * from myhive.score;" > /export/servers/exporthive/score.txt
hive -f export.sh > /export/servers/exporthive/score.txt
export导出到HDFS上
export table score to '/export/exporthive/score';
五、Hive小文件过多问题
1.小文件产生原因
直接向表中插入数据
insert into table A values (1,'zhangsan',88),(2,'lisi',61);
这种方式每次插入时都会产生一个文件,多次插入少量数据就会出现多个小文件,但是这种方式生产环境很少使用,可以说基本没有使用的
通过load方式加载数据
load data local inpath '/export/score.csv' overwrite into table A -- 导入文件
load data local inpath '/export/score' overwrite into table A -- 导入文件夹
使用 load 方式可以导入文件或文件夹,当导入一个文件时,hive表就有一个文件,当导入文件夹时,hive表的文件数量为文件夹下所有文件的数量
通过查询方式加载数据
insert overwrite table A select s_id,c_name,s_score from B;
这种方式是生产环境中常用的,也是最容易产生小文件的方式
insert 导入数据时会启动 MR 任务,MR中 reduce 有多少个就输出多少个文件
所以, 文件数量=ReduceTask数量*分区数
也有很多简单任务没有reduce,只有map阶段,则
文件数量=MapTask数量*分区数
每执行一次 insert 时hive中至少产生一个文件,因为 insert 导入时至少会有一个MapTask。
像有的业务需要每10分钟就要把数据同步到 hive 中,这样产生的文件就会很多。
2.小文件过多产生的影响
首先对底层存储HDFS来说,HDFS本身就不适合存储大量小文件,小文件过多会导致namenode元数据特别大, 占用太多内存,严重影响HDFS的性能
对 hive 来说,在进行查询时,每个小文件都会当成一个块,启动一个Map任务来完成,而一个Map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的Map数量是受限的。
3.怎么解决小文件过多
1. 使用 hive 自带的 concatenate 命令,自动合并小文件
#对于非分区表
alter table A concatenate;
#对于分区表
alter table B partition(day=20201224) concatenate;
注意:
1、concatenate 命令只支持 RCFILE 和 ORC 文件类型。
2、使用concatenate命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令。
3、当多次使用concatenate后文件数量不在变化,这个跟参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小size。
2. 调整参数减少Map数量
#执行Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的 CombineFileInputFormat 方法
#此方法是在mapper中将多个文件合成一个split作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认
#每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000; -- 256M
#一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000; -- 100M
#一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000; -- 100M
设置map输出和reduce输出进行合并的相关参数:
#设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
#设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
#设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000; -- 256M
#当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; -- 16M
启用压缩
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
3. 减少Reduce的数量
#reduce 的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量,
#hive中的分区函数 distribute by 正好是控制MR中partition分区的,
#然后通过设置reduce的数量,结合分区函数让数据均衡的进入每个reduce即可。
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;
#第二种是设置每个reduce的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=5120000000; -- 默认是1G,设置为5G
#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;
insert overwrite table A partition(dt)
select * from B
distribute by rand();
解释:如设置reduce数量为10,则使用 rand(), 随机生成一个数 x % 10 ,
这样数据就会随机进入 reduce 中,防止出现有的文件过大或过小
4. 使用hadoop的archive将小文件归档
Hadoop Archive简称HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问
#用来控制归档是否可用
set hive.archive.enabled=true;
#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;
#控制需要归档文件的大小
set har.partfile.size=1099511627776;
#使用以下命令进行归档
ALTER TABLE A ARCHIVE PARTITION(dt='2020-12-24', hr='12');
#对已归档的分区恢复为原文件
ALTER TABLE A UNARCHIVE PARTITION(dt='2020-12-24', hr='12');
注意:
归档的分区可以查看不能 insert overwrite,必须先 unarchive
六、Hive数据倾斜
发生数据倾斜的原因有两种:一是任务中需要处理大量相同的key的数据。二是任务读取不可分割的大文件。一个任务中,数据文件在进入map阶段之前会进行切分,默认是128M一个数据块,但是如果当对文件使用GZIP压缩等不支持文件分割操作的压缩方式时,MR任务读取压缩后的文件时,是对它切分不了的,该压缩文件只会被一个任务所读取,如果有一个超大的不可切分的压缩文件被一个map读取时,就会发生map阶段的数据倾斜。
1. 空值引发的数据倾斜
实际业务中有些大量的null值或者一些无意义的数据参与到计算作业中,表中有大量的null值,如果表之间进行join操作,就会有shuffle产生,这样所有的null值都会被分配到一个reduce中,必然产生数据倾斜。
解决方案:
第一种:可以直接不让null值参与join操作,即不让null值有shuffle阶段
SELECT *
FROM log a
JOIN users b
ON a.user_id IS NOT NULL
AND a.user_id = b.user_id
UNION ALL
SELECT *
FROM log a
WHERE a.user_id IS NULL;
第二种:因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值,这样它们的hash结果就不一样,就会进到不同的reduce中:
SELECT *
FROM log a
LEFT JOIN users b ON CASE
WHEN a.user_id IS NULL THEN concat('hive_', rand())
ELSE a.user_id
END = b.user_id;
2. 不同数据类型引发的数据倾斜
对于两个表join,表a中需要join的字段key为int,表b中key字段既有string类型也有int类型。当按照key进行两个表的join操作时,默认的Hash操作会按int型的id来进行分配,这样所有的string类型都被分配成同一个id,结果就是所有的string类型的字段进入到一个reduce中,引发数据倾斜。
解决方案:
如果key字段既有string类型也有int类型,默认的hash就都会按int类型来分配,那我们直接把int类型都转为string就好了,这样key字段都为string,hash时就按照string类型分配了:
SELECT *
FROM users a
LEFT JOIN logs b ON a.usr_id = CAST(b.user_id AS string);
3. 不可拆分大文件引发的数据倾斜
当集群的数据量增长到一定规模,有些数据需要归档或者转储,这时候往往会对数据进行压缩;当对文件使用GZIP压缩等不支持文件分割操作的压缩方式,在日后有作业涉及读取压缩后的文件时,该压缩文件只会被一个任务所读取。如果该压缩文件很大,则处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,该Map任务会成为作业运行的瓶颈。这种情况也就是Map读取文件的数据倾斜。
解决方案:
这种数据倾斜问题没有什么好的解决方案,只能将使用GZIP压缩等不支持文件分割的文件转为bzip和zip等支持文件分割的压缩方式。
4. 表连接时引发的数据倾斜
两表进行普通的repartition join时,如果表连接的键存在倾斜,那么在 Shuffle 阶段必然会引起数据倾斜。
解决方案:
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率。
hive.auto.convert.join=true 默认值为true,自动开启MAPJOIN优化。
hive.mapjoin.smalltable.filesize=2500000 默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中。
注意:使用默认启动该优化的方式如果出现莫名其妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化:
hive.auto.convert.join=false (关闭自动MAPJOIN转换操作)
hive.ignore.mapjoin.hint=false (不忽略MAPJOIN标记)
再提一句:将表放到Map端内存时,如果节点的内存很大,但还是出现内存溢出的情况,我们可以通过这个参数 mapreduce.map.memory.mb 调节Map端内存的大小。
七、Hive注意事项
1.Hive分区表插入数据时注意事项
insert overwrite table 表1
partition (cnty = 'US', st = 'CA')
select * from 表2 e
where e.country = 'US' and e.state = 'CA';
表1和表2都一样,创建表时有两个字段,两个分区,但是以上插入数据时会出现问题,正确的应该是:
insert overwrite table 表1
partition (cnty = 'US', st = 'CA')
select e.列1,e.列2 from 表2 e
where e.country = 'US' and e.state = 'CA';
分区表实际字段应该是两个,但是查询时是由四个字段的,select * 查询出来有4个字段,往表1中插入数据所以出现问题。
2.处理时间字段的格式2018-01-21,不是带-的时间格式需要转化下
3.Hive支持 IN, NOT IN。不支持EXIST ,NOT EXIST
4.sqoop在从hive分区表导出数据的时候,是不会导出分区列的,mysql建表时去掉分区字段,分区字段是虚拟的,虽然显示出来,但并没有真实存在。有分区的时候各项问题多加注意
5.Hive中string类型也可以进行数据大小比较
cast(ptime as string)) < 4
Between “2018-02-12” and “2018-02-18”
“12”<= “22”















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











