







第8章 Redis原理
8.1 Redis数据结构
8.1.1 RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象。
从Redis的使用者的角度来看,⼀个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key到value的映射关系。
这个映射关系的key是string类型,⽽value可以是多种数据类型,比如:string, list, hash、set、sorted set等。
⽽从Redis内部实现的角度来看,database内的这个映射关系是用⼀个Dict字典来维护的。Dict的key固定用string来表达,而value则比较复杂。因此,为了在同⼀个Dict内能够存储不同类型的value,这就需要⼀个通用的数据结构,这个通用的数据结构就是robj,全名是RedisObject。
RedisObject的源码如下:

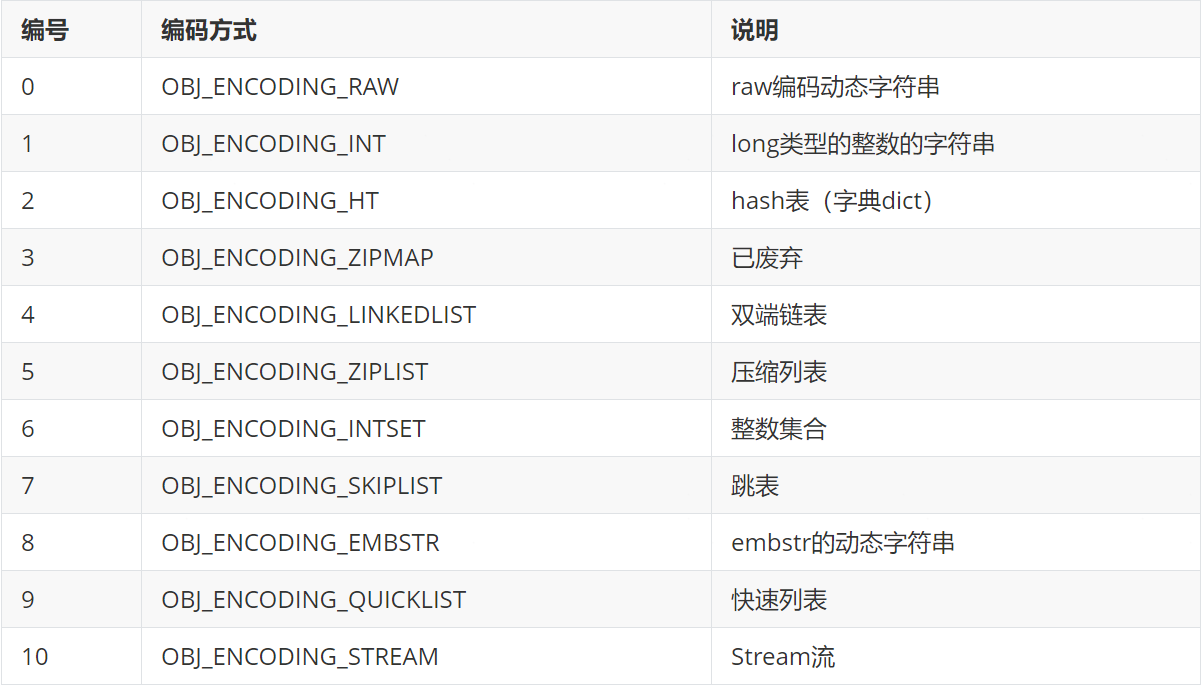
Redis中的编码encoding共包含11种不同类型:
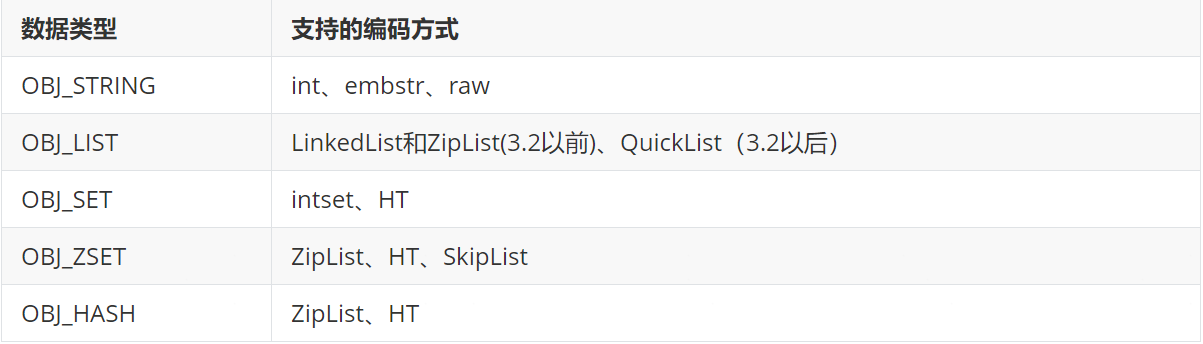
而根据存储的数据类型不同,Redis底层会选择不同的编码方式:
8.1.2 动态字符串(SDS)
字符串是Redis中最常用的一种数据结构。
Redis是C语言实现的,但Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题:获取字符串长度的需要通过运算;非二进制安全(指不能包含二进制数据);不可修改。
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。
SDS是一个结构体,其源码如下:

例如,执行以下命令:
127.0.0.1:6379> set name Jack
OK
Redis将在底层创建两个SDS,其中一个是包含“name”的SDS,另一个是包含“Jack”的SDS。其SDS结构如下:

SDS之所以叫做动态字符串,是因为它具备动态扩容的能力。
例如给上面的字符串追加一段字符串“,hi”,首先会申请新的内存空间:
- 如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1;
- 如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1,称为内存预分配。

相比C语言的字符串,SDS的优点在于:
- 1)获取字符串长度的时间复杂度为O(1)
- 2)支持动态扩容
- 3)减少内存分配次数
- 4)二进制安全
8.1.3 string
string是Redis中最常见的数据存储类型,其底层实现方式是基于简单动态字符串(SDS)或者 long。
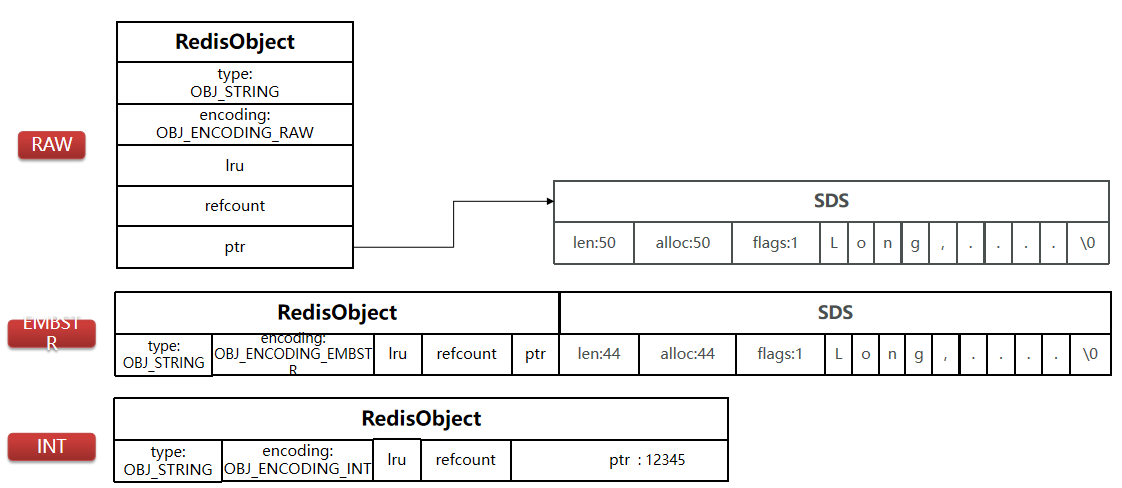
如上图所示,string在Redis中是用⼀个robj来表示的,它可能有编码3种编码:OBJ_ENCODING_RAW、OBJ_ENCODING_EMBSTR、OBJ_ENCODING_INT。
一般情况下,string类型的数据是基于SDS实现的:当SDS的长度小于44字节时,采用OBJ_ENCODING_EMBSTR编码;当SDS的长度大于44字节时,采用OBJ_ENCODING_RAW编码。
但是如果⼀个string类型的数据是数字,那么Redis内部会把它转成long类型来存储,采用OBJ_ENCODING_INT编码,从而减少内存的使用。 并且,如果存储的整数值大小在LONG_MAX范围内,则会直接将数据保存在RedisObject的ptr指针位置(刚好8字节),而不再需要SDS了。
下面是string类型数据的一些运算规则:
-
在对string进行 incr, decr 等操作时,如果它内部是OBJ_ENCODING_INT编码,那么可以直接行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把SDS存储的字符串转成long型,如果能转成功,再进行加减操作。
-
对⼀个内部表示成long型的string执行 append, setbit, getrange 这些命令时,针对的仍然是string的值(即⼗进制表示的字符串),而不是针对内部表⽰的long型进⾏操作。
-
比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令
setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。
8.1.4 List
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素,例如:
127.0.0.1:6379> LPUSH l1 e1 e2 e3
(integer) 3
127.0.0.1:6379> RPUSH l1 e4 e5 e6
(integer) 6
127.0.0.1:6379> LRANGE l1 0 6
1) "e3"
2) "e2"
3) "e1"
4) "e4"
5) "e5"
6) "e6"
127.0.0.1:6379> LPOP l1 1
1) "e3"
127.0.0.1:6379> RPOP l1 1
1) "e6"
能满足上述特征的数据结构有:
- LinkedList:普通链表,可以从双端访问,内存占用较高,内存碎片较多
- ZipList:压缩列表,可以从双端访问,内存占用低,存储上限低
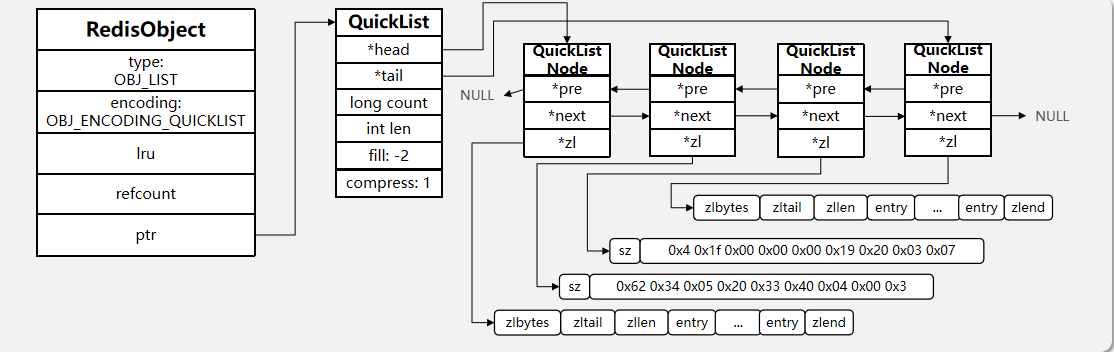
- QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List。其结构如下图:
8.1.5 Set
Set是Redis中的单列集合,满足下列特点:无序;唯一;可以求交集、并集、差集等。
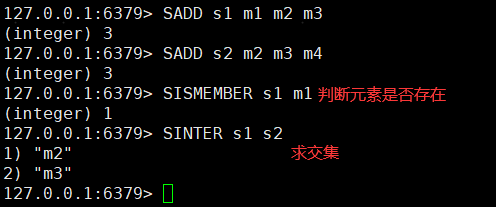
Set对查询元素的效率要求非常高,底层采用Dict来实现,Dict的Key用来存储元素,Value统一为null。
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存。
Set的结构如下:
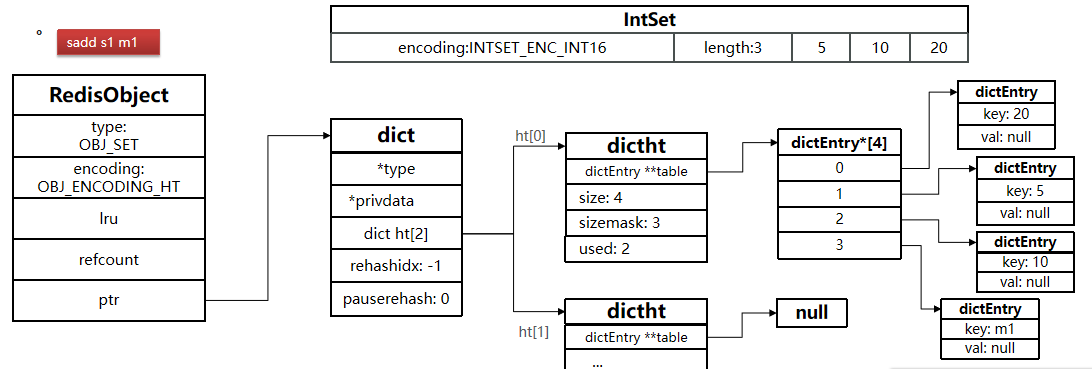
8.1.6 ZSet
ZSet也就是SortedSet,每一个元素都需要指定一个score值和一个member值,它满足下列特点:可以根据score值进行排序;member必须唯一;可以根据member查询分数。
127.0.0.1:6379> ZADD z1 10 m1 20 m2 30 m3
(integer) 3
127.0.0.1:6379> ZSCORE z1 m2
"20"
因此,ZSet底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求,满足条件的数据结构有:
- SkipList:可以排序,并且可以同时存储score和member值
- HT(Dict):可以键值存储,并且可以根据key找value
ZSet的结构如下:
另外,当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存,此时ZSet会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于
zset_max_ziplist_entries,默认值128 - 每个元素都小于
zset_max_ziplist_value字节,默认值64
由于ZipList本身没有排序功能,而且没有键值对的概念,因此需要通过编码来实现:
- ZipList是连续内存,score和element是紧挨在一起的两个Entry,element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列

8.1.7 Hash
Hash结构与Zset非常类似:
- 都是键值存储
- 都可以根据键获取值
- 键必须唯一
区别如下:
- Zset的键是member,值是score;Hash的键和值都是任意值
- Zset要根据score排序;Hash则无需排序
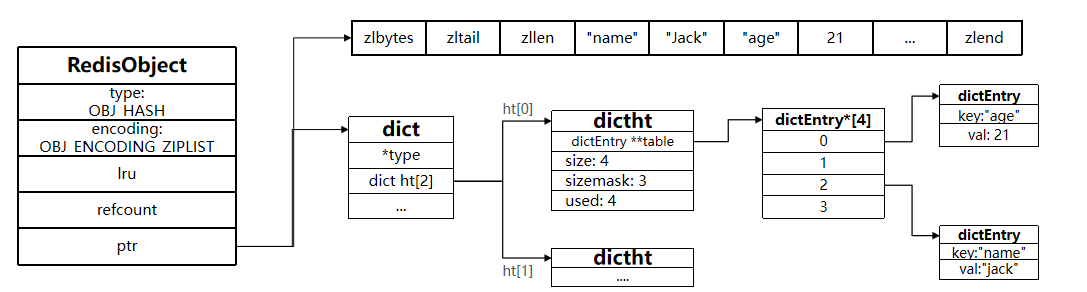
Hash的底层实现方式是压缩列表ZipList或者字典Dict。
当Hash中数据项满足以下两个条件时,Hash底层使用压缩列表ZipList进⾏存储数据:
hash-max-ziplist-entries 512:元素数量不超过512个hash-max-ziplist-value 64:每个元素的大小都小于64KB
随着数据的增加,不再满足这两个条件时,底层的ZipList就可能会转成Dict。
Redis的Hash之所以这样设计,是因为当ZipList变得很⼤时,它有如下几个缺点:
- 每次插⼊或修改引发的realloc操作会有更⼤的概率造成内存拷贝,从而降低性能。
- ⼀旦发生内存拷贝,成本也相应增加,因为要拷贝更⼤的⼀块数据。
- 当ZipList数据项过多时,查找指定的数据项就会性能变得很低,因为ZipList上的查找需要进行遍历。
总之,ZipList本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。⼀旦数据发⽣改动,就会引发内存realloc,可能导致内存拷贝。
Hash的结构如下:
8.2 Redis网络模型
8.2.1 五种网络模型介绍
8.2.1.1 用户空间和内核空间
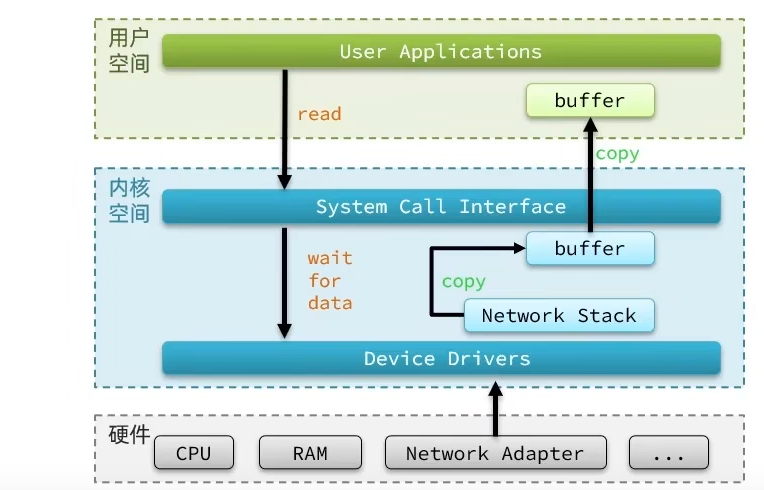
如上图所示,当用户应用程序需要读取硬件上的数据时,会通过接口向内核申请读取数据,而内核需要等到驱动程序从硬件上读取数据。
当从硬件上加载到数据后,内核会将数据写入到内核空间的缓存区,然后再将数据拷贝到用户空间的缓存区,最后返回给应用程序。
8.2.1.2 阻塞IO
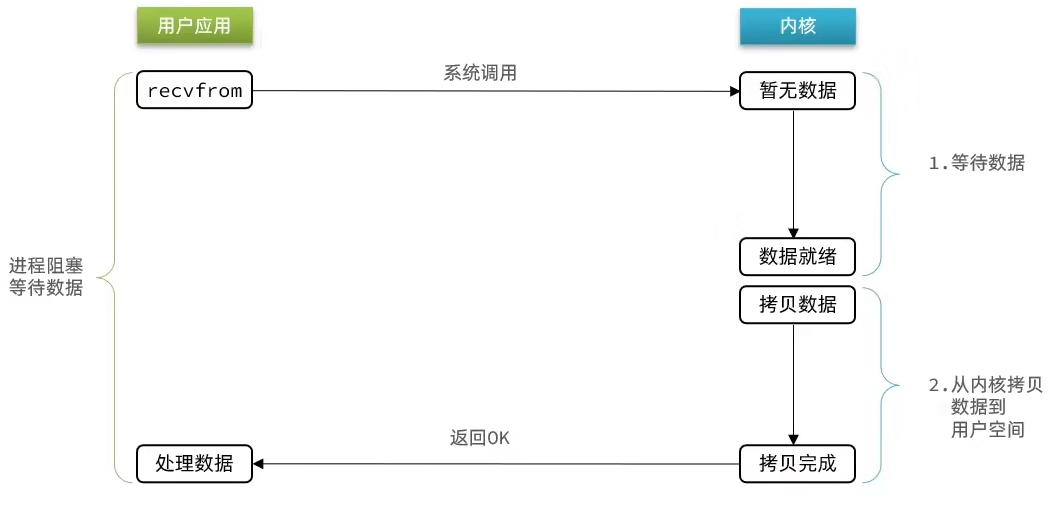
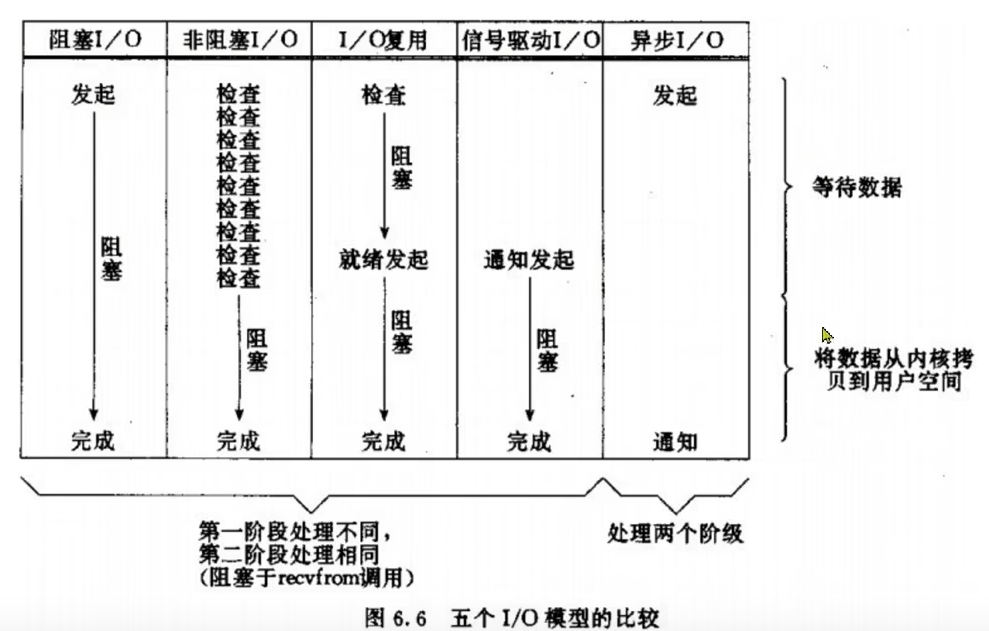
如上图所示,阻塞IO的流程如下:
- 1)用户读取数据时,发起
recvform命令,尝试从内核上加载数据。 - 2)如果内核中没有数据,那么内核就会进入等待状态,并去硬件上读取数据。
- 3)内核读取数据之后,数据准备就绪,然后从内核空间拷贝到用户空间,并且返回ok。
- 4)整个过程,都是阻塞等待的,这就是阻塞IO。
8.2.1.3 非阻塞IO

如上图所示,非阻塞IO的流程如下:
- 1)用户进程要读取数据,发起
recvform命令,尝试从内核上加载数据。 - 2)如果内核中没有数据,那么内核进入等待状态,并去硬件上读取数据;但同时会直接返回异常给用户进程。
- 3)用户进程拿到异常信息后,再次尝试读取数据;如此循环往复,直到数据准备就绪。
- 4)数据准备就绪后,从内核空间拷贝到用户空间,并且返回ok。
可以看到,非阻塞IO模型中,用户进程在第1~3步是非阻塞的,第4步是阻塞的。前面3步虽然是非阻塞,但性能并没有得到提高,而且忙等机制会导致CPU空转,CPU使用率暴增。
8.2.1.4 IO多路复用
无论是阻塞IO还是非阻塞IO,用户应用都需要调用recvfrom来获取数据,差别在于无数据时的处理方案,但两种方式性能都不好:
- 如果恰好没有数据,阻塞IO会使CPU阻塞,非阻塞IO使CPU空转,都不能充分发挥CPU的作用。
- 如果恰好有数据,则用户进程可以直接读取并处理数据。
而在单线程情况下,只能依次处理IO事件,如果正在处理的IO事件恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有IO事件都必须等待,性能自然会很差。
而要提高效率,有以下方案:
方案一:使用多线程
方案二:数据就绪了,用户应用才去读取数据
那么问题来了:用户进程如何知道内核中数据是否就绪呢?
在Linux中,一切皆文件,例如常规文件、视频、硬件设备、网络套接字(Socket)等,都是文件。它们都用文件描述符来关联。
文件描述符(File Descriptor):简称FD,是一个从0开始的无符号整数,用来关联Linux中的一个文件。
通过FD,网络模型就可以利用一个线程监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
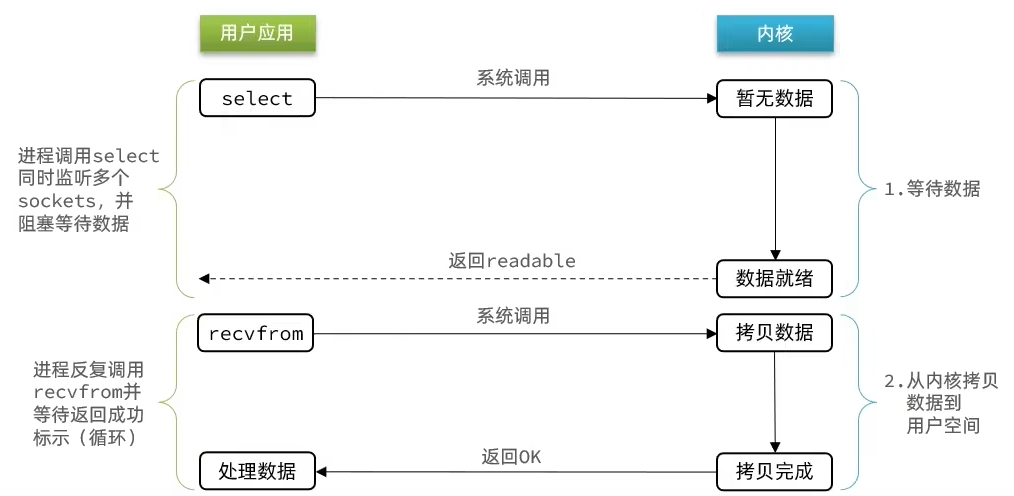
如上图所示,IO多路复用的流程如下:
- 1)用户进程调用
select函数,指定要监听的FD集合,则内核会去监听FD集合对应的多个Socket,用户进程阻塞等待。 - 2)任意一个或多个Socket的数据准备就绪,就返回
readable给用户进程。 - 3)用户进行收到
readable后,找到就绪的Socket,依次调用recvfrom函数读取数据,内核将数据从内核空间拷贝到用户空间,并返回ok。 - 4)用户进行拿到数据后,进行处理数据。
可见,用IO复用模式,可以确保去读数据的时候,数据是一定存在的,它的效率比原来的阻塞IO和非阻塞IO性能都要高。
换句话说,IO多路复用是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
只不过监听FD的方式、通知的方式又有多种实现,常见的有三种:
- 1)select
select是Linux最早使用的I/O多路复用技术,其工作流程是:用户进程执行select函数,会将整个FD集合发给内核,内核遍历用户进行传递过来的FD集合;如果发现数据都没有就绪,则休眠,直到有数据准备好了,再次遍历FD集合找出准备好的数据,并将FD集合返回给用户进程;用户进程接收到FD集合,也去遍历一次得到想要的数据。
可见,这种模式存在频繁地传递FD集合、频繁地遍历FD集合的问题。
- 2)poll
poll模式对select模式做了简单改进,但性能提升不明显,主要的区别在于:
poll模式会创建一个pollfd数组,并将FD集合存放在这个数组中,数组大小可以自定义;调用poll函数后,将pollfd数组拷贝到内核,转链表存储,无上限。
可见,两种模式最主要的区别就是能监听的FD上限不同,select模式固定为1024,而select模式采用链表,理论上无上限。
但必须注意,监听FD越多,每次遍历消耗时间也越久,性能反而会下降。
- 3)epoll
epoll模式是对select和poll的改进,它的工作流程如下:
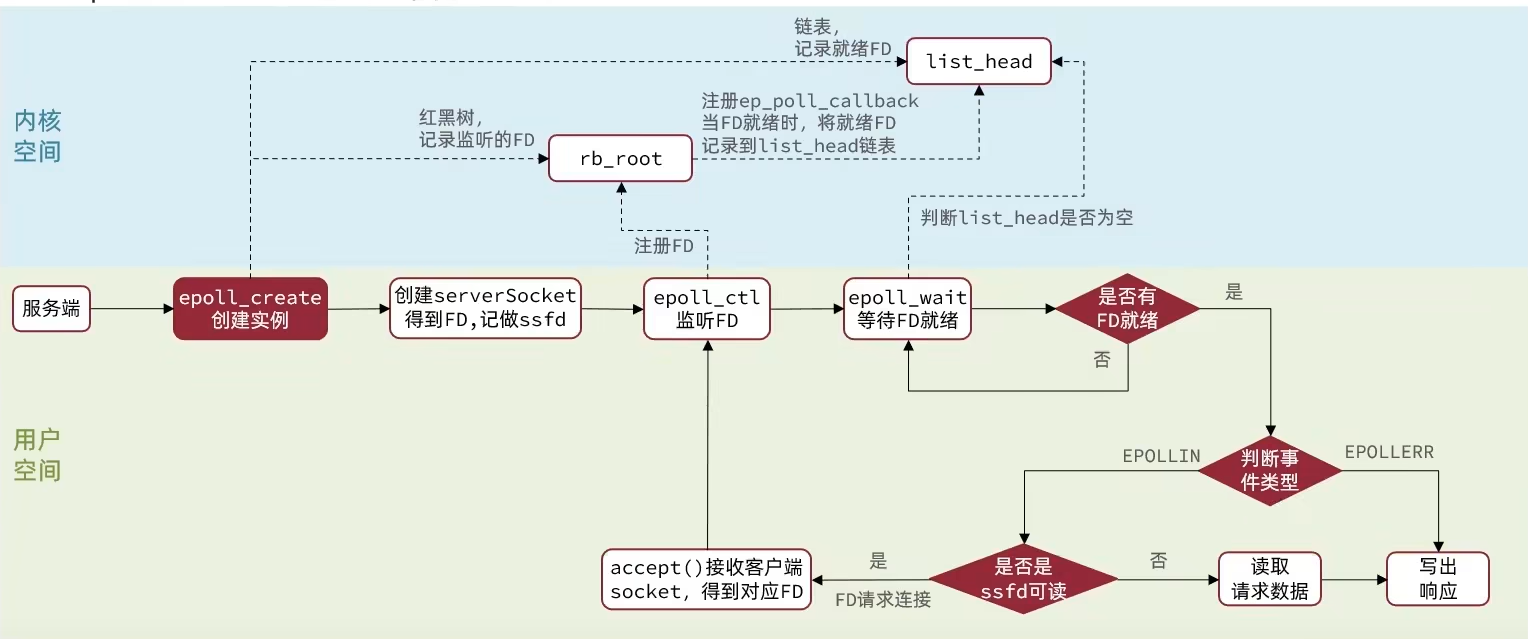
如上图所示,服务启动后,服务端会调用epoll_create,创建一个epoll实例,该实例包含两个数据:
a. rb_root:红黑树,记录要监听的FD;
b. list_head:链表,记录已经就绪的FD。
接着调用epoll_ctl函数,将要监听的FD添加到rb_root红黑树中,并给每个FD设置一个监听回调函数ep_poll_callback。当数据就绪了,回调函数会将就绪的FD就会添加到list_head链表中。
再接着调用epoll_wait函数,该函数会检查list_head链表中是否有已就绪的数据,如果有则进一步判断事件类型。
如果是epollin建立连接事件,则调用accept()函数接收客户端socket,然后建立连接;如果是其他事件,则直接把数据写出。
小结:
select模式存在的三个问题:
- 能监听的FD最大不超过1024
- 每次
select都需要把所有要监听的FD都拷贝到内核空间 - 每次都要遍历所有FD来判断就绪状态
poll模式的问题:
poll利用链表解决了select中监听FD上限的问题,但依然要遍历所有FD,如果监听较多,性能会下降
epoll模式的解决方案:
- 基于
epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高 - 每个FD只需要执行一次
epoll_ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间 - 利用
ep_poll_callback机制来监听FD状态,无需遍历所有FD,因此性能不会随监听的FD数量增多而下降
8.2.1.5 信号驱动IO
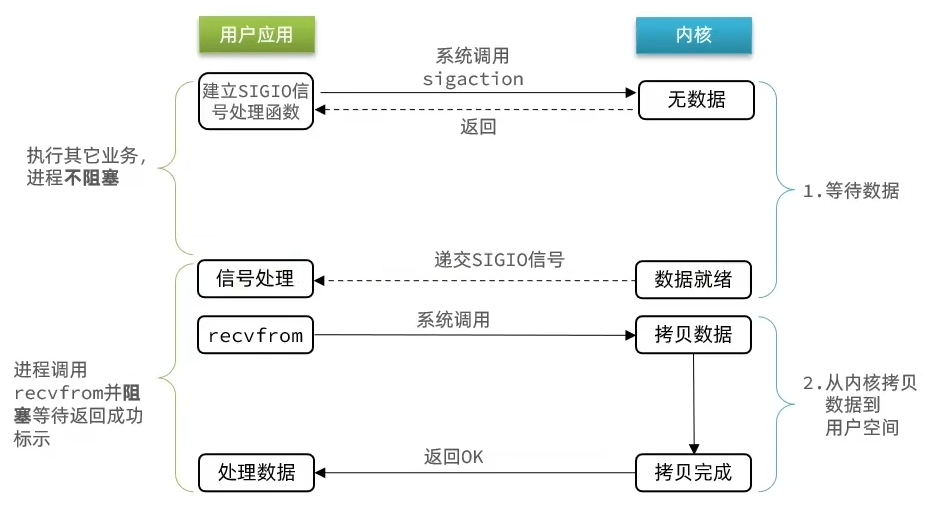
如上图所示,信号驱动IO的流程如下:
- 1)用户进程调用
sigaction,注册信号处理函数;内核直接返回成功,开始监听FD。 - 2)此时用户进程不阻塞等待,可以执行其它业务;当内核数据就绪后,回调用户进程的SIGIO处理函数。
- 3)用户进程收到SIGIO回调信号,调用
recvfrom函数,内核将数据拷贝到用户空间,用户进程拿到数据并处理。
可见,信号驱动IO是与内核建立SIGIO信号关联并设置回调,当内核有FD就绪时,会发出SIGIO信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
但当有大量IO操作时,信号较多,SIGIO处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
8.2.1.6 异步IO
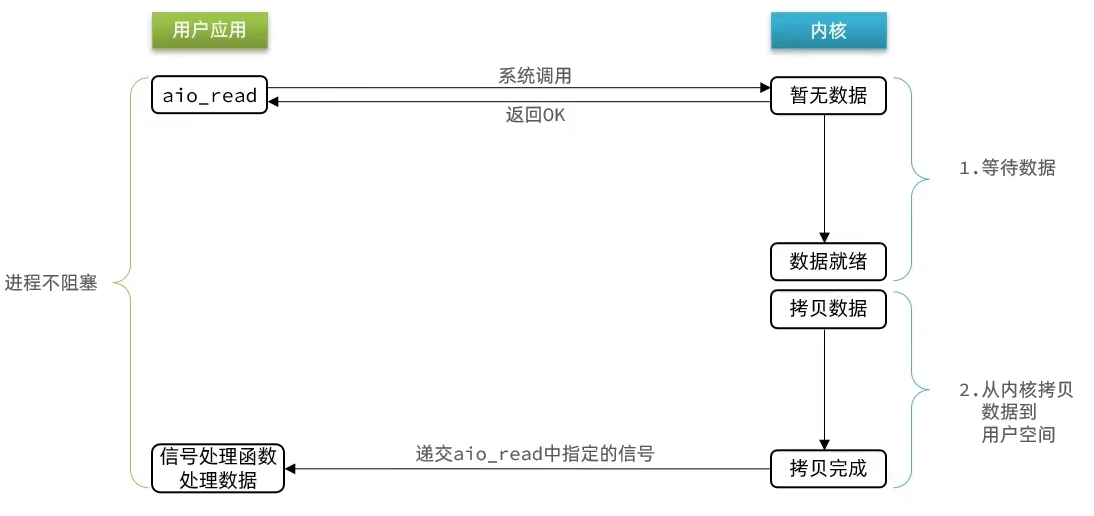
如上图所示,异步IO的流程如下:
- 1)用户进程调用
aio_read,内核直接返回成功,开始监听FD。 - 2)此时用户进程不阻塞等待,可以执行其它业务;当内核数据就绪后,主动将数据从内核拷贝到用户空间,并通知用户进行取数据。
可见,异步IO是内核将所有数据处理完成后,将数据写入到用户空间中,全部都由内核完成,因此性能极高,不会有任何阻塞。
8.2.1.7 对比
8.2.2 Redis的单线程
Redis到底是单线程还是多线程?
- 如果仅仅针对Redis的核心业务部分(命令处理),答案是单线程
- 如果是针对整个Redis,那么答案是多线程
在Redis版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
- Redis v4.0:引入多线程异步处理一些耗时较久的任务,例如异步删除命令
unlink - Redis v6.0:在核心网络模型中引入多线程,进一步提高对于多核CPU的利用率
因此,对于Redis的核心网络模型,在Redis 6.0之前确实都是单线程,是利用epoll这样的IO多路复用技术在事件循环中不断处理客户端情况。
为什么Redis要选择单线程?
- Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销;
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣。
8.3 Redis通信协议
8.3.1 RESP协议
Redis中采用的是RESP(Redis Serialization Protocol)协议,它通过首字节的字符来区分不同数据类型,常用的数据类型包括5种:
| 数据类型 | 首字节 | 举例 | 说明 |
|---|---|---|---|
| 单行字符串 | + | +OK\r\n | 以+开头,后紧跟单行字符串(OK),以CRLF结尾(\r\n) |
| 错误 | - | -Error message\r\n | 以-开头,后紧跟字符串异常信息(Error message),以CRLF结尾(\r\n) |
| 数字 | : | :10\r\n | 以:开头,后紧跟数字字符串(10),以CRLF结尾(\r\n) |
| 多行字符串 | $ | $5\r\nhello\r\n | 以$开头,后紧跟字符串长度(5),以CRLF结尾(\r\n);紧接着是数据部分,一个任意字符串(hello),并同样以CRLF结尾(\r\n)。最大长度512M |
| 数组 | * | *2\r\n :10\r\n $5\r\nhello\r\n | 以*开头,后紧跟数组元素个数(2),以CRLF结尾(\r\n);再跟上元素列表,元素数据类型不限(:10\r\n $5\r\nhello\r\n) |
8.3.2 基于Socket自定义Redis的客户端
Redis支持TCP通信,因此可以使用Socket来模拟客户端,与Redis服务端建立连接:
public class TestClient {
static Socket socket;
static PrintWriter writer;
static BufferedReader reader;
public static void main(String[] args) {
try {
// 1.建立连接
String host = "192.168.146.128";
int port = 6379;
socket = new Socket(host, port);
// 2.获取输出流、输入流
writer = new PrintWriter(new OutputStreamWriter(socket.getOutputStream(), StandardCharsets.UTF_8));
reader = new BufferedReader(new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8));
// 3.获取授权 auth 123321
sendRequest("auth", "123321");
Object obj = handleResponse();
System.out.println("auth 123321 => " + obj);
// 4.测试异常 authaaa 123321
sendRequest("authaaa", "123321");
Object obj2 = handleResponse();
System.out.println("authaaa 123321 => " + obj2);
// 5.测试数字 hset user name Jack age 21
sendRequest("hset", "user", "name", "Jack", "age", "21");
Object obj3 = handleResponse();
System.out.println("hset user name Jack age 21 => " + obj3);
// 6.测试数组和多行字符串 lrange l1 0 6
sendRequest("lrange", "l1", "0", "6");
Object obj4 = handleResponse();
System.out.println("lrange l1 0 6 => " + obj4);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放连接
try {
if(reader != null) reader.close();
if(writer != null) writer.close();
if(socket != null) socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 发送请求
* @author xiaowd
* @since 2024/4/19 15:57
* @param args
* @return void
*/
private static void sendRequest(String ...args) {
writer.println("*" + args.length);
for (String arg : args) {
writer.println("$" + arg.getBytes(StandardCharsets.UTF_8).length);
writer.println(arg);
}
writer.flush();
}
/**
* 处理响应
* @author xiaowd
* @since 2024/4/19 16:11
* @param
* @return java.lang.Object
*/
private static Object handleResponse() throws IOException {
// 1.读取首字节
int prefix = reader.read();
System.out.println("处理响应,首字节为:" + (char)prefix);
// 2.判断首字节
switch (prefix) {
case '+':
// 单行字符串,直接读一行
case '-':
// 异常,也读一行
return reader.readLine();
case ':':
// 数字
return Long.parseLong(reader.readLine());
case '$':
// 多行字符串,先读长度
int len = Integer.parseInt(reader.readLine());
System.out.println("这是一个多行字符串,len = " + len);
if(len == -1) {
// 长度为-1,空
return null;
}
if(len == 0) {
// 长度为0,空字符串
return "";
}
// 其他长度,读一行
return reader.readLine();
case '*':
// 数组
return readBulkString();
default:
throw new RuntimeException("错误的数据格式");
}
}
/**
* 读数组
* @author xiaowd
* @since 2024/4/19 16:10
* @param
* @return java.lang.Object
*/
private static Object readBulkString() throws IOException {
// 1.获取数组大小
int len = Integer.parseInt(reader.readLine());
System.out.println("这是一个数组,len = " + len);
if(len <= 0) {
return null;
}
// 2.读取数据
List<Object> list = new ArrayList<>(len);
for (int i = 0; i < len; i++) {
System.out.println("开始处理数组第" + i +"个元素");
Object obj = handleResponse();
list.add(obj);
System.out.println("结束处理数组第" + i +"个元素:" + obj);
}
return list;
}
}
执行以上main()函数,得到的结果是:
处理响应,首字节为:+
auth 123321 => OK
处理响应,首字节为:-
authaaa 123321 => ERR unknown command 'authaaa', with args beginning with: '123321'
处理响应,首字节为::
hset user name Jack age 21 => 0
处理响应,首字节为:*
这是一个数组,len = 4
开始处理数组第0个元素
处理响应,首字节为:$
这是一个多行字符串,len = 2
结束处理数组第0个元素:e2
开始处理数组第1个元素
处理响应,首字节为:$
这是一个多行字符串,len = 2
结束处理数组第1个元素:e1
开始处理数组第2个元素
处理响应,首字节为:$
这是一个多行字符串,len = 2
结束处理数组第2个元素:e4
开始处理数组第3个元素
处理响应,首字节为:$
这是一个多行字符串,len = 2
结束处理数组第3个元素:e5
lrange l1 0 6 => [e2, e1, e4, e5]
8.4 Redis内存回收
Redis之所以性能强,最主要的原因就是基于内存存储。然而单节点的Redis其内存大小不宜过大,过大会影响持久化或主从同步性能。
通过修改配置文件的maxmemory配置可以设置Redis的最大内存。 当内存使用达到上限时,就无法存储更多数据了。
8.4.1 过期Key的处理
8.4.1.1 expire
通过expire命令可以给Key设置TTL(存活时间):
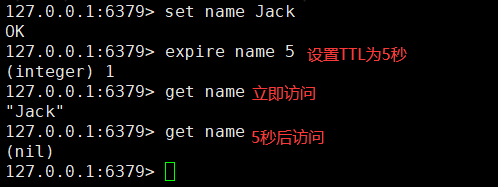
可以发现,当Key的TTL到期以后,再次访问name返回的是nil,说明这个Key已经不存在了,对应的内存也得到释放,从而起到内存回收的目的。
8.4.1.2 惰性删除
在TTL到期后,Redis不会立刻删除Key,而是在下一次访问这个Key的时候,先检查该Key的存活时间,如果已经过期才执行删除,并给客户端返回nil。
8.4.1.3 周期删除
通过一个定时任务,周期性的抽样部分的Key,判断是否过期,如果过期则执行删除。
定期清理的两种模式:SLOW模式执行频率默认为每秒10次,每次不超过25ms;FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms。
Redis的过期删除策略是惰性删除和定期删除两种策略进行配合使用。
8.4.2 内存淘汰策略
内存淘汰就是当Redis内存使用达到设置的上限时,主动挑选部分Key并进行删除,以释放更多内存。
Redis支持8种不同策略来选择要删除的Key:
- noeviction(默认):不淘汰任何Key,但是内存满时不允许写入新数据。
- volatile-ttl:对设置了TTL的Key,比较Key的剩余TTL值,TTL越小越先被淘汰。
- allkeys-random:对全体Key ,随机进行淘汰。
- volatile-random:对设置了TTL的Key ,随机进行淘汰。
- allkeys-lru:对全体Key,基于LRU算法进行淘汰。
- volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰。
- allkeys-lfu:对全体key,基于LFU算法进行淘汰。
- volatile-lfu:对设置了TTL的key,基于LFI算法进行淘汰
注意两个算法概念:
- LRU(Least Recently Used):最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU(Least Frequently Used):最少频率使用。会统计每个Key的访问频率,值越小淘汰优先级越高。
…
本节完,更多内容请查阅分类专栏:Redis从入门到精通
感兴趣的读者还可以查阅我的另外几个专栏:
















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











