







 本文详细介绍了MPI中的全互换操作,包括MPI_Alltoall和MPI_Alltoallv。MPI_Alltoall使得每个进程与所有其他进程进行数据交换,每个进程的发送和接收缓冲区都是由多个数据块组成。MPI_Alltoallv则增加了灵活性,允许指定数据块的位置。通过实例展示了如何使用这两个函数,并解释了它们之间的关系及其特殊情况与一般情况的对应关系。
本文详细介绍了MPI中的全互换操作,包括MPI_Alltoall和MPI_Alltoallv。MPI_Alltoall使得每个进程与所有其他进程进行数据交换,每个进程的发送和接收缓冲区都是由多个数据块组成。MPI_Alltoallv则增加了灵活性,允许指定数据块的位置。通过实例展示了如何使用这两个函数,并解释了它们之间的关系及其特殊情况与一般情况的对应关系。
MPI_Alltoall
在使用MPI_Alltoall时,每一个进程都会向任意一个进程发送消息,每一个进程也都会接收到任意一个进程的消息。每个进程的接收缓冲区和发送缓冲区都是一个分为若干个数据块的数组。MPI_Alltoall的具体操作是:将进程i的发送缓冲区中的第j块数据发送给进程j,进程j将接收到的来自进程i的数据块放在自身接收缓冲区的第i块位置。
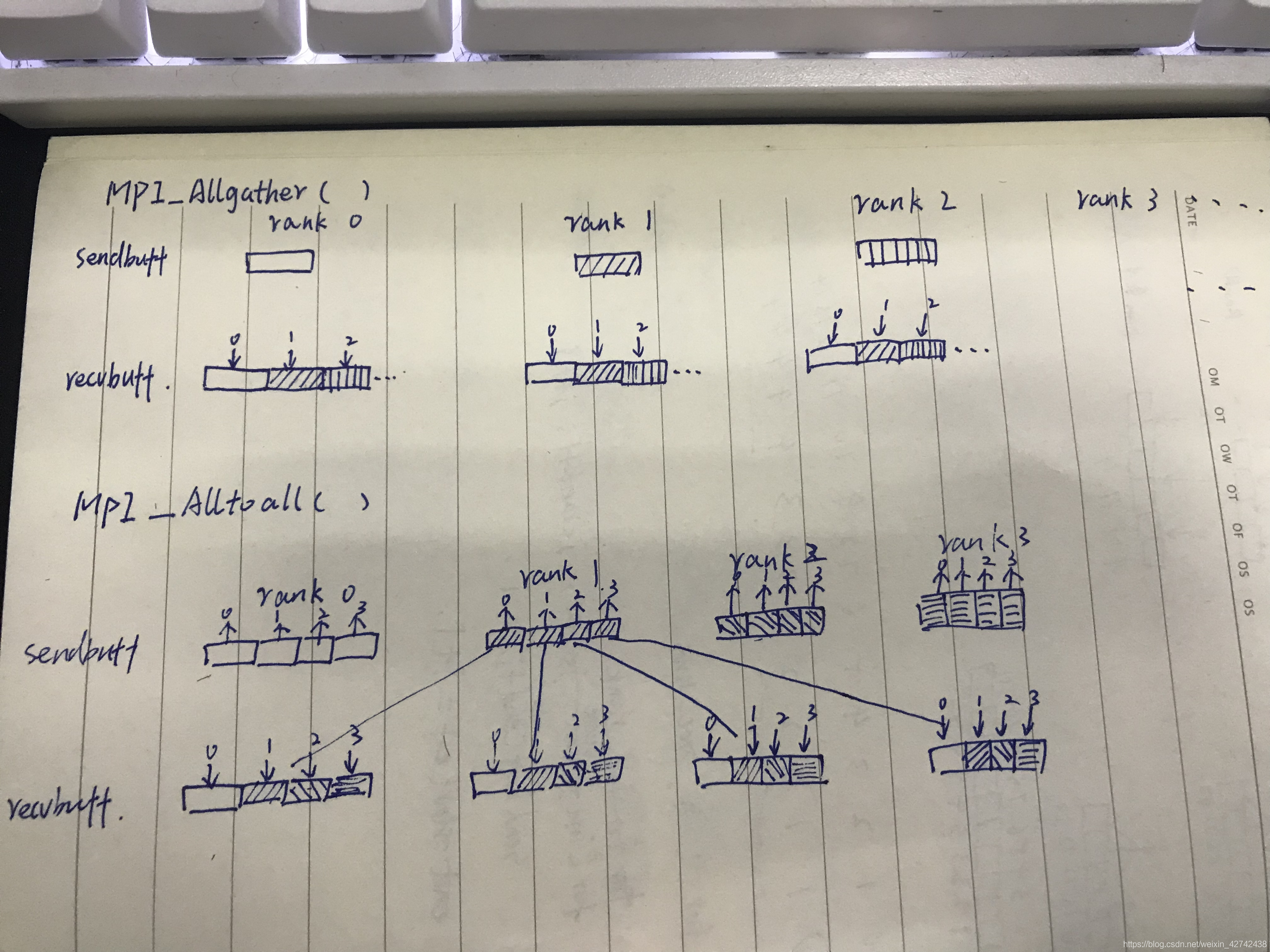
MPI_Alltoall与MPI_AllGahter相比较,区别在于:allgather操作中,不同进程向某一进程收集到的数据是完全相同的,而在alltoall中,不同的进程向某一进程收集到的数据是不同的。在每个进程的发送缓冲区中,为每个进程都单独准备了一块数据。
MPI_Alltoall(sendbuf,sendcount,sendtype,recvnbuf,recvcount,recvtype,comm);
在下面的例子中,我设置的数据块大小为10。每个进程发送缓冲区的内容定义如下:第i个进程发送缓冲区内第j块数据中的10个数据都为i*10+j。 若alltoall操作成功,则任意进程接收缓冲区内数据的十位应为0-proc_nums,个位应全为该进程的进程号。
#include<stdio.h>
#include"mpi.h"
#include"stdlib.h"
int main(int argc,char **argv)
{
int proc_nums,rank;
int block_size=10;//block_size<=10
int *send_buff;
int *recv_buff;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&proc_nums);
send_buff=(int *)malloc(block_size*proc_nums*sizeof(int));
recv_buff=(int *)malloc(block_size*proc_nums*sizeof(int));
for(int i=0;i<proc_nums;i++){
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









