






版本选择:
| 组件 | version |
|---|---|
| spark | 2.4.4 |
| JDK | 1.8.0_192-b12 |
| Scala | 2.12.10 |
| hive | 1.2.1 |
| zookeper | 3.4.5 |
安装:
Scala安装
Scala 解压到指定目录
tar -xvf scala-2.12.10.tar.gz -C $SCALA_HOME/
配置环境变量:
vim /etc/profile
追加以下文本:
SCALA_HOME=$SCALA_HOME
export PATH=...:$SCALA_HOME/bin
刷新profile
soures /etc/profile
Scala测试
scala
 scala安装成功!
scala安装成功!
hive安装(前提MySQL已安装)
解压hive包到指定目录
tar -xvf hive-1.2.1.tar.gz -C $HIVE_HOME/
配置MySQL服务器地址
cd $HIVE_HOME/conf
vim hive-site.xml
配置内容:
<configuration>
#MySQL远程地址
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.160.121:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
#jdbc驱动
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
#登录用户
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
#密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
配置Hadoop与hive
vim hive-env.sh
HADOOP_HOME=$HADOOP_HOME
export HIVE_CONF_DIR=$HIVE_HOME/conf
配置hive环境变量
vim /etc/profile
追加以下文本:
SCALA_HOME=$HIVE_HOME
export PATH=...:$HIVE_HOME/bin
刷新profile
soures /etc/profile
测试:
 已自动创建hive表:
已自动创建hive表:

spark安装
压缩包解压到指定目录
tar -xvf spark-2.4.4-bin-hadoop2.7.tar.gz -C $SPARK_HOME
配置Scala运行环境、jdk配置、hive配置、zk配置…
cd $SPARK_HOME/conf
vim spark-env.sh
export JAVA_HOME=/home/hadoop/apps/jdk8
export SCALA_HOME=/usr/local/scala-2.12.10
export HADOOP_HOME=/home/hadoop/apps/hadoop
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop/etc/hadoop
export SPARK_WORKER_MEMORY=500m
export SPARK_WORKER_CORES=1
export YARN_CONF_DIR=/home/hadoop/apps/hadoop/etc/hadoop
#单Mater模式
#export SPARK_MASTER_IP=hadoop04
#容灾模式
#-Dspark.deploy.recoverMode=ZOOKEEPER #代表发生故障使用zookeeper服务
#-Dspark.depoly.zookeeper.url=master.hadoop,slave1.hadoop,slave1.hadoop #连接地址
#-Dspark.deploy.zookeeper.dir=/spark #spark要在zookeeper上写数据时的保存目录
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.di
r=/home/hadoop/spark"
export SPARK_MASTER_PORT=7077
slaves:配置worker节点
Scala启动测试
集群启动:
$SPARK_HOME/sbin/start-all.sh

shell界面启动:
$SPSRK_HOME/bin/spark-shell
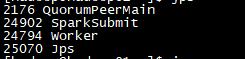
 启动spark-shell后的进程新增
启动spark-shell后的进程新增
24902 SparkSubmit
master web界面检测
ip:8080
 job任务 web界面:
job任务 web界面:
ip:4040
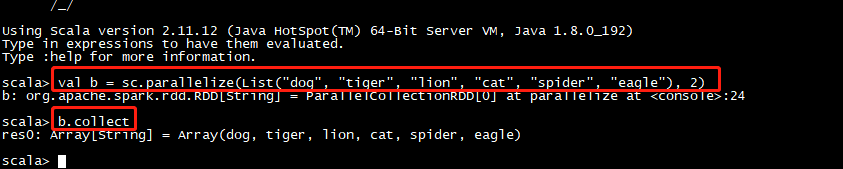
 job提交测试:
job提交测试:
val b = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2)
b.collect
web页面反馈
 这里可以看到job任务(job这里可以看到更多信息)
这里可以看到job任务(job这里可以看到更多信息)
ha模式启动要求
集群启动之后可以看到只有一个worker,这时我们可以在其他master节点启动一个worker
$SPARK_HOME/sbin/start-master.sh
 这里可以看到此节点启动
这里可以看到此节点启动
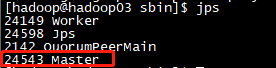
主备切换:
kill 掉master节点
原Alive节点web界面无法登录
 主备切换成功(需要等待一些时间)
主备切换成功(需要等待一些时间)
集群停止:
$SPARK_HOME/sbin/stop-all.sh
















 1583
1583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









